

What Are AI Credits and How Can Data Scientists Use Them?
ODSC - Open Data Science
APRIL 23, 2025
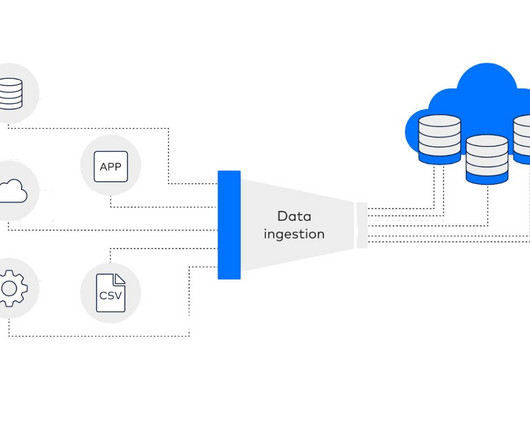
Confluent Confluent provides a robust data streaming platform built around Apache Kafka. Credits can be used to run Python functions in the cloud without infrastructure management, ideal for ETL jobs, ML inference, or batch processing.











Let's personalize your content