This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction ApacheKafka is a framework for dealing with many real-time data streams in a way that is spread out. It was made on LinkedIn and shared with the public in 2011.
In today’s rapidly evolving digital landscape, enterprises are facing the complexities of information overload. At the forefront of this event-driven revolution is ApacheKafka, the widely recognized and dominant open-source technology for event streaming. However, ApacheKafka isn’t always enough.
ApacheKafka and Apache Flink working together Anyone who is familiar with the stream processing ecosystem is familiar with ApacheKafka: the de-facto enterprise standard for open-source event streaming. With ApacheKafka, you get a raw stream of events from everything that is happening within your business.
ApacheKafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. With ApacheKafka, developers can build applications that continuously use streaming data records and deliver real-time experiences to users. How does ApacheKafka work?
You can safely use an ApacheKafka cluster for seamless data movement from the on-premise hardware solution to the data lake using various cloud services like Amazon’s S3 and others. 5 Key Comparisons in Different ApacheKafka Architectures. 5 Key Comparisons in Different ApacheKafka Architectures.
Organizations rely on timely information to gain insights and maintain competitive advantages. The process of complex event processing CEP comprises a structured approach to processing real-time data, ensuring that organizations can act on critical information effectively.
However, IBM MQ and ApacheKafka can sometimes be viewed as competitors, taking each other on in terms of speed, availability, cost and skills. MQ and ApacheKafka: Teammates Simply put, they are different technologies with different strengths, albeit often perceived to be quite similar.
These events can provide a wealth of information about what’s actually happening across your business at any moment in time. For more information, please visit the IBM Event Automation website or contact your local IBM representative or IBM Business Partner.
ApacheKafka is a well-known open-source event store and stream processing platform and has grown to become the de facto standard for data streaming. ApacheKafka transfers data without validating the information in the messages. Kafka does not examine the metadata of your messages.
They often use ApacheKafka as an open technology and the de facto standard for accessing events from a various core systems and applications. IBM provides an Event Streams capability build on ApacheKafka that makes events manageable across an entire enterprise.
Many scenarios call for up-to-the-minute information. Enterprise technology is having a watershed moment; no longer do we access information once a week, or even once a day. Now, information is dynamic. That enables you to collect, analyze, and store large amounts of information. What is a streaming data pipeline?
With the explosive growth of big data over the past decade and the daily surge in data volumes, it’s essential to have a resilient system to manage the vast influx of information without failures. This phase ensures quality and consistency using frameworks like Apache Spark or AWS Glue.
This data, often referred to as Big Data , encompasses information from various sources, including social media interactions, online transactions, sensor data, and more. The generation and accumulation of vast amounts of data have become a defining characteristic of our world.
Leveraging real-time analytics to make informed decisions is the golden standard for virtually every business that collects data. What is ApacheKafka, and How is it Used in Building Real-time Data Pipelines? ApacheKafka is an open-source event distribution platform. Example: openssl rsa -in C:tmpnew_rsa_key_v1.p8
With it, organizations can help business and IT teams acquire the ability to access, interpret and act on real-time information about unique situations arising across the entire organization. Non-symbolic AI can be useful for transforming unstructured data into organized, meaningful information.
ApacheKafka stands as a widely recognized open source event store and stream processing platform. One key advantage of opting for managed Kafka services is the delegation of responsibility for broker and operational metrics, allowing users to focus solely on metrics specific to applications.
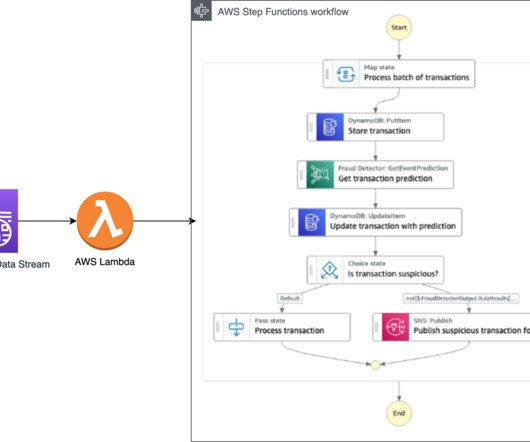
For more information, refer to Train fraudulent payment detection with Amazon SageMaker. The same architecture applies if you use Amazon Managed Streaming for ApacheKafka (Amazon MSK) as a data streaming service. You can also use Amazon SageMaker to train a proprietary fraud detection model.
A Slack workspace captures invaluable organizational knowledge in the form of the information that flows through it as the users communicate on it. With RAG, generative AI enhances its responses by incorporating relevant information retrieved from a curated dataset. See the Slack documentation on access tokens for more information.
ApacheKafka is a high-performance, highly scalable event streaming platform. To unlock Kafka’s full potential, you need to carefully consider the design of your application. It’s all too easy to write Kafka applications that perform poorly or eventually hit a scalability brick wall.
In a real-world scenario, features related to cardholder spending patterns would only form part of the model’s feature set, and we can include information about the merchant, the cardholder, the device used to make the payment, and any other data that may be relevant to detecting fraud. This dataset contains 5.4
The image contains all the necessary information to serve the inference request, such as model location, MATLAB authentication information, and algorithms. This is where you can set up the desired instance size for hosting depending on the workload. predictor = est.deploy(role, "ClassificationTreeInferenceHandler", uint8(1), "ml.m5.large")
Data in Motion Technologies like ApacheKafka facilitate real-time processing of events and data, allowing Netflix to respond swiftly to user interactions and operational needs. By analysing vast amounts of viewer data, Netflix personalises content recommendations, informs content creation decisions, and improves customer engagement.
