This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Dale Carnegie” ApacheKafka is a Software Framework for storing, reading, and analyzing streaming data. This article was published as a part of the Data Science Blogathon. Introduction “Learning is an active process. We learn by doing. Only knowledge that is used sticks in your mind.-
At the forefront of this event-driven revolution is ApacheKafka, the widely recognized and dominant open-source technology for event streaming. It offers businesses the capability to capture and process real-time information from diverse sources, such as databases, software applications and cloud services.
ApacheKafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. With ApacheKafka, developers can build applications that continuously use streaming data records and deliver real-time experiences to users. How does ApacheKafka work?
Be sure to check out his talk, “ ApacheKafka for Real-Time Machine Learning Without a Data Lake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the ApacheKafka ecosystem.
Within this article, we will explore the significance of these pipelines and utilise robust tools such as ApacheKafka and Spark to manage vast streams of data efficiently. ApacheKafkaApacheKafka is a distributed event streaming platform used for building real-time data pipelines and streaming applications.
ApacheKafka is a well-known open-source event store and stream processing platform and has grown to become the de facto standard for data streaming. ApacheKafka transfers data without validating the information in the messages. Optimize your Kafka environment by using a schema registry.
Overview There are a plethora of data science tools out there – which one should you pick up? Here’s a list of over 20. The post 22 Widely Used Data Science and Machine Learning Tools in 2020 appeared first on Analytics Vidhya.
Summary: This article highlights the significance of Database Management Systems in social media giants, focusing on their functionality, types, challenges, and future trends that impact user experience and data management. It is an intermediary between users and the database, allowing for efficient data storage, retrieval, and management.
Its characteristics can be summarized as follows: Volume : Big Data involves datasets that are too large to be processed by traditional database management systems. databases), semi-structured data (e.g., These datasets can range from terabytes to petabytes and beyond. XML, JSON), and unstructured data (e.g., text, images, videos).
In practical implementation, the Kappa architecture is commonly deployed using ApacheKafka or Kafka-based tools. Applications can directly read from and write to Kafka or an alternative message queue tool. This approach eliminates the need for inbound batch processing and reduces resource requirements.
Components of a Big Data Pipeline Data Sources (Collection): Data originates from various sources, such as databases, APIs, and log files. Examples include transactional databases, social media feeds, and IoT sensors. This phase ensures quality and consistency using frameworks like Apache Spark or AWS Glue.
One very popular platform is ApacheKafka , a powerful open-source tool used by thousands of companies. But in all likelihood, Kafka doesn’t natively connect with the applications that contain your data. In addition, you’ll also need a NoSQL database (many people use HBase, but you have a variety of choices available).
How Snowflake Helps Achieve Real-Time Analytics Snowflake is the ideal platform to achieve real-time analytics for several reasons, but two of the biggest are its ability to manage concurrency due to the multi-cluster architecture of Snowflake and its robust connections to 3rd party tools like Kafka. p8 -pubout -out C:tmpnew_rsa_key_v1.pub
The unique advantages of Apache Flink Apache Flink augments event streaming technologies like ApacheKafka to enable businesses to respond to events more effectively in real time. Integration: Integrates seamlessly with other data systems and platforms, including ApacheKafka, Spark, Hadoop and various databases.
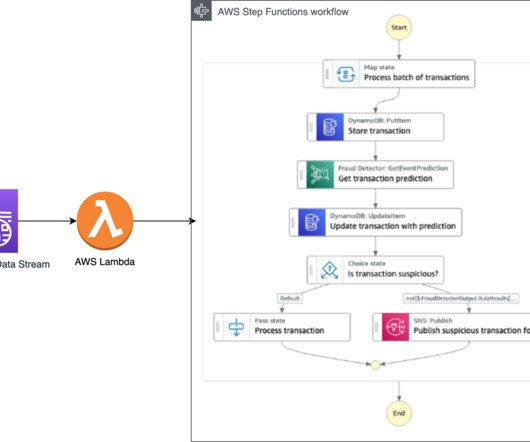
The same architecture applies if you use Amazon Managed Streaming for ApacheKafka (Amazon MSK) as a data streaming service. This approach allows you to react to the potentially fraudulent transactions in real time as you store each transaction in a database and inspect it before processing further.
