This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
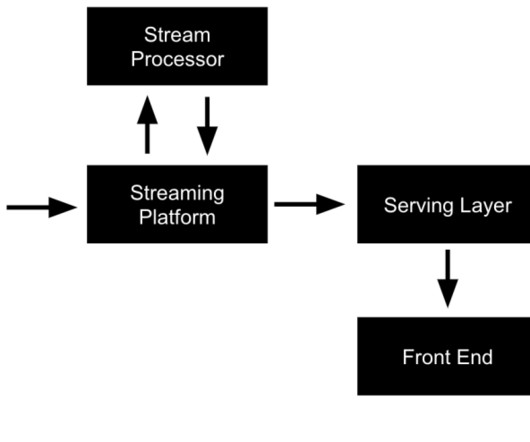
The bit that I’ve highlighted in bold is the most important part of the definition in my opinion. We’re going to assume that the pizza service already captures orders in ApacheKafka and is also keeping a record of its customers and the products that they sell in MySQL.
For instance, if you are working with several high-definition videos, storing them would take a lot of storage space, which could be costly. Popular data lake solutions include Amazon S3 , Azure Data Lake , and Hadoop. Kafka is highly scalable and ideal for high-throughput and low-latency data pipeline applications.
Definition and Explanation of Data Pipelines A data pipeline is a series of interconnected steps that ingest raw data from various sources, process it through cleaning, transformation, and integration stages, and ultimately deliver refined data to end users or downstream systems.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









Let's personalize your content