This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Be sure to check out his talk, “ ApacheKafka for Real-Time MachineLearning Without a Data Lake ,” there! The combination of data streaming and machinelearning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machinelearning tasks using the ApacheKafka ecosystem.
Within this article, we will explore the significance of these pipelines and utilise robust tools such as ApacheKafka and Spark to manage vast streams of data efficiently. ApacheKafkaApacheKafka is a distributed event streaming platform used for building real-time data pipelines and streaming applications.
Key components of distributed systems Nodes : Nodes are individual machines or servers that form the building blocks of a distributed system. Clusters : Clusters are groups of interconnected nodes that work together to process and store data. Each node is capable of processing and storing data independently.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
Image generated with Midjourney In today’s fast-paced world of data science, building impactful machinelearning models relies on much more than selecting the best algorithm for the job. Data scientists and machinelearning engineers need to collaborate to make sure that together with the model, they develop robust data pipelines.
In today's data-driven world, machinelearning practitioners often face a critical yet underappreciated challenge: duplicate data management. This article is an attempt to delve into how duplicate data can affect machinelearning models, and how it impacts their accuracy and other performance metrics.
Amazon Lookout for Metrics is a fully managed service that uses machinelearning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required. Choose Delete.
Bilokon | Visiting Lecturer, CEO and Founder | Imperial College London, Thalesians Ltd ApacheKafka for Real-Time MachineLearning Without a Data Lake: Kai Waehner | Global Field CTO, Author, International Speaker Semantic Analysis and Procedural Language Understanding in the Era of Large Language Models: Dr. Gözde Gül Şahin | Assistant Professor, (..)
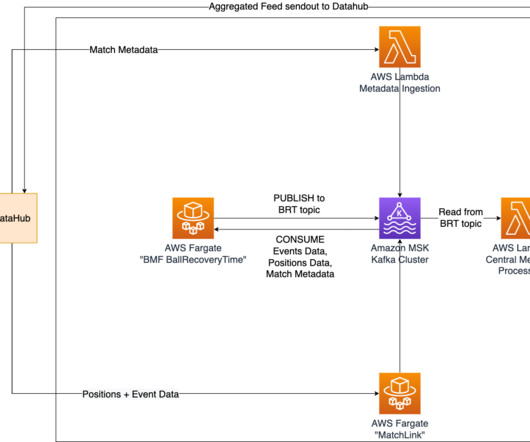
To ensure real-time updates of ball recovery times, we have implemented Amazon Managed Streaming for ApacheKafka (Amazon MSK) as a central solution for data streaming and messaging. Additionally, the ball recovery times are sent to a specific topic in the MSK cluster, where they can be accessed by other Bundesliga Match Facts.
m How it’s implemented In our quest to accurately determine shot speed during live matches, we’ve implemented a cutting-edge solution using Amazon Managed Streaming for ApacheKafka (Amazon MSK). Simultaneously, the shot speed data finds its way to a designated topic within our MSK cluster. km/h with a distance to goal of 20.61
Managing unstructured data is essential for the success of machinelearning (ML) projects. ApacheKafkaApacheKafka is a distributed event streaming platform for real-time data pipelines and stream processing. Kafka is highly scalable and ideal for high-throughput and low-latency data pipeline applications.
AI and Bias: How to Detect It and How to Prevent It Sandra Wachter, PhD | Professor, Technology and Regulation | Oxford Internet Institute, University of Oxford In recognition of the extensive biases and inequality that are present in training data, there has been much work done to test for bias in machinelearning and AI systems.
Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers. Data Streaming Learning about real-time data collection methods using tools like ApacheKafka and Amazon Kinesis.
Some of these solutions include: Distributed computing: Distributed computing systems, such as Hadoop and Spark, can help distribute the processing of data across multiple nodes in a cluster. This approach allows for faster and more efficient processing of large volumes of data.
On the other hand, Data Science involves extracting insights and knowledge from data using Statistical Analysis, MachineLearning, and other techniques. Among these tools, Apache Hadoop, Apache Spark, and ApacheKafka stand out for their unique capabilities and widespread usage.
