This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Be sure to check out his talk, “ ApacheKafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the ApacheKafka ecosystem.
Building a Business with a Real-Time Analytics Stack, Streaming ML Without a DataLake, and Google’s PaLM 2 Building a Pizza Delivery Service with a Real-Time Analytics Stack The best businesses react quickly and with informed decisions.
In this post, we demonstrate how to build a robust real-time anomaly detection solution for streaming time series data using Amazon Managed Service for Apache Flink and other AWS managed services. This solution employs machine learning (ML) for anomaly detection, and doesn’t require users to have prior AI expertise.
Wednesday, June 14th Me, my health, and AI: applications in medical diagnostics and prognostics: Sara Khalid | Associate Professor, Senior Research Fellow, Biomedical Data Science and Health Informatics | University of Oxford Iterated and Exponentially Weighted Moving Principal Component Analysis : Dr. Paul A.
Time Series Forecasting for Managers — All Forecasts Are Wrong but Some Are Useful Tanvir Ahmed Shaikh | Data Strategist (Director) | Genentech, Inc Time series forecasting remains an under-appreciated technique in data science education, often overshadowed by more popular machine learning methods.
Some of our most popular in-person sessions were: Data Communication in the Age of AI: Alan Rutter | Founder | Fire Plus Algebra Autoencoders — a Magical Approach to Unsupervised Machine Learning: Oliver Zeigermann | Blue Collar ML Architect | Freelancer Fast Option Pricing Using Deep Learning Methods: Chakri Cherukuri | Senior Quantitative Researcher (..)
The result is a machine learning (ML)-powered insight that allows fans to easily evaluate and compare the goalkeepers’ proficiencies. An ML model is trained through Amazon SageMaker , using data from four seasons of the first and second Bundesliga, encompassing all shots that landed on target (either resulting in a goal or being saved).
Managing unstructured data is essential for the success of machine learning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. This article will discuss managing unstructured data for AI and ML projects. What is Unstructured Data?
Common options include: Relational Databases: Structured storage supporting ACID transactions, suitable for structured data. NoSQL Databases: Flexible, scalable solutions for unstructured or semi-structured data. Data Warehouses : Centralised repositories optimised for analytics and reporting.
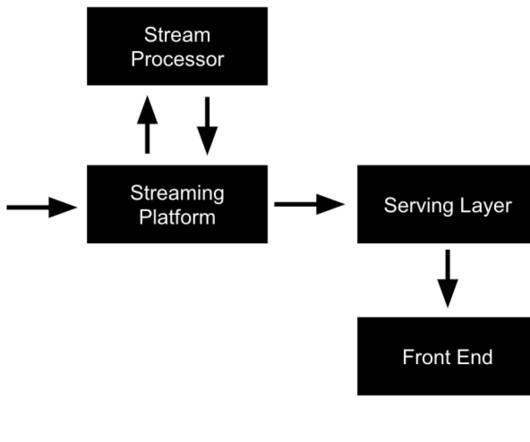
Data pipeline stages But before delving deeper into the technical aspects of these tools, let’s quickly understand the core components of a data pipeline succinctly captured in the image below: Data pipeline stages | Source: Author What does a good data pipeline look like?
Technologies like ApacheKafka, often used in modern CDPs, use log-based approaches to stream customer events between systems in real-time. Both persistent staging and datalakes involve storing large amounts of raw data. These changes are streamed into Iceberg tables in your datalake.
And where data was available, the ability to access and interpret it proved problematic. Big data can grow too big fast. Left unchecked, datalakes became data swamps. Some datalake implementations required expensive ‘cleansing pumps’ to make them navigable again.
Best Big Data Tools Popular tools such as Apache Hadoop, Apache Spark, ApacheKafka, and Apache Storm enable businesses to store, process, and analyse data efficiently. Key Features : Integration with Microsoft Services : Seamlessly integrates with other Azure services like Azure DataLake Storage.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




















Let's personalize your content