New Big Data Concepts vs Cloud Delivered Databases? So, what has the emergence of cloud databases done to change big data? Spark, Tensorflow, ApacheKafka, et cetera, are all out found in cloud databases,” points out Jones. How do we use it to transform a legacy business into a competitive one?
We’re going to assume that the pizza service already captures orders in ApacheKafka and is also keeping a record of its customers and the products that they sell in MySQL. This all looks like it’s working well, so let’s look at how to ingest those events into Apache Pinot.
It initially sources input time series data from Amazon Managed Streaming for ApacheKafka (Amazon MSK) using this live stream for model training. Conclusion This post demonstrated how to build a robust real-time anomaly detection solution for streaming time series data using Managed Service for Apache Flink and other AWS services.
From extracting information from databases and spreadsheets to ingesting streaming data from IoT devices and social media platforms, It’s the foundation upon which data-driven initiatives are built. ApacheKafka An open-source platform designed for real-time data streaming. Data Lakes allow for flexible analysis.
IBM Event Automation is a fully composable solution, built on open technologies, with capabilities for: Event streaming : Collect and distribute raw streams of real-time business events with enterprise-grade ApacheKafka. Event endpoint management : Describe and document events easily according to the Async API specification.
Streaming ingestion – An Amazon Kinesis Data Analytics for Apache Flink application backed by ApacheKafka topics in Amazon Managed Streaming for ApacheKafka (MSK) (Amazon MSK) calculates aggregated features from a transaction stream, and an AWS Lambda function updates the online feature store.
m How it’s implemented In our quest to accurately determine shot speed during live matches, we’ve implemented a cutting-edge solution using Amazon Managed Streaming for ApacheKafka (Amazon MSK). We’ve implemented an AWS Lambda function with the specific task of retrieving the calculated shot speed from the relevant Kafka topic.
Data in Motion Technologies like ApacheKafka facilitate real-time processing of events and data, allowing Netflix to respond swiftly to user interactions and operational needs. Data at Rest This includes storage solutions such as S3 Data Warehouse and Cassandra. What Technologies Does Netflix Use for Its Big Data Infrastructure?
Variety Data comes in multiple forms, from highly organised databases to messy, unstructured formats like videos and social media text. Structured data is organised in tabular formats like databases, while unstructured data, such as images or videos, lacks a predefined format. Explain the Role of Apache HBase.
They are responsible for building and maintaining data architectures, which include databases, data warehouses, and data lakes. Data Modelling Data modelling is creating a visual representation of a system or database. Physical Models: These models specify how data will be physically stored in databases.
The focus of this investigation revolves around understanding their industry distribution, age demographics, developer types, and their adoption of various programming languages, databases, platforms, web frameworks, miscellaneous technologies, technical tools, new collaboration tools, and AI-powered search tools. NET Framework (1.0–4.8)’
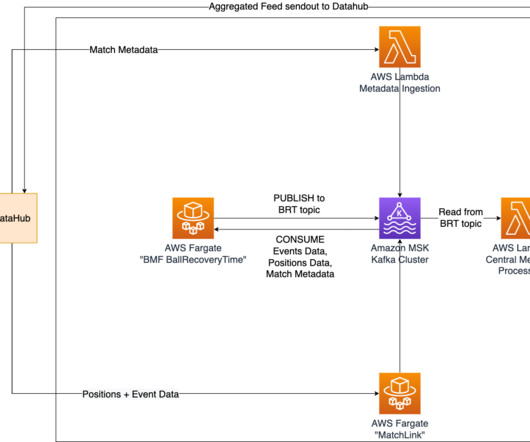
To ensure real-time updates of ball recovery times, we have implemented Amazon Managed Streaming for ApacheKafka (Amazon MSK) as a central solution for data streaming and messaging. A Lambda function retrieves all recovery times from the relevant Kafka topic and stores them in an Amazon Aurora Serverless database.
This includes structured data (like databases), semi-structured data (like XML files), and unstructured data (like text documents and videos). In-Memory Databases: Databases such as Redis store data in memory for lightning-fast access and processing speeds. Variety Variety indicates the different types of data being generated.
This includes structured data (like databases), semi-structured data (like XML files), and unstructured data (like text documents and videos). In-Memory Databases: Databases such as Redis store data in memory for lightning-fast access and processing speeds. Variety Variety indicates the different types of data being generated.
