This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The last few days I spent some time digging into the recently announced KIP-1150 ("Diskless Kafka"), as well AutoMQs Kafka fork, tightly integrating ApacheKafka and object storage, such as S3. Separating storage and compute and object store support would be table stakes, but what else should be there?
You can safely use an ApacheKafka cluster for seamless data movement from the on-premise hardware solution to the data lake using various cloud services like Amazon’s S3 and others. 5 Key Comparisons in Different ApacheKafka Architectures. 5 Key Comparisons in Different ApacheKafka Architectures.
Hosted at one of Mindspace’s coworking locations, the event was a convergence of insightful talks and professional networking. Mindspace , a global coworking and flexible office provider with over 45 locations worldwide, including 13 in Germany, offered a conducive environment for this knowledge-sharing event.
In this representation, there is a separate store for events within the speed layer and another store for data loaded during batch processing. It is important to note that in the Lambda architecture, the serving layer can be omitted, allowing batch processing and event streaming to remain separate entities.
Event-driven businesses across all industries thrive on real-time data, enabling companies to act on events as they happen rather than after the fact. This is where Apache Flink shines, offering a powerful solution to harness the full potential of an event-driven business model through efficient computing and processing capabilities.
How Snowflake Helps Achieve Real-Time Analytics Snowflake is the ideal platform to achieve real-time analytics for several reasons, but two of the biggest are its ability to manage concurrency due to the multi-cluster architecture of Snowflake and its robust connections to 3rd party tools like Kafka. Looking for additional help?
TR used AWS Glue DataBrew and AWS Batch jobs to perform the extract, transform, and load (ETL) jobs in the ML pipelines, and SageMaker along with Amazon Personalize to tailor the recommendations. As the users are interacting with TR’s applications, they generate clickstream events, which are published into Amazon Kinesis Data Streams.
ETL Design Pattern The ETL (Extract, Transform, Load) design pattern is a commonly used pattern in data engineering. ETL Design Pattern Here is an example of how the ETL design pattern can be used in a real-world scenario: A healthcare organization wants to analyze patient data to improve patient outcomes and operational efficiency.
Guaranteed Delivery : NiFi ensures that data delivered reliably, even in the event of failures. It maintains a write-ahead log to ensure that the state of FlowFiles preserved, even in the event of a failure. Provenance Repository : This repository records all provenance events related to FlowFiles.
Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load. ETL is vital for ensuring data quality and integrity. Among these tools, Apache Hadoop, Apache Spark, and ApacheKafka stand out for their unique capabilities and widespread usage.
Online Gaming: Online gaming platforms require real-time data ingestion to handle large-scale events and provide a seamless experience for players. Data warehousing and ETL (Extract, Transform, Load) procedures frequently involve batch processing.
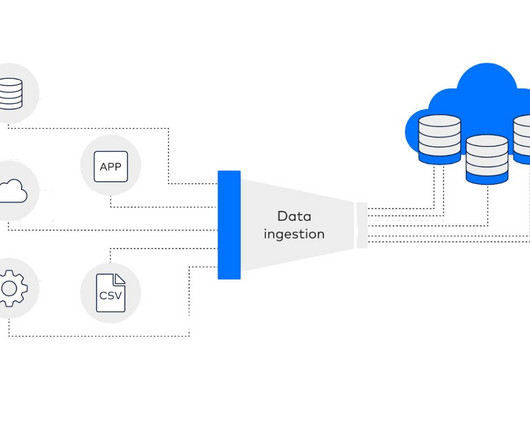
Data Ingestion : Involves raw data collection from origin and storage using architectures such as batch, streaming or event-driven. Pricing It is free to use and is licensed under Apache License Version 2.0. Hevo Data Overview It’s an intuitive no-code ETL tool that also supports ELT and reverse ETL processes out of the box.
Data Integration Tools Technologies such as Apache NiFi and Talend help in the seamless integration of data from various sources into a unified system for analysis. Understanding ETL (Extract, Transform, Load) processes is vital for students. Students should understand the concepts of event-driven architecture and stream processing.
Flexibility: Its use cases are wider than just machine learning; for example, we can use it to set up ETL pipelines. Flexibility: Airflow was designed with batch workflows in mind; it was not meant for permanently running event-based workflows. Miscellaneous Workflows are created as directed acyclic graphs (DAGs).
ApacheKafkaApacheKafka is a distributed event streaming platform for real-time data pipelines and stream processing. Kafka is highly scalable and ideal for high-throughput and low-latency data pipeline applications. is similar to the traditional Extract, Transform, Load (ETL) process. Unstructured.io
In this guide, we will explore concepts like transitional modeling for customer profiles, the power of event logs for customer behavior, persistent staging for raw customer data, real-time customer data capture, and much more. Rich Context: Each event carries with it a wealth of contextual information. What is Activity Schema Modeling?
Python, SQL, and Apache Spark are essential for data engineering workflows. Real-time data processing with ApacheKafka enables faster decision-making. Apache Spark Apache Spark is a powerful data processing framework that efficiently handles Big Data. The global Big Data and data engineering market, valued at $75.55
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content