This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Companies may store petabytes of data in easy-to-access “clusters” that can be searched in parallel using the platform’s storage system. The post AWS Redshift: Cloud Data Warehouse Service appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a Data Pipeline with PySpark and AWS appeared first on Analytics Vidhya.
Amazon Bedrock offers a serverless experience, so you can get started quickly, privately customize FMs with your own data, and integrate and deploy them into your applications using Amazon Web Services (AWS) services without having to manage infrastructure. AWS Lambda The API is a Fastify application written in TypeScript.
It gives instant access to insights on over 10,000 companies from hundreds of thousands of proprietary intel articles, helping financial institutions make informed credit decisions while effectively managing risk. Along the way, it also simplified operations as Octus is an AWS shop more generally.
AWS was delighted to present to and connect with over 18,000 in-person and 267,000 virtual attendees at NVIDIA GTC, a global artificial intelligence (AI) conference that took place March 2024 in San Jose, California, returning to a hybrid, in-person experience for the first time since 2019.
AWS (Amazon Web Services), the comprehensive and evolving cloud computing platform provided by Amazon, is comprised of infrastructure as a service (IaaS), platform as a service (PaaS) and packaged software as a service (SaaS). With its wide array of tools and convenience, AWS has already become a popular choice for many SaaS companies.
Launching a machine learning (ML) training cluster with Amazon SageMaker training jobs is a seamless process that begins with a straightforward API call, AWS Command Line Interface (AWS CLI) command, or AWS SDK interaction. For this post, we demonstrate SMP implementation on SageMaker trainings jobs.
To ease this transition for customers unfamiliar with running containers in production, Amazon Web Services (AWS) has partnered with IBM and Red Hat to develop an IBM MAS on Red Hat OpenShift Service for AWS (ROSA) reference architecture. Why ROSA for Maximo in AWS? There are several advantages of IBM MAS SaaS on AWS.
This article was published as a part of the Data Science Blogathon. Introduction In machine learning, the data is an essential part of the training of machine learning algorithms. The amount of data and the data quality highly affect the results from the machine learning algorithms.
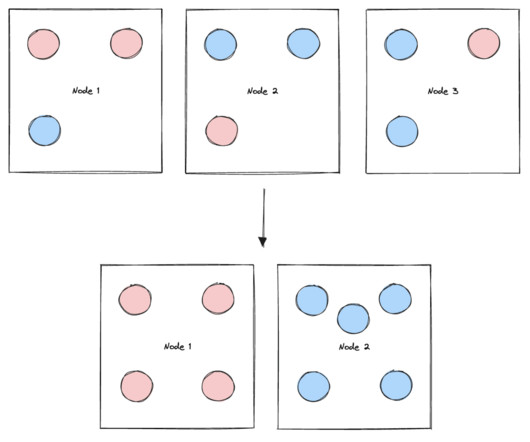
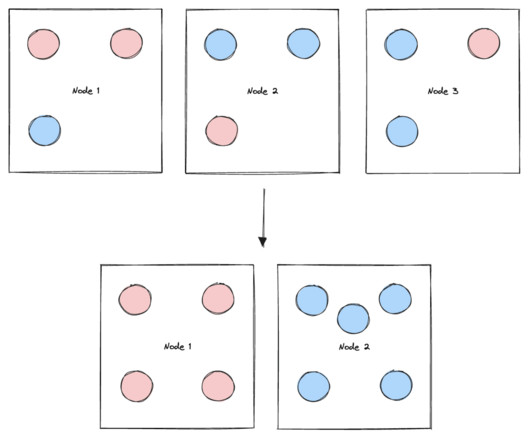
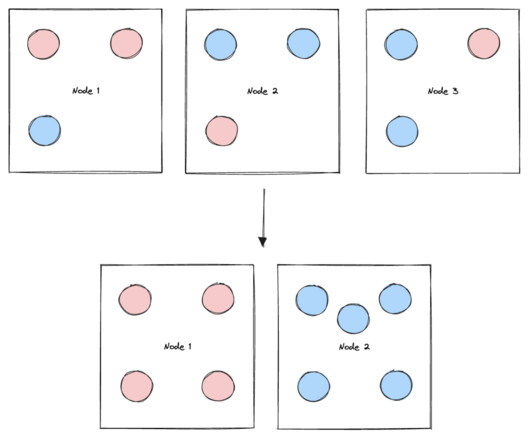
In this post, you’ll see an example of performing drift detection on embedding vectors using a clustering technique with large language models (LLMS) deployed from Amazon SageMaker JumpStart. Then we use K-Means to identify a set of cluster centers. A visual representation of the silhouette score can be seen in the following figure.
This article was published as a part of the Data Science Blogathon. Introduction on Amazon Elasticsearch Service Amazon Elasticsearch Service is a powerful tool that allows you to perform a number of functions. Let us examine how this powerful tool works behind the scenes.
In this blog post, we walk through the recommended options for running IBM TAS on Amazon Web Services (AWS). We discuss the architecture and describe how the IBM, Red Hat ® and AWS components come together and provide a solid foundation for running IBM TAS.
As the demand for the data solutions increased, cloud companies like AWS also jumped in and began providing managed data lake solutions with AWS Athena and S3. In this article, we will discuss shortcomings of indexing in Athena and S3 and how we can deal with them. AWS Athena and S3. Partition limits.
This article explores a recent journey during which we examined the problem of promoting images and the innovative solution that was adopted, all while adhering to the principles of GitOps. Each environment has a dedicated AWS account with its own cluster and ArgoCD installation. However, image promotion is often overlooked.
Users such as support engineers, project managers, and product managers need to be able to ask questions about an incident or a customer, or get answers from knowledge articles in order to provide excellent customer support. We use an example of an illustrative ServiceNow platform to discuss technical topics related to AWS services.
In this post, we explore the journey that Thomson Reuters took to enable cutting-edge research in training domain-adapted large language models (LLMs) using Amazon SageMaker HyperPod , an Amazon Web Services (AWS) feature focused on providing purpose-built infrastructure for distributed training at scale. So, for example, a 6.6B
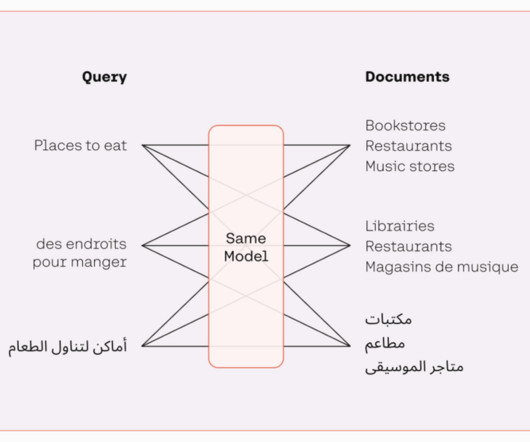
Amazon Titan Text Embeddings is a text embeddings model that converts natural language text—consisting of single words, phrases, or even large documents—into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity. Nitin Eusebius is a Sr.
Botnet Detection at Scale — Lessons Learned From Clustering Billions of Web Attacks Into Botnets Editor’s note: Ori Nakar is a speaker for ODSC Europe this June. Be sure to check out his talk, “ Botnet detection at scale — Lesson learned from clