This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the DataScience Blogathon. Introduction The big data industry is growing daily and needs tools to process vast volumes of data. That’s why you need to know about ApacheKafka, a publish-subscribe messaging system you can use to build distributed applications.
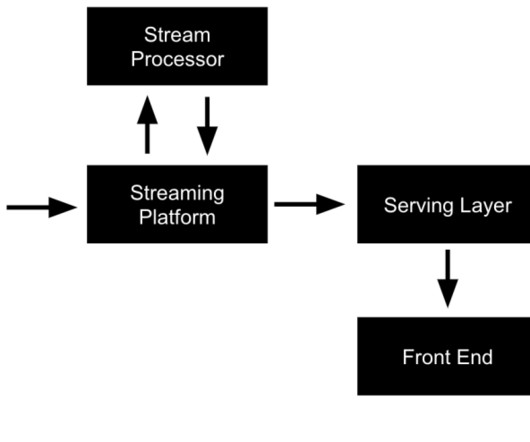
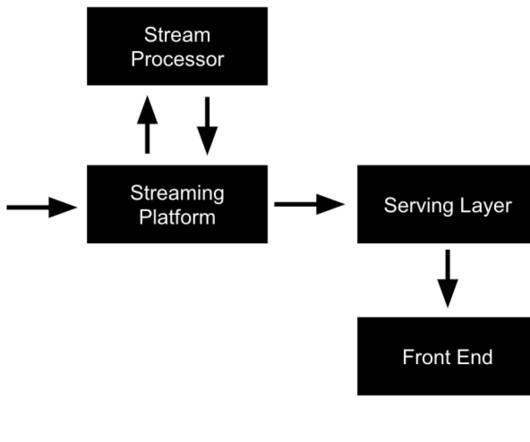
This article was published as a part of the DataScience Blogathon. Introduction When we mention BigData, one of the types of data usually talked about is the Streaming Data. Streaming Data is generated continuously, by multiple data sources say, sensors, server logs, stock prices, etc.
This article was published as a part of the DataScience Blogathon. The post ApacheKafka Use Cases and Installation Guide appeared first on Analytics Vidhya. Introduction Today, we expect web applications to respond to user queries quickly, if not immediately.
This article was published as a part of the DataScience Blogathon. The post Introduction to ApacheKafka: Fundamentals and Working appeared first on Analytics Vidhya. All these sites use some event streaming tool to monitor user activities. […]. . […].
This article was published as a part of the DataScience Blogathon. Introduction Earlier, I had introduced basic concepts of ApacheKafka in my blog on Analytics Vidhya(link is available under references). The post Exploring Partitions and Consumer Groups in ApacheKafka appeared first on Analytics Vidhya.
Introduction ApacheKafka is an open-source publish-subscribe messaging application initially developed by LinkedIn in early 2011. It is a famous Scala-coded data processing tool that offers low latency, extensive throughput, and a unified platform to handle the data in real-time.
Overview There are a plethora of datascience tools out there – which one should you pick up? The post 22 Widely Used DataScience and Machine Learning Tools in 2020 appeared first on Analytics Vidhya. Here’s a list of over 20.
This article was published as a part of the DataScience Blogathon. Dale Carnegie” ApacheKafka is a Software Framework for storing, reading, and analyzing streaming data. Introduction “Learning is an active process. We learn by doing. Only knowledge that is used sticks in your mind.-
Data processing today is done in form of pipelines which include various steps like aggregation, sanitization, filtering and finally generating insights by applying various statistical models. Amazon Kinesis is a platform to build pipelines for streaming data at the scale of terabytes per hour. Parts of the Kinesis platform are.
DataScience Dojo is offering Memphis broker for FREE on Azure Marketplace preconfigured with Memphis, a platform that provides a P2P architecture, scalability, storage tiering, fault-tolerance, and security to provide real-time processing for modern applications suitable for large volumes of data. Are you already feeling tired?
It allows your business to ingest continuous data streams as they happen and bring them to the forefront for analysis, enabling you to keep up with constant changes. ApacheKafka boasts many strong capabilities, such as delivering a high throughput and maintaining a high fault tolerance in the case of application failure.
Be sure to check out his talk, “ ApacheKafka for Real-Time Machine Learning Without a Data Lake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the ApacheKafka ecosystem.
Summary: The future of DataScience is shaped by emerging trends such as advanced AI and Machine Learning, augmented analytics, and automated processes. As industries increasingly rely on data-driven insights, ethical considerations regarding data privacy and bias mitigation will become paramount.
We’re going to assume that the pizza service already captures orders in ApacheKafka and is also keeping a record of its customers and the products that they sell in MySQL. Apache Pinot is a real-time OLAP database built at LinkedIn to deliver scalable real-time analytics with low latency. He tweets at @markhneedham.
This architectural concept relies on event streaming as the core element of data delivery. In practical implementation, the Kappa architecture is commonly deployed using ApacheKafka or Kafka-based tools. Applications can directly read from and write to Kafka or an alternative message queue tool.
Internet of Things (IoT) Data Processing: Stream processing is vital for handling continuous data streams from IoT devices, enabling real-time monitoring and control.
Spark offers a versatile range of functionalities, from batch processing to stream processing, making it a comprehensive solution for complex data challenges. ApacheKafka For data engineers dealing with real-time data, ApacheKafka is a game-changer.
ODSC Europe is next week, coming up June 14th-15th, and we can’t wait to bring the datascience community together, both in-person and virtually, to reconnect, learn, and grow. Our in-person passes are almost sold out, but don’t worry.
