This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post 22 Widely Used Data Science and MachineLearning Tools in 2020 appeared first on Analytics Vidhya. Overview There are a plethora of data science tools out there – which one should you pick up? Here’s a list of over 20.
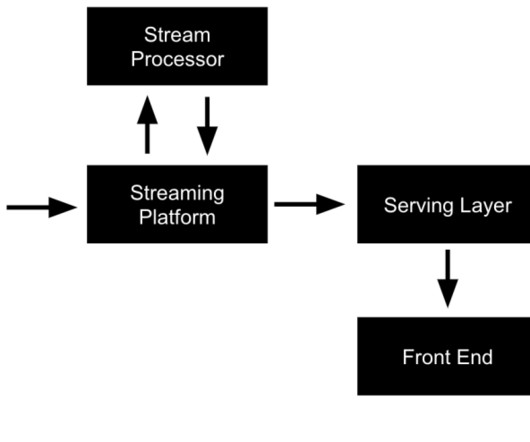
Be sure to check out his talk, “ ApacheKafka for Real-Time MachineLearning Without a Data Lake ,” there! The combination of data streaming and machinelearning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machinelearning tasks using the ApacheKafka ecosystem.
Summary: A Hadoop cluster is a collection of interconnected nodes that work together to store and process large datasets using the Hadoop framework. Introduction A Hadoop cluster is a group of interconnected computers, or nodes, that work together to store and process large datasets using the Hadoop framework.
Hadoop Distributed File System (HDFS) : HDFS is a distributed file system designed to store vast amounts of data across multiple nodes in a Hadoop cluster. It supports various data processing operations, including batch processing, real-time stream processing, machinelearning, and graph processing.
These procedures are central to effective data management and crucial for deploying machinelearning models and making data-driven decisions. After this, the data is analyzed, business logic is applied, and it is processed for further analytical tasks like visualization or machinelearning. What is a Data Pipeline?
Managing unstructured data is essential for the success of machinelearning (ML) projects. Popular data lake solutions include Amazon S3 , Azure Data Lake , and Hadoop. ApacheKafkaApacheKafka is a distributed event streaming platform for real-time data pipelines and stream processing.
Big data got“ more leaders and people in the organization to use data, analytics, and machinelearning in their decision making,” says former CIO Isaac Sacolick. “Setting up Hadoop on-premises was a huge undertaking. Spark, Tensorflow, ApacheKafka, et cetera, are all out found in cloud databases,” points out Jones.
We’re going to assume that the pizza service already captures orders in ApacheKafka and is also keeping a record of its customers and the products that they sell in MySQL. Apache Pinot is a real-time OLAP database built at LinkedIn to deliver scalable real-time analytics with low latency.
Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers. It is built on the Hadoop Distributed File System (HDFS) and utilises MapReduce for data processing. Once data is collected, it needs to be stored efficiently.
On the other hand, Data Science involves extracting insights and knowledge from data using Statistical Analysis, MachineLearning, and other techniques. Among these tools, ApacheHadoop, Apache Spark, and ApacheKafka stand out for their unique capabilities and widespread usage.
Summary: The future of Data Science is shaped by emerging trends such as advanced AI and MachineLearning, augmented analytics, and automated processes. Continuous learning and adaptation will be essential for data professionals. Automated MachineLearning (AutoML) will democratize access to Data Science tools and techniques.
Processing frameworks like Hadoop enable efficient data analysis across clusters. Distributed File Systems: Technologies such as Hadoop Distributed File System (HDFS) distribute data across multiple machines to ensure fault tolerance and scalability. Data lakes and cloud storage provide scalable solutions for large datasets.
Processing frameworks like Hadoop enable efficient data analysis across clusters. Distributed File Systems: Technologies such as Hadoop Distributed File System (HDFS) distribute data across multiple machines to ensure fault tolerance and scalability. Data lakes and cloud storage provide scalable solutions for large datasets.
Some of these solutions include: Distributed computing: Distributed computing systems, such as Hadoop and Spark, can help distribute the processing of data across multiple nodes in a cluster. Solutions for managing and processing large volumes of data Data engineers can use various solutions to manage and process large volumes of data.
The events can be published to a message broker such as ApacheKafka or Google Cloud Pub/Sub. The message broker can then distribute the events to various subscribers such as data processing pipelines, machinelearning models, and real-time analytics dashboards.
Techniques like regression analysis, time series forecasting, and machinelearning algorithms are used to predict customer behavior, sales trends, equipment failure, and more. Use machinelearning algorithms to build a fraud detection model and identify potentially fraudulent transactions.
Best Big Data Tools Popular tools such as ApacheHadoop, Apache Spark, ApacheKafka, and Apache Storm enable businesses to store, process, and analyse data efficiently. It is designed to scale up from a single server to thousands of machines. Use Cases : Yahoo!
Python, SQL, and Apache Spark are essential for data engineering workflows. Real-time data processing with ApacheKafka enables faster decision-making. Apache Spark Apache Spark is a powerful data processing framework that efficiently handles Big Data. The global Big Data and data engineering market, valued at $75.55
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























Let's personalize your content