This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Be sure to check out his talk, “ ApacheKafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the ApacheKafka ecosystem.
You can safely use an ApacheKafkacluster for seamless data movement from the on-premise hardware solution to the datalake using various cloud services like Amazon’s S3 and others. 5 Key Comparisons in Different ApacheKafka Architectures. Step 2: Create a Data Catalog table.
Wednesday, June 14th Me, my health, and AI: applications in medical diagnostics and prognostics: Sara Khalid | Associate Professor, Senior Research Fellow, Biomedical Data Science and Health Informatics | University of Oxford Iterated and Exponentially Weighted Moving Principal Component Analysis : Dr. Paul A.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
Andre Franca | VP of Research and Development | causaLens Popular virtual sessions: AI and Bias: How to Detect It and How to Prevent It: Sandra Wachter, PhD | Professor, Technology and Regulation | Oxford Internet Institute, University of Oxford Probabilistic Machine Learning for Finance and Investing: Deepak Kanungo | Founder and CEO, Advisory Board (..)
The session participants will learn the theory behind compound sparsity, state-of-the-art techniques, and how to apply it in practice using the Neural Magic platform.
Flexibility : NiFi supports a wide range of data sources and formats, allowing organizations to integrate diverse systems and applications seamlessly. Scalability : NiFi can be deployed in a clustered environment, enabling organizations to scale their data processing capabilities as their data needs grow.
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, data warehouses, and datalakes.
Big Data Technologies and Tools A comprehensive syllabus should introduce students to the key technologies and tools used in Big Data analytics. Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers.
To combine the collected data, you can integrate different data producers into a datalake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the datalake.
Data engineers are responsible for designing and building the systems that make it possible to store, process, and analyze large amounts of data. These systems include data pipelines, data warehouses, and datalakes, among others. However, building and maintaining these systems is not an easy task.
Data Processing : You need to save the processed data through computations such as aggregation, filtering and sorting. Data Storage : To store this processed data to retrieve it over time – be it a data warehouse or a datalake. Server update locks the entire cluster.
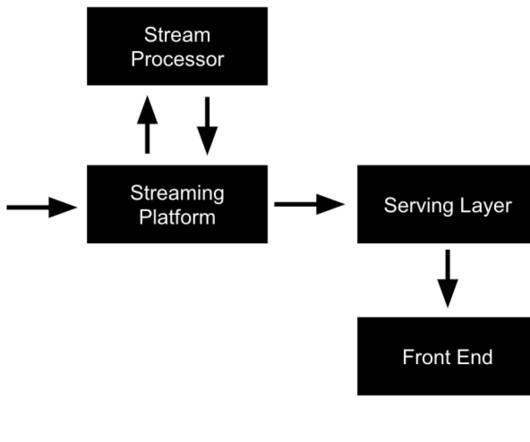
Building a Business with a Real-Time Analytics Stack, Streaming ML Without a DataLake, and Google’s PaLM 2 Building a Pizza Delivery Service with a Real-Time Analytics Stack The best businesses react quickly and with informed decisions. Here’s a use case of how you can use a real-time analytics stack to build a pizza delivery service.
Best Big Data Tools Popular tools such as Apache Hadoop, Apache Spark, ApacheKafka, and Apache Storm enable businesses to store, process, and analyse data efficiently. Key Features : Scalability : Hadoop can handle petabytes of data by adding more nodes to the cluster.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content