The week was filled with engaging sessions on top topics in datascience, innovation in AI, and smiling faces that we haven’t seen in a while. Expo Hall ODSC events are more than just datascience training and networking events. We’re a few weeks removed from ODSC Europe 2023 and we couldn’t have left on a better note.
Streaming Machine Learning Without a Data Lake The combination of data streaming and ML enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the ApacheKafka ecosystem. Here’s why. Register for free!
Time Series Forecasting for Managers — All Forecasts Are Wrong but Some Are Useful Tanvir Ahmed Shaikh | Data Strategist (Director) | Genentech, Inc Time series forecasting remains an under-appreciated technique in datascience education, often overshadowed by more popular machine learning methods.
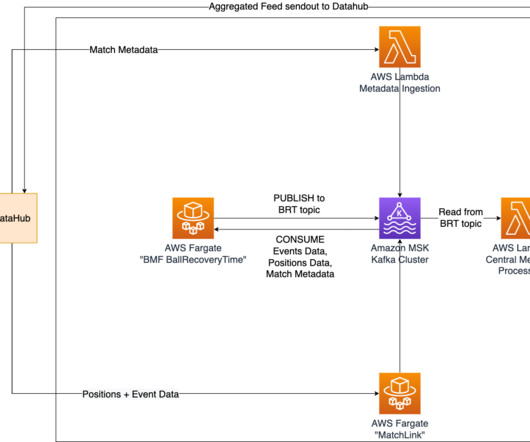
m How it’s implemented In our quest to accurately determine shot speed during live matches, we’ve implemented a cutting-edge solution using Amazon Managed Streaming for ApacheKafka (Amazon MSK). His skills and areas of expertise include application development, datascience, and machine learning (ML).
Streaming ingestion – An Amazon Kinesis Data Analytics for Apache Flink application backed by ApacheKafka topics in Amazon Managed Streaming for ApacheKafka (MSK) (Amazon MSK) calculates aggregated features from a transaction stream, and an AWS Lambda function updates the online feature store.
How it’s implemented Positional data from an ongoing match, which is recorded at a sampling rate of 25 Hz, is utilized to determine the time taken to recover the ball. This allows for seamless communication of positional data and various outputs of Bundesliga Match Facts between containers in real time.
Spark, Tensorflow, ApacheKafka, et cetera, are all out found in cloud databases,” points out Jones. “File-based storage of data is the norm even under more relational models. [In “Big data added agility into a managed platform in a way that old school data warehouses just couldn’t,” stresses Jones.
Data at Rest This includes storage solutions such as S3 Data Warehouse and Cassandra. These systems handle the storage costs associated with keeping vast amounts of content and user data. What Technologies Does Netflix Use for Its Big Data Infrastructure? How Does Netflix Ensure Security Against Fraud?
For every xSaves prediction, it produces a message with the prediction as a payload, which then gets distributed by a central message broker running on Amazon Managed Streaming for ApacheKafka (Amazon MSK). The information also gets stored in a data lake for future auditing and model improvements.
Additionally, Data Engineers implement quality checks, monitor performance, and optimise systems to handle large volumes of data efficiently. Differences Between Data Engineering and DataScience While Data Engineering and DataScience are closely related, they focus on different aspects of data.
Image generated with Midjourney In today’s fast-paced world of datascience, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust data pipelines.
In response, Twitter has implemented various solutions, including ApacheKafka, a distributed streaming platform that helps manage the data flow from user interactions. Using Kafka, Twitter can effectively handle high-throughput data streams, enabling users to receive timely notifications and updates.
Solutions for managing and processing high velocity dataData engineers can use various solutions to manage and process high-speed data streams. Some of these solutions include: Stream processing: Stream processing systems, such as ApacheKafka and Apache Flink, can help process high-speed data streams in real-time.
ApacheKafka and R abbitMQ are particularly popular in LEs. Graph 7: Percentage of Programming Languages MiscTech Tools In Both LEs and SMEs: ‘. NET (5+) ’, ‘ pandas ’, ‘ numpy ’, and ‘. NET Framework (1.0–4.8)’ 4.8)’ are widely used.
Real-time processing allows organisations to make timely decisions based on current data rather than relying on historical information.Technologies enabling real-time analytics include: Stream Processing Frameworks: Tools like ApacheKafka facilitate the continuous ingestion and processing of streaming data.
Top 15 Data Analytics Projects in 2023 for Beginners to Experienced Levels: Data Analytics Projects allow aspirants in the field to display their proficiency to employers and acquire job roles. Implement real-time analytics to monitor trends or anomalies in the data.
Streaming Data Ingestion: Managing and processing data streams is the focus of streaming data ingestion, which was created expressly for this purpose. IoT applications, log processing, and other data-intensive scenarios frequently use this kind of ingestion.
Tools and Technologies to Minimise Latency and Optimise Performance Minimising latency is crucial for real-time data processing. Utilise in-memory data processing tools like ApacheKafka and Apache Flink, which provide low-latency data ingestion and processing capabilities.
APIs Understanding how to interact with Application Programming Interfaces (APIs) to gather data from external sources. Data Streaming Learning about real-time data collection methods using tools like ApacheKafka and Amazon Kinesis. Once data is collected, it needs to be stored efficiently.
Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Learning these tools is crucial for building scalable data pipelines. offers DataScience courses covering these tools with a job guarantee for career growth. How is Data Engineering Different from DataScience?
It is backed by Amazon Managed Streaming for ApacheKafka (Amazon MSK) (8). The next important step is to use these model results with proper analytics and datascience. These results can also serve as a data source for generative AI features such as automated report generation.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content