This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
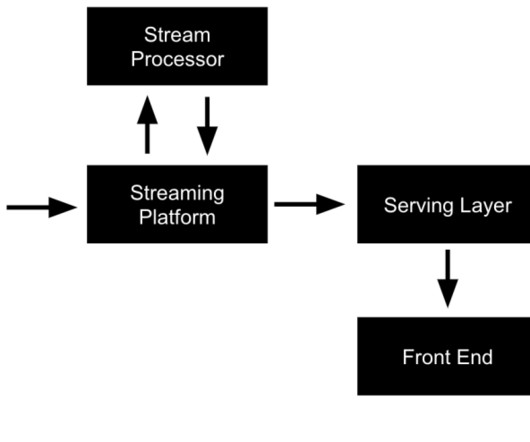
Refer to Unlocking the Power of Big Data Article to understand the use case of these data collected from various sources. Data Ingestion: Data is collected and funneled into the pipeline using batch or real-time methods, leveraging tools like ApacheKafka, AWS Kinesis, or custom ETL scripts.
Spark offers a versatile range of functionalities, from batch processing to stream processing, making it a comprehensive solution for complex data challenges. ApacheKafka For data engineers dealing with real-time data, ApacheKafka is a game-changer.
We’re going to assume that the pizza service already captures orders in ApacheKafka and is also keeping a record of its customers and the products that they sell in MySQL. Apache Pinot is a real-time OLAP database built at LinkedIn to deliver scalable real-time analytics with low latency.
APIs Understanding how to interact with Application Programming Interfaces (APIs) to gather data from external sources. Data Streaming Learning about real-time data collection methods using tools like ApacheKafka and Amazon Kinesis. Once data is collected, it needs to be stored efficiently.
Descriptive Analytics Projects: These projects focus on summarizing historical data to gain insights into past trends and patterns. Examples include generating reports, dashboards, and datavisualizations to understand business performance, customer behavior, or operational efficiency.
Real-Time Data Processing The demand for real-time analytics is growing as businesses seek immediate insights to drive decision-making. ApacheKafka), organisations can now analyse vast amounts of data as it is generated. Master DataVisualization Techniques Datavisualization is key to effectively communicating insights.
Python, SQL, and Apache Spark are essential for data engineering workflows. Real-time data processing with ApacheKafka enables faster decision-making. offers Data Science courses covering essential data tools with a job guarantee. The global Big Data and data engineering market, valued at $75.55
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













Let's personalize your content