This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Be sure to check out his talk, “ ApacheKafka for Real-Time Machine Learning Without a Data Lake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the ApacheKafka ecosystem.
Businesses are increasingly using machine learning (ML) to make near-real-time decisions, such as placing an ad, assigning a driver, recommending a product, or even dynamically pricing products and services. Apache Flink is a popular framework and engine for processing data streams. 0 … 1248 Nov-02 12:14:31 32.45
In this post, we demonstrate how to build a robust real-time anomaly detection solution for streaming time series data using Amazon Managed Service for Apache Flink and other AWS managed services. This solution employs machine learning (ML) for anomaly detection, and doesn’t require users to have prior AI expertise.
More than ever, advanced analytics, ML, and AI are providing the foundation for innovation, efficiency, and profitability. One very popular platform is ApacheKafka , a powerful open-source tool used by thousands of companies. But in all likelihood, Kafka doesn’t natively connect with the applications that contain your data.
Aggregates as predictive insights : Aggregates, which consolidate data from various sources across your business environment, can serve as valuable predictors for machine learning (ML) algorithms. Event processing helps continuously update and refine our understanding of ongoing business scenarios.
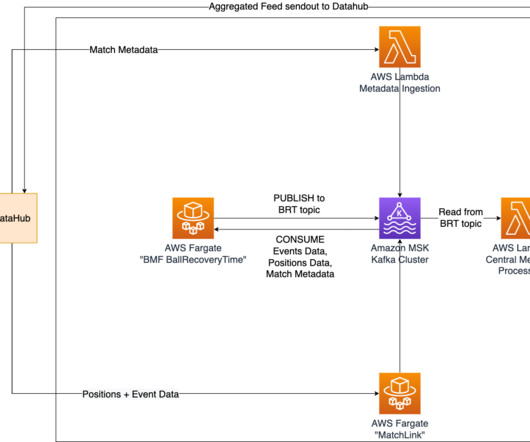
m How it’s implemented In our quest to accurately determine shot speed during live matches, we’ve implemented a cutting-edge solution using Amazon Managed Streaming for ApacheKafka (Amazon MSK). We’ve implemented an AWS Lambda function with the specific task of retrieving the calculated shot speed from the relevant Kafka topic.
The result is a machine learning (ML)-powered insight that allows fans to easily evaluate and compare the goalkeepers’ proficiencies. An ML model is trained through Amazon SageMaker , using data from four seasons of the first and second Bundesliga, encompassing all shots that landed on target (either resulting in a goal or being saved).
Managing unstructured data is essential for the success of machine learning (ML) projects. This article will discuss managing unstructured data for AI and ML projects. You will learn the following: Why unstructured data management is necessary for AI and ML projects. How to properly manage unstructured data.
To ensure real-time updates of ball recovery times, we have implemented Amazon Managed Streaming for ApacheKafka (Amazon MSK) as a central solution for data streaming and messaging. A Lambda function retrieves all recovery times from the relevant Kafka topic and stores them in an Amazon Aurora Serverless database.
The focus of this investigation revolves around understanding their industry distribution, age demographics, developer types, and their adoption of various programming languages, databases, platforms, web frameworks, miscellaneous technologies, technical tools, new collaboration tools, and AI-powered search tools. NET Framework (1.0–4.8)’
There are a number of tools that can help with streaming data collection and processing, some popular ones include: ApacheKafka : An open-source, distributed event streaming platform that can handle millions of events per second. It can be used to collect, store, and process streaming data in real-time. Happy Learning!
Database Extraction: Retrieval from structured databases using query languages like SQL. Common options include: Relational Databases: Structured storage supporting ACID transactions, suitable for structured data. NoSQL Databases: Flexible, scalable solutions for unstructured or semi-structured data.
It is used to extract data from various sources, transform the data to fit a specific data model or schema, and then load the transformed data into a target system such as a data warehouse or a database. The events can be published to a message broker such as ApacheKafka or Google Cloud Pub/Sub.
A typical data pipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process. If a typical ML project involves standard pre-processing steps – why not make it reusable? Relational database connectors are available.
It often involves specialized databases designed to handle this kind of atomic, temporal data. Technologies like ApacheKafka, often used in modern CDPs, use log-based approaches to stream customer events between systems in real-time. It’s precise but can impact database performance.
There comes a time when every ML practitioner realizes that training a model in Jupyter Notebook is just one small part of the entire project. At that point, the Data Scientists or ML Engineers become curious and start looking for such implementations. What are ML pipeline architecture design patterns?
New Big Data Concepts vs Cloud Delivered Databases? So, what has the emergence of cloud databases done to change big data? Spark, Tensorflow, ApacheKafka, et cetera, are all out found in cloud databases,” points out Jones. To improve ML and Ethics, data literacy training is critical.
The rise of advanced technologies such as Artificial Intelligence (AI), Machine Learning (ML) , and Big Data analytics is reshaping industries and creating new opportunities for Data Scientists. ApacheKafka), organisations can now analyse vast amounts of data as it is generated. Here are five key trends to watch.
Best Big Data Tools Popular tools such as Apache Hadoop, Apache Spark, ApacheKafka, and Apache Storm enable businesses to store, process, and analyse data efficiently. Machine Learning Integration : Built-in ML capabilities streamline model development and deployment.
However, it lacked essential services required for machine learning (ML) applications, such as frontend and backend infrastructure, DNS, load balancers, scaling, blob storage, and managed databases. At that time, the application was deployed as a single monolithic container, which included Kafka and a database.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content