This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Recognizing the need to harness real-time data, businesses are increasingly turning to event-driven architecture (EDA) as a strategic approach to stay ahead of the curve. At the forefront of this event-driven revolution is ApacheKafka, the widely recognized and dominant open-source technology for event streaming.
ApacheKafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. With ApacheKafka, developers can build applications that continuously use streaming data records and deliver real-time experiences to users. How does ApacheKafka work?
Be sure to check out his talk, “ ApacheKafka for Real-Time Machine Learning Without a Data Lake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the ApacheKafka ecosystem.
By leveraging AI for real-time event processing, businesses can connect the dots between disparate events to detect and respond to new trends, threats and opportunities. AI and event processing: a two-way street An event-driven architecture is essential for accelerating the speed of business.
Within this article, we will explore the significance of these pipelines and utilise robust tools such as ApacheKafka and Spark to manage vast streams of data efficiently. ApacheKafkaApacheKafka is a distributed event streaming platform used for building real-time data pipelines and streaming applications.
ApacheKafka is a well-known open-source event store and stream processing platform and has grown to become the de facto standard for data streaming. ApacheKafka transfers data without validating the information in the messages. Optimize your Kafka environment by using a schema registry.
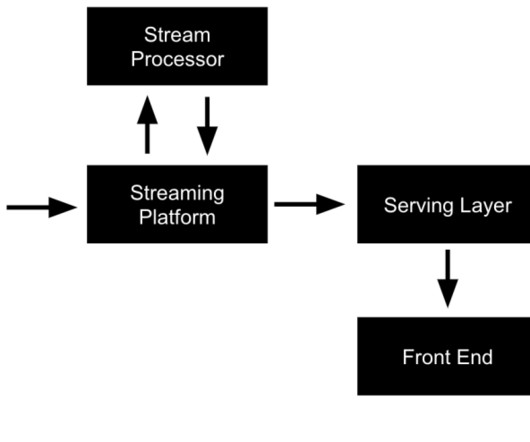
In this representation, there is a separate store for events within the speed layer and another store for data loaded during batch processing. It is important to note that in the Lambda architecture, the serving layer can be omitted, allowing batch processing and event streaming to remain separate entities.
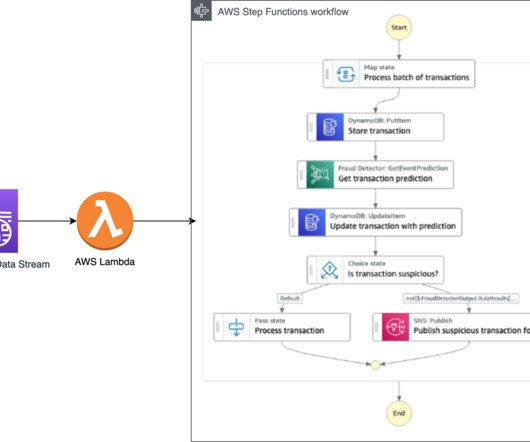
We show how you can apply this approach to various data streaming and event-driven architectures, depending on the desired outcome and actions to take to prevent fraud (such as alert the user about the fraud or flag the transaction for additional review). The user can then choose to take action to prevent further abuse.
Its characteristics can be summarized as follows: Volume : Big Data involves datasets that are too large to be processed by traditional database management systems. databases), semi-structured data (e.g., These datasets can range from terabytes to petabytes and beyond. XML, JSON), and unstructured data (e.g., text, images, videos).
Streaming data pipelines, by extension, offer an architecture capable of handling large volumes of data, accommodating millions of events in near real time. One very popular platform is ApacheKafka , a powerful open-source tool used by thousands of companies. You need a separate tool to do that.
Event-driven businesses across all industries thrive on real-time data, enabling companies to act on events as they happen rather than after the fact. This is where Apache Flink shines, offering a powerful solution to harness the full potential of an event-driven business model through efficient computing and processing capabilities.
To understand what it means, we should start by thinking of the world in terms of events, where an event is a thing that happens. And we are going to take those events, become aware of them, and understand them. Stores events in a durable manner so that downstream components can process them.