Data can come from different sources, such as databases or directly from users, with additional sources, including platforms like GitHub, Notion, or S3 buckets. Vector Databases Vector databases help store unstructured data by storing the actual data and its vector representation. mp4,webm, etc.), and audio files (.wav,mp3,acc,
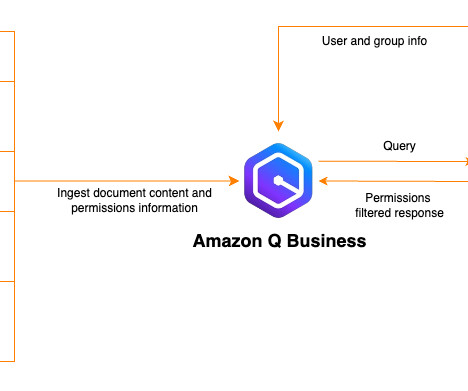
Configure your Slack workspace You will create one user for each of the following roles: Administrator , Data scientist , Database administrator , Solutions architect and Generic. I am currently using ApacheKafka. See Setting up for Amazon Q Business for more information. Post the first question to Amazon Q Business.
Variety It encompasses the different types of data, including structured data (like databases), semi-structured data (like XML), and unstructured formats (such as text, images, and videos). Understanding the differences between SQL and NoSQL databases is crucial for students.
Database Extraction: Retrieval from structured databases using query languages like SQL. Common options include: Relational Databases: Structured storage supporting ACID transactions, suitable for structured data. NoSQL Databases: Flexible, scalable solutions for unstructured or semi-structured data.
Below are some prominent use cases for Apache NiFi: Data Ingestion from Diverse Sources NiFi excels at collecting data from various sources, including log files, sensors, databases, and APIs. It can connect to various database s, file systems, and cloud storage solutions, enabling seamless data transfer without significant downtime.
It is used to extract data from various sources, transform the data to fit a specific data model or schema, and then load the transformed data into a target system such as a data warehouse or a database. The events can be published to a message broker such as ApacheKafka or Google Cloud Pub/Sub.
ApacheKafka), organisations can now analyse vast amounts of data as it is generated. Focus on Python and R for Data Analysis, along with SQL for database management. Understanding real-time data processing frameworks, such as ApacheKafka, will also enhance your ability to handle dynamic analytics.
Open-source technologies will become even more prominent within enterprises’ data architecture over the coming year, driven by the stark budgetary advantages combined with some of the newest enterprise-friendly capabilities added to several solutions. Here are three predictions for the open-source data infrastructure space in 2023: 1.
There are a number of tools that can help with streaming data collection and processing, some popular ones include: ApacheKafka : An open-source, distributed event streaming platform that can handle millions of events per second. It can be used to collect, store, and process streaming data in real-time.
This involves working with various data storage technologies, such as databases and data warehouses, and ensuring that the data is easily accessible and can be analyzed efficiently. Collecting, storing, and processing large datasets Data engineers are also responsible for collecting, storing, and processing large volumes of data.
Although tools like ApacheKafka and Apache Spark can integrate with Hadoop for real-time processing, managing these additional components can add complexity to the architecture. Organisations may face challenges when trying to connect Hadoop with traditional relational databases, data warehouses, or other data sources.
Typical examples include: Airbyte Talend ApacheKafkaApache Beam Apache Nifi While getting control over the process is an ideal position an organization wants to be in, the time and effort needed to build such systems are immense and frequently exceeds the license fee of a commercial offering. Talend Free to use.
In today’s fast-paced world, the concept of patience as a virtue seems to be fading away, as people no longer want to wait for anything. If Netflix takes too long to load or the nearest Lyft is too far, users are quick to switch to alternative options.
For every xSaves prediction, it produces a message with the prediction as a payload, which then gets distributed by a central message broker running on Amazon Managed Streaming for ApacheKafka (Amazon MSK). The information also gets stored in a data lake for future auditing and model improvements.
It often involves specialized databases designed to handle this kind of atomic, temporal data. Technologies like ApacheKafka, often used in modern CDPs, use log-based approaches to stream customer events between systems in real-time. It’s precise but can impact database performance.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content