Processing frameworks like Hadoop enable efficient data analysis across clusters. Apache Spark: A fast processing engine that supports both batch and real-time analytics, making it suitable for a wide range of applications. Key Takeaways Big Data originates from diverse sources, including IoT and social media. What is Big Data?
Processing frameworks like Hadoop enable efficient data analysis across clusters. Apache Spark: A fast processing engine that supports both batch and real-time analytics, making it suitable for a wide range of applications. Key Takeaways Big Data originates from diverse sources, including IoT and social media. What is Big Data?
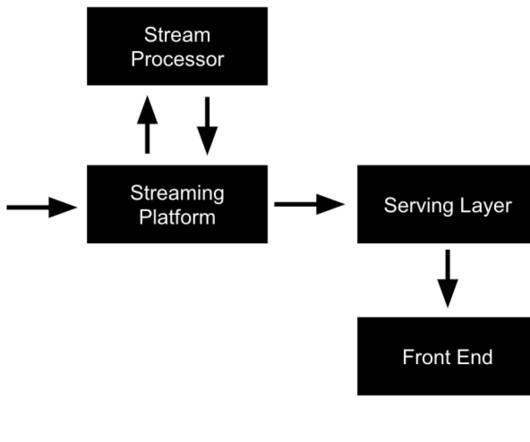
The events can be published to a message broker such as ApacheKafka or Google Cloud Pub/Sub. The message broker can then distribute the events to various subscribers such as data processing pipelines, machinelearning models, and real-time analytics dashboards.
Techniques like regression analysis, time series forecasting, and machinelearning algorithms are used to predict customer behavior, sales trends, equipment failure, and more. Use machinelearning algorithms to build a fraud detection model and identify potentially fraudulent transactions.
Typical examples include: Airbyte Talend ApacheKafkaApache Beam Apache Nifi While getting control over the process is an ideal position an organization wants to be in, the time and effort needed to build such systems are immense and frequently exceeds the license fee of a commercial offering. It connects to many DBs.
Streaming MachineLearning Without a Data Lake The combination of data streaming and ML enables you to build one scalable, reliable, but also simple infrastructure for all machinelearning tasks using the ApacheKafka ecosystem. Here’s why.
Many questions regarding building machinelearning pipelines and systems have already been answered and come from industry best practices and patterns. How should the machinelearning pipeline operate? These stages are primarily considered in the domain of MLOps (machinelearning operations).
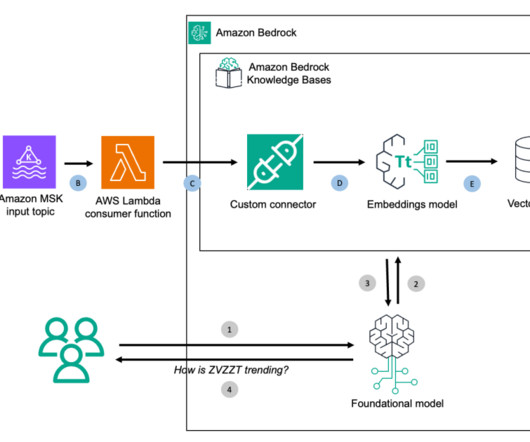
Solution overview: Build a generative AI stock price analyzer with RAG For this post, we implement a RAG architecture with Amazon Bedrock Knowledge Bases using a custom connector and topics built with Amazon Managed Streaming for ApacheKafka (Amazon MSK) for a user who may be interested to understand stock price trends.
Best Big Data Tools Popular tools such as Apache Hadoop, Apache Spark, ApacheKafka, and Apache Storm enable businesses to store, process, and analyse data efficiently. It is designed to scale up from a single server to thousands of machines. Statistics Kafka handles over 1.1
However, it lacked essential services required for machinelearning (ML) applications, such as frontend and backend infrastructure, DNS, load balancers, scaling, blob storage, and managed databases. At that time, the application was deployed as a single monolithic container, which included Kafka and a database.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content