How Snowflake Helps Achieve Real-Time Analytics Snowflake is the ideal platform to achieve real-time analytics for several reasons, but two of the biggest are its ability to manage concurrency due to the multi-cluster architecture of Snowflake and its robust connections to 3rd party tools like Kafka. p8 -pubout -out C:tmpnew_rsa_key_v1.pub
This process comprises two key components: event data and optical tracking data. Event data collection entails gathering the fundamental building blocks of the game. For the precision needed in shot speed calculations, we must ensure that the ball’s position aligns precisely with the moment of the event.
It initially sources input time series data from Amazon Managed Streaming for ApacheKafka (Amazon MSK) using this live stream for model training. Conclusion This post demonstrated how to build a robust real-time anomaly detection solution for streaming time series data using Managed Service for Apache Flink and other AWS services.
How Keeper Efficiency is implemented This Bundesliga Match Fact consumes both event and positional data. Event data consists of hand-labelled event descriptions with useful attributes, such as shot on target. This frame is used to synchronize the event data with the positional data.
It utilises Amazon Web Services (AWS) as its main data lake, processing over 550 billion events daily—equivalent to approximately 1.3 Data in Motion Technologies like ApacheKafka facilitate real-time processing of events and data, allowing Netflix to respond swiftly to user interactions and operational needs.
Streaming data is a continuous flow of information and a foundation of event-driven architecture software model” – RedHat Enterprises around the world are becoming dependent on data more than ever. A streaming data pipeline is an enhanced version which is able to handle millions of events in real-time at scale.
It is used to extract data from various sources, transform the data to fit a specific data model or schema, and then load the transformed data into a target system such as a data warehouse or a database. The company can use the Pub/Sub pattern to process customer events such as product views, add to cart, and checkout.
Guaranteed Delivery : NiFi ensures that data delivered reliably, even in the event of failures. It maintains a write-ahead log to ensure that the state of FlowFiles preserved, even in the event of a failure. Provenance Repository : This repository records all provenance events related to FlowFiles.
They are responsible for building and maintaining data architectures, which include databases, data warehouses, and data lakes. Data Modelling Data modelling is creating a visual representation of a system or database. Physical Models: These models specify how data will be physically stored in databases.
In this guide, we will explore concepts like transitional modeling for customer profiles, the power of event logs for customer behavior, persistent staging for raw customer data, real-time customer data capture, and much more. It often involves specialized databases designed to handle this kind of atomic, temporal data.
Data can come from different sources, such as databases or directly from users, with additional sources, including platforms like GitHub, Notion, or S3 buckets. Vector Databases Vector databases help store unstructured data by storing the actual data and its vector representation. mp4,webm, etc.), and audio files (.wav,mp3,acc,
Variety It encompasses the different types of data, including structured data (like databases), semi-structured data (like XML), and unstructured formats (such as text, images, and videos). Understanding the differences between SQL and NoSQL databases is crucial for students. Once data is collected, it needs to be stored efficiently.
Data Ingestion : Involves raw data collection from origin and storage using architectures such as batch, streaming or event-driven. Data Pipeline Tool Key Features Apache Airflow Flexible, customizable, and supports complex business logic. Relational database connectors are available. Talend Free to use.
Streaming ingestion – An Amazon Kinesis Data Analytics for Apache Flink application backed by ApacheKafka topics in Amazon Managed Streaming for ApacheKafka (MSK) (Amazon MSK) calculates aggregated features from a transaction stream, and an AWS Lambda function updates the online feature store.
ApacheKafka, Amazon Kinesis) 2 Data Preprocessing (e.g., The exploration of common machine learning pipeline architecture and patterns starts with a pattern found in not just machine learning systems but also database systems, streaming platforms, web applications, and modern computing infrastructure. 1 Data Ingestion (e.g.,
Best Big Data Tools Popular tools such as Apache Hadoop, Apache Spark, ApacheKafka, and Apache Storm enable businesses to store, process, and analyse data efficiently. Real-Time Data Analysis: Connects seamlessly with various databases for live analysis.
However, it lacked essential services required for machine learning (ML) applications, such as frontend and backend infrastructure, DNS, load balancers, scaling, blob storage, and managed databases. At that time, the application was deployed as a single monolithic container, which included Kafka and a database.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


































Let's personalize your content