This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Be sure to check out his talk, “ ApacheKafka for Real-Time Machine Learning Without a Data Lake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the ApacheKafka ecosystem.
Amazon Lookout for Metrics is a fully managed service that uses machine learning (ML) to detect anomalies in virtually any time-series business or operational metrics—such as revenue performance, purchase transactions, and customer acquisition and retention rates—with no ML experience required. To learn more, see the documentation.
Building a Business with a Real-Time Analytics Stack, Streaming ML Without a Data Lake, and Google’s PaLM 2 Building a Pizza Delivery Service with a Real-Time Analytics Stack The best businesses react quickly and with informed decisions. Here’s a use case of how you can use a real-time analytics stack to build a pizza delivery service.
Wednesday, June 14th Me, my health, and AI: applications in medical diagnostics and prognostics: Sara Khalid | Associate Professor, Senior Research Fellow, Biomedical Data Science and Health Informatics | University of Oxford Iterated and Exponentially Weighted Moving Principal Component Analysis : Dr. Paul A.
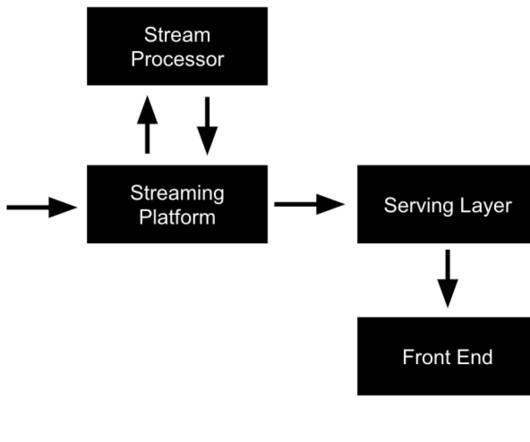
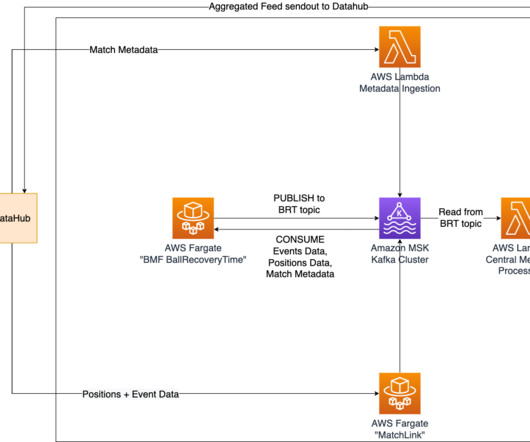
m How it’s implemented In our quest to accurately determine shot speed during live matches, we’ve implemented a cutting-edge solution using Amazon Managed Streaming for ApacheKafka (Amazon MSK). Simultaneously, the shot speed data finds its way to a designated topic within our MSK cluster. km/h with a distance to goal of 20.61
These pipelines cover the entire lifecycle of an ML project, from data ingestion and preprocessing, to model training, evaluation, and deployment. Adopted from [link] In this article, we will first briefly explain what ML workflows and pipelines are. around the world to streamline their data and ML pipelines.
Probabilistic Machine Learning for Finance and Investing Deepak Kanungo | Founder and CEO, Advisory Board Member | Hedged Capital LLC, AIKON This session will introduce you to the reasons why probabilistic machine learning is the next generation of AI in finance and investing.
Some of our most popular in-person sessions were: Data Communication in the Age of AI: Alan Rutter | Founder | Fire Plus Algebra Autoencoders — a Magical Approach to Unsupervised Machine Learning: Oliver Zeigermann | Blue Collar ML Architect | Freelancer Fast Option Pricing Using Deep Learning Methods: Chakri Cherukuri | Senior Quantitative Researcher (..)
To ensure real-time updates of ball recovery times, we have implemented Amazon Managed Streaming for ApacheKafka (Amazon MSK) as a central solution for data streaming and messaging. Additionally, the ball recovery times are sent to a specific topic in the MSK cluster, where they can be accessed by other Bundesliga Match Facts.
A massive amount of diverse data powers today's ML models. Clustering: Clustering can group texts using features like embedding vectors or TF-IDF vectors. Duplicate texts naturally tend to fall into the same clusters. Hashing, vector embeddings, clustering, etc are widely used in image deduplication as well.
Managing unstructured data is essential for the success of machine learning (ML) projects. This article will discuss managing unstructured data for AI and ML projects. You will learn the following: Why unstructured data management is necessary for AI and ML projects. How to properly manage unstructured data.
The events can be published to a message broker such as ApacheKafka or Google Cloud Pub/Sub. Hadoop provides a MapReduce implementation that allows developers to write applications that process large amounts of data in parallel across a cluster of commodity hardware.
A typical data pipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process. If a typical ML project involves standard pre-processing steps – why not make it reusable? Server update locks the entire cluster.
There comes a time when every ML practitioner realizes that training a model in Jupyter Notebook is just one small part of the entire project. At that point, the Data Scientists or ML Engineers become curious and start looking for such implementations. What are ML pipeline architecture design patterns?
Best Big Data Tools Popular tools such as Apache Hadoop, Apache Spark, ApacheKafka, and Apache Storm enable businesses to store, process, and analyse data efficiently. Key Features : Scalability : Hadoop can handle petabytes of data by adding more nodes to the cluster. Statistics Kafka handles over 1.1
However, it lacked essential services required for machine learning (ML) applications, such as frontend and backend infrastructure, DNS, load balancers, scaling, blob storage, and managed databases. At that time, the application was deployed as a single monolithic container, which included Kafka and a database.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content