This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The post Handling Streaming Data with ApacheKafka – A First Look appeared first on Analytics Vidhya. Streaming Data is generated continuously, by multiple data sources say, sensors, server logs, stock prices, etc. These records are usually small and in the order […].
Introduction Earlier, I had introduced basic concepts of ApacheKafka in my blog on Analytics Vidhya(link is available under references). This article introduced concepts involved in ApacheKafka and further built the understanding by using the python API of Kafka to write some […].
Introduction ApacheKafka is a framework for dealing with many real-time data streams in a way that is spread out. It was made on LinkedIn and shared with the public in 2011.
Top 19 Skills You Need to Know in 2023 to Be a Data Scientist • 8 Open-Source Alternative to ChatGPT and Bard • Free eBook: 10 Practical Python Programming Tricks • DataLang: A New Programming Language for Data Scientists… Created by ChatGPT? • How to Build a Scalable Data Architecture with ApacheKafka
Dale Carnegie” ApacheKafka is a Software Framework for storing, reading, and analyzing streaming data. This article was published as a part of the Data Science Blogathon. Introduction “Learning is an active process. We learn by doing. Only knowledge that is used sticks in your mind.-
ApacheKafka and Apache Flink working together Anyone who is familiar with the stream processing ecosystem is familiar with ApacheKafka: the de-facto enterprise standard for open-source event streaming. With ApacheKafka, you get a raw stream of events from everything that is happening within your business.
Be sure to check out his talk, “ ApacheKafka for Real-Time Machine Learning Without a Data Lake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the ApacheKafka ecosystem.
Within this article, we will explore the significance of these pipelines and utilise robust tools such as ApacheKafka and Spark to manage vast streams of data efficiently. ApacheKafkaApacheKafka is a distributed event streaming platform used for building real-time data pipelines and streaming applications.
Example Python code snippet using MapReduce: Apache Spark Apache Spark is an open-source distributed computing system that provides an alternative to the MapReduce model. The MapReduce model is particularly suitable for data-intensive tasks like data cleaning, transformation, and aggregation.
Overview There are a plethora of data science tools out there – which one should you pick up? Here’s a list of over 20. The post 22 Widely Used Data Science and Machine Learning Tools in 2020 appeared first on Analytics Vidhya.
The unique advantages of Apache Flink Apache Flink augments event streaming technologies like ApacheKafka to enable businesses to respond to events more effectively in real time. Integration: Integrates seamlessly with other data systems and platforms, including ApacheKafka, Spark, Hadoop and various databases.
Verify your python3 installation by running python -V or python --version command on your terminal. Install Python if necessary. You can clean up these resources using the SageMaker Python SDK or the AWS Management Console for the specific services used here (SageMaker, Amazon ECR, and Amazon S3).
We’re going to assume that the pizza service already captures orders in ApacheKafka and is also keeping a record of its customers and the products that they sell in MySQL. Apache Pinot is a real-time OLAP database built at LinkedIn to deliver scalable real-time analytics with low latency.
Most publicly available fraud detection datasets don’t provide this information, so we use the Python Faker library to generate a set of transactions covering a 5-month period. Apache Flink is a popular framework and engine for processing data streams. This dataset contains 5.4
What is ApacheKafka, and Why is it Used? ApacheKafka is a distributed messaging system that handles real-time data streaming for building scalable, fault-tolerant data pipelines. Yes, I used ApacheKafka to process real-time data streams. Explain the CAP theorem and its relevance in Big Data systems.
ApacheKafka), organisations can now analyse vast amounts of data as it is generated. Focus on Python and R for Data Analysis, along with SQL for database management. Understanding real-time data processing frameworks, such as ApacheKafka, will also enhance your ability to handle dynamic analytics.
Following is a guide that can help you understand the types of projects and the projects involved with Python and Business Analytics. Here are some project ideas suitable for students interested in big data analytics with Python: 1. Movie Recommendation System: Use Python and collaborative filtering techniques (e.g., ImageNet).
Thanks to its various operators, it is integrated with Python, Spark, Bash, SQL, and more. Also, while it is not a streaming solution, we can still use it for such a purpose if combined with systems such as ApacheKafka. Basic Python knowledge is required for that; there is no need to learn other domain-specific languages.
Among these tools, Apache Hadoop, Apache Spark, and ApacheKafka stand out for their unique capabilities and widespread usage. Apache Hadoop Hadoop is a powerful framework that enables distributed storage and processing of large data sets across clusters of computers.
