This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ApacheKafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. With ApacheKafka, developers can build applications that continuously use streaming data records and deliver real-time experiences to users. How does ApacheKafka work?
Be sure to check out his talk, “ ApacheKafka for Real-Time Machine Learning Without a Data Lake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the ApacheKafka ecosystem.
ApacheKafka is a well-known open-source event store and stream processing platform and has grown to become the de facto standard for data streaming. ApacheKafka transfers data without validating the information in the messages. Learn more about Kafka and its use cases here. What is a schema registry?
In the next sections of this blog, we will delve deeper into the technical aspects of Distributed Systems in Big Data Engineering, showcasing code snippets to illustrate how these systems work in practice. Clusters : Clusters are groups of interconnected nodes that work together to process and store data.
However, IBM MQ and ApacheKafka can sometimes be viewed as competitors, taking each other on in terms of speed, availability, cost and skills. MQ and ApacheKafka: Teammates Simply put, they are different technologies with different strengths, albeit often perceived to be quite similar. Interested in learning more?
They often use ApacheKafka as an open technology and the de facto standard for accessing events from a various core systems and applications. IBM provides an Event Streams capability build on ApacheKafka that makes events manageable across an entire enterprise.
If you have the Snowflake Data Cloud (or are considering migrating to Snowflake ), you’re a blog away from taking a step closer to real-time analytics. In this blog, we’ll show you step-by-step how to achieve real-time analytics with Snowflake via the Kafka Connector and Snowpipe. Looking for additional help?
To learn more, see the blog post , watch the introductory video , or see the documentation. To learn more about the beta offering, see Anomaly detection in streaming time series data with online learning using Amazon Managed Service for Apache Flink. How do I delete my Amazon Lookout for Metrics resources? Choose Delete.
ApacheKafka is a high-performance, highly scalable event streaming platform. To unlock Kafka’s full potential, you need to carefully consider the design of your application. It’s all too easy to write Kafka applications that perform poorly or eventually hit a scalability brick wall. So, what can you do?
m How it’s implemented In our quest to accurately determine shot speed during live matches, we’ve implemented a cutting-edge solution using Amazon Managed Streaming for ApacheKafka (Amazon MSK). Simultaneously, the shot speed data finds its way to a designated topic within our MSK cluster. km/h with a distance to goal of 20.61
With its intuitive UI, it makes it easy to produce a valid AsyncAPI document for any Kafkacluster or system that adheres to the ApacheKafka protocol. One of the key benefits of event endpoint management is that it allows you to describe events in a standardized way according to the AysncAPI specification.
In recognizing the benefits of event-driven architectures, many companies have turned to ApacheKafka for their event streaming needs. ApacheKafka enables scalable, fault-tolerant and real-time processing of streams of data—but how do you manage and properly utilize the sheer amount of data your business ingests every second?
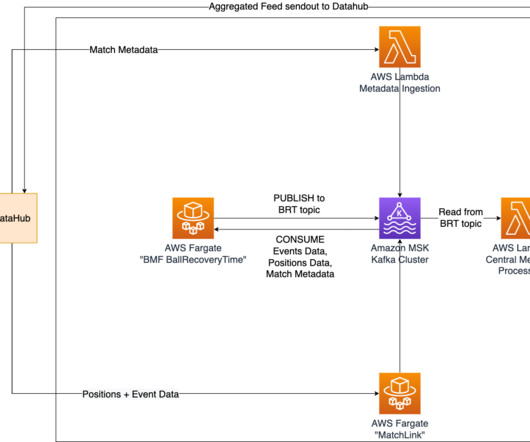
To ensure real-time updates of ball recovery times, we have implemented Amazon Managed Streaming for ApacheKafka (Amazon MSK) as a central solution for data streaming and messaging. Additionally, the ball recovery times are sent to a specific topic in the MSK cluster, where they can be accessed by other Bundesliga Match Facts.
This data proliferates across websites, blogs, and social media primarily via automated content creation, SEO-optimized spun text, chatbot interactions, and similar systems. For in depth knowledge, please refer to this blog post. Clustering: Clustering can group texts using features like embedding vectors or TF-IDF vectors.
This blog aims to provide a comprehensive overview of a typical Big Data syllabus, covering essential topics that aspiring data professionals should master. Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers.
This blog delves into the fundamentals of Apache NiFi, its architecture, and how it can leverage for effective data flow management. What is Apache NiFi? Apache NiFi is a robust data integration tool that facilitates the automation of data flows between different systems.
Typical examples include: Airbyte Talend ApacheKafkaApache Beam Apache Nifi While getting control over the process is an ideal position an organization wants to be in, the time and effort needed to build such systems are immense and frequently exceeds the license fee of a commercial offering. It connects to many DBs.
This blog will answer these questions by exploring the following: 1 What is pipeline architecture and design consideration, and what are the advantages of understanding it? ApacheKafka, Amazon Kinesis) 2 Data Preprocessing (e.g., References Netflix Tech Blog: Meson Workflow Orchestration for Netflix Recommendations Netflix.
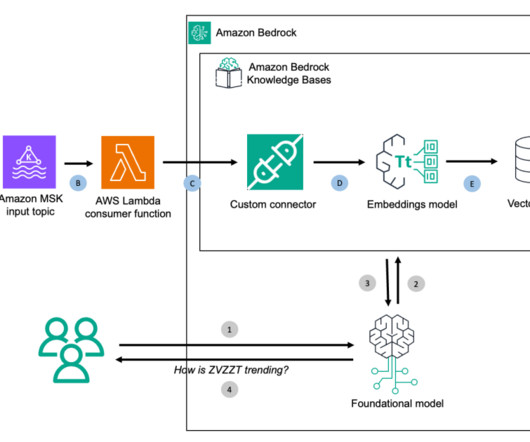
Solution overview: Build a generative AI stock price analyzer with RAG For this post, we implement a RAG architecture with Amazon Bedrock Knowledge Bases using a custom connector and topics built with Amazon Managed Streaming for ApacheKafka (Amazon MSK) for a user who may be interested to understand stock price trends.
Two of the most popular message brokers are RabbitMQ and ApacheKafka. In this blog, we will explore RabbitMQ vs Kafka, their key differences, and when to use each. RabbitMQ runs on multiple nodes in a cluster, ensuring high availability and system reliability. Where is RabbitMQ Used?
For the time being, we use Amazon EKS to offload the management overhead to AWS, but we could easily deploy on a standard Kubernetes cluster if needed. The resources in the Kubernetes cluster are deployed in a private subnet. It is backed by Amazon Managed Streaming for ApacheKafka (Amazon MSK) (8).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content