

Streaming Machine Learning Without a Data Lake
ODSC - Open Data Science
MAY 31, 2023
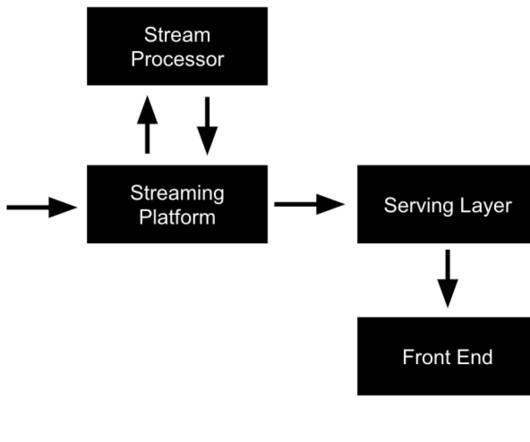
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a Data Lake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.



















Let's personalize your content