ApacheKafka and R abbitMQ are particularly popular in LEs. Full-stack and back-end developers are prevalent in both settings, with popular programming languages being JavaScript , Python , SQL , HTML/CSS , and T ypeScript. Graph 7: Percentage of Programming Languages MiscTech Tools In Both LEs and SMEs: ‘. NET Framework (1.0–4.8)’
There are a number of tools that can help with streaming data collection and processing, some popular ones include: ApacheKafka : An open-source, distributed event streaming platform that can handle millions of events per second. For setting up streaming/continuous flow of data, we will be using Kafka and Zookeeper.
Apache Spark A fast, in-memory data processing engine that provides support for various programming languages, including Python, Java, and Scala. Data Streaming Learning about real-time data collection methods using tools like ApacheKafka and Amazon Kinesis. Once data is collected, it needs to be stored efficiently.
Tools such as Python’s Pandas library, Apache Spark, or specialised data cleaning software streamline these processes, ensuring data integrity before further transformation. Utilise in-memory data processing tools like ApacheKafka and Apache Flink, which provide low-latency data ingestion and processing capabilities.
Although tools like ApacheKafka and Apache Spark can integrate with Hadoop for real-time processing, managing these additional components can add complexity to the architecture. Limited Support for Real-Time Processing While Hadoop excels at batch processing, it is not inherently designed for real-time data processing.
ApacheKafkaApacheKafka is a distributed event streaming platform for real-time data pipelines and stream processing. The tool offers a web UI as well as Python and TypeScript SDKs for developers. Data Processing Tools These tools are essential for handling large volumes of unstructured data.
A simple python implementation is shown below. Below is a sample python code snippet demonstrating fuzzy matching using Levenshtein distance. Tools like ApacheKafka and Apache Flink can be configured for this purpose. Then when identifying duplicates these hash keys are looked up.
Typical examples include: Airbyte Talend ApacheKafkaApache Beam Apache Nifi While getting control over the process is an ideal position an organization wants to be in, the time and effort needed to build such systems are immense and frequently exceeds the license fee of a commercial offering.
Challenges for individuals Traditional messaging brokers, such as ApacheKafka, RabbitMQ, and ActiveMQ, have been widely used to enable communication between applications and services. Handling too many data sources can become overwhelming, especially with complex schemas. Debugging and troubleshooting can also be challenging.
Tools like Python, SQL, Apache Spark, and Snowflake help engineers automate workflows and improve efficiency. Python, SQL, and Apache Spark are essential for data engineering workflows. Real-time data processing with ApacheKafka enables faster decision-making. billion in 2024 , is expected to reach $325.01
Best Big Data Tools Popular tools such as Apache Hadoop, Apache Spark, ApacheKafka, and Apache Storm enable businesses to store, process, and analyse data efficiently. Ease of Use : Supports multiple programming languages including Python, Java, and Scala.
With our new model, we first tried performing inference in Python with Flask and PyTorch, as well as with BentoML. It is backed by Amazon Managed Streaming for ApacheKafka (Amazon MSK) (8). Our previous model was running on TorchServe. The resources in the Kubernetes cluster are deployed in a private subnet.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












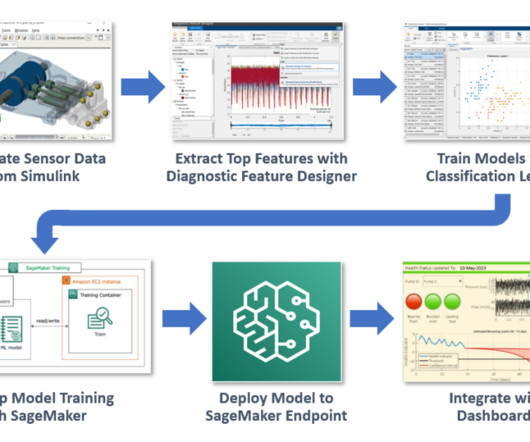
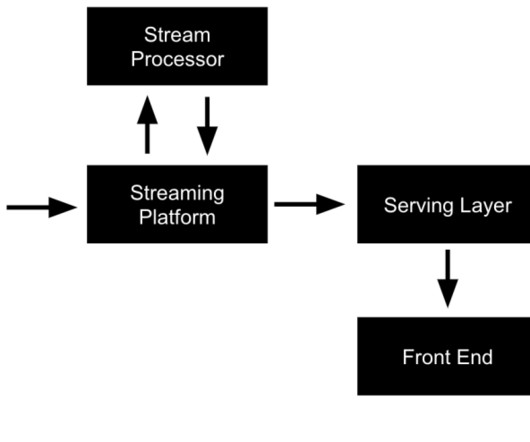
























Let's personalize your content