Used by more than 75% of the Fortune 500, ApacheKafka has emerged as a powerful open source data streaming platform to meet these challenges. But harnessing and integrating Kafka’s full potential into enterprise environments can be complex. This is where Confluent steps in.
In recognizing the benefits of event-driven architectures, many companies have turned to ApacheKafka for their event streaming needs. ApacheKafka enables scalable, fault-tolerant and real-time processing of streams of data—but how do you manage and properly utilize the sheer amount of data your business ingests every second?
Wednesday, June 14th Me, my health, and AI: applications in medical diagnostics and prognostics: Sara Khalid | Associate Professor, Senior Research Fellow, Biomedical Data Science and Health Informatics | University of Oxford Iterated and Exponentially Weighted Moving Principal Component Analysis : Dr. Paul A.
This crucial step enhances data quality, enables real-time insights, and supports informed decision-making. From extracting information from databases and spreadsheets to ingesting streaming data from IoT devices and social media platforms, It’s the foundation upon which data-driven initiatives are built.
Precisely data integrity solutions fuel your Confluent and ApacheKafka streaming data pipelines with trusted data that has maximum accuracy, consistency, and context and we’re ready to share more with you at the upcoming Current 2023. Let’s cover some additional information to know before attending.
Thomson Reuters (TR) is one of the world’s most trusted information organizations for businesses and professionals. An AWS Batch job is used to curate the recommendations for each customer and enrich it with the optimized pricing information. This post is co-written by Hesham Fahim from Thomson Reuters.
m How it’s implemented In our quest to accurately determine shot speed during live matches, we’ve implemented a cutting-edge solution using Amazon Managed Streaming for ApacheKafka (Amazon MSK). Example 1 Measured with top shot speed 118.43 km/h with a distance to goal of 20.61 m Example 2 Measured with top shot speed 123.32
Data privacy regulations will shape how organisations handle sensitive information in analytics. ApacheKafka), organisations can now analyse vast amounts of data as it is generated. In retail, customer behaviour analysis informs inventory management and marketing strategies.
By employing a DBMS, organisations can maintain data integrity, reduce redundancy, and streamline data operations, enabling more informed decision-making. This functionality allows for seamless data manipulation and is essential for maintaining up-to-date information.
Monitoring performance and security of these systems is critically important, but it does little good if you can only view that information a day or two after the fact. Tools like Splunk, Elastic, and ApacheKafka play a central role in IT operations analytics (ITOA).
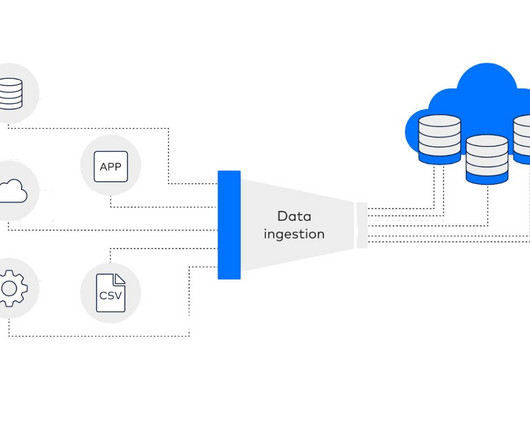
Real-time data ingestion is the practise of gathering and analysing information as it is produced, without little to no lag between the emergence of the data and its accessibility for analysis. Traders need up-to-the-second information to make informed decisions. What is Real-Time Data Ingestion?
This involves working closely with data analysts and data scientists to ensure that data is stored, processed, and analyzed efficiently to derive insights that inform decision-making. With the rise of big data, data engineering has become critical for organizations looking to make sense of the vast amounts of information at their disposal.
The goal is to ensure that data is available, reliable, and accessible for analysis, ultimately driving insights and informed decision-making within organisations. Their work ensures that data flows seamlessly through the organisation, making it easier for Data Scientists and Analysts to access and analyse information.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. As organisations collect vast amounts of information from various sources, ensuring data quality becomes critical.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. As organisations collect vast amounts of information from various sources, ensuring data quality becomes critical.
It covers best practices for ensuring scalability, reliability, and performance while addressing common challenges, enabling businesses to transform raw data into valuable, actionable insights for informed decision-making. They facilitate the seamless flow of information from diverse sources to actionable insights.
One thing is clear : unstructured data doesn’t mean it lacks information. All forms of data must have some form of information, or else they won’t be considered data. Here’s the structured equivalent of this same data in tabular form: With structured data, you can use query languages like SQL to extract and interpret information.
Streaming data is a continuous flow of information and a foundation of event-driven architecture software model” – RedHat Enterprises around the world are becoming dependent on data more than ever. Thus, a large amount of information can be collected, analysed, and stored. What is streaming data?
With this information, ChatGPT was guided through the process of producing the desired code, which will further facilitate the analysis of the dataset based on the enterprise size classification. ApacheKafka and R abbitMQ are particularly popular in LEs. If the obtained result is correct, I continue with further prompts.
Open-source technologies will become even more prominent within enterprises’ data architecture over the coming year, driven by the stark budgetary advantages combined with some of the newest enterprise-friendly capabilities added to several solutions. Here are three predictions for the open-source data infrastructure space in 2023: 1.
Overview In the era of Big Data , organizations inundated with vast amounts of information generated from various sources. Apache NiFi, an open-source data ingestion and distribution platform, has emerged as a powerful tool designed to automate the flow of data between systems.
The data is then transformed to fit a common data model that includes patient demographic information, clinical data, and patient satisfaction scores. The events can be published to a message broker such as ApacheKafka or Google Cloud Pub/Sub.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content