This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon. The post Introduction to ApacheKafka: Fundamentals and Working appeared first on Analytics Vidhya. All these sites use some event streaming tool to monitor user activities. […]. . […].
Introduction ApacheKafka is an open-source publish-subscribe messaging application initially developed by LinkedIn in early 2011. It is a famous Scala-coded data processing tool that offers low latency, extensive throughput, and a unified platform to handle the data in real-time.
Be sure to check out his talk, “ ApacheKafka for Real-Time Machine Learning Without a Data Lake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the ApacheKafka ecosystem.
Each node is capable of processing and storing data independently. Clusters : Clusters are groups of interconnected nodes that work together to process and store data. Clustering allows for improved performance and fault tolerance as tasks can be distributed across nodes.
ODSC Europe is next week, coming up June 14th-15th, and we can’t wait to bring the datascience community together, both in-person and virtually, to reconnect, learn, and grow. Our in-person passes are almost sold out, but don’t worry.
The week was filled with engaging sessions on top topics in datascience, innovation in AI, and smiling faces that we haven’t seen in a while. Expo Hall ODSC events are more than just datascience training and networking events. We’re a few weeks removed from ODSC Europe 2023 and we couldn’t have left on a better note.
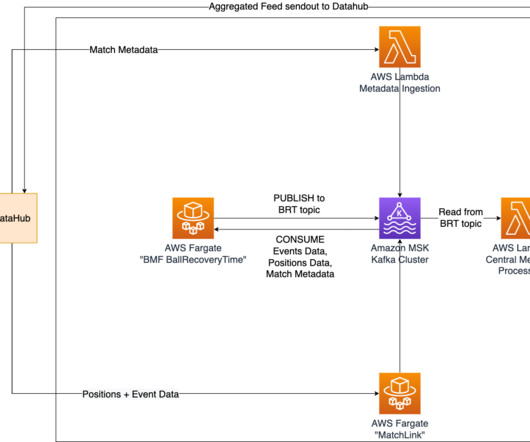
m How it’s implemented In our quest to accurately determine shot speed during live matches, we’ve implemented a cutting-edge solution using Amazon Managed Streaming for ApacheKafka (Amazon MSK). Simultaneously, the shot speed data finds its way to a designated topic within our MSK cluster.
Time Series Forecasting for Managers — All Forecasts Are Wrong but Some Are Useful Tanvir Ahmed Shaikh | Data Strategist (Director) | Genentech, Inc Time series forecasting remains an under-appreciated technique in datascience education, often overshadowed by more popular machine learning methods.
How it’s implemented Positional data from an ongoing match, which is recorded at a sampling rate of 25 Hz, is utilized to determine the time taken to recover the ball. This allows for seamless communication of positional data and various outputs of Bundesliga Match Facts between containers in real time.
Additionally, Data Engineers implement quality checks, monitor performance, and optimise systems to handle large volumes of data efficiently. Differences Between Data Engineering and DataScience While Data Engineering and DataScience are closely related, they focus on different aspects of data.
Image generated with Midjourney In today’s fast-paced world of datascience, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust data pipelines.
Key Takeaways Big Data originates from diverse sources, including IoT and social media. Data lakes and cloud storage provide scalable solutions for large datasets. Processing frameworks like Hadoop enable efficient data analysis across clusters. What is Big Data?
Big Data Technologies and Tools A comprehensive syllabus should introduce students to the key technologies and tools used in Big Data analytics. Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers.
Some of these solutions include: Distributed computing: Distributed computing systems, such as Hadoop and Spark, can help distribute the processing of data across multiple nodes in a cluster. This approach allows for faster and more efficient processing of large volumes of data.
Top 15 Data Analytics Projects in 2023 for Beginners to Experienced Levels: Data Analytics Projects allow aspirants in the field to display their proficiency to employers and acquire job roles. Implement real-time analytics to monitor trends or anomalies in the data.
Streaming Machine Learning Without a Data Lake The combination of data streaming and ML enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the ApacheKafka ecosystem. Here’s why. Register for free!
For the time being, we use Amazon EKS to offload the management overhead to AWS, but we could easily deploy on a standard Kubernetes cluster if needed. The resources in the Kubernetes cluster are deployed in a private subnet. It is backed by Amazon Managed Streaming for ApacheKafka (Amazon MSK) (8).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






















Let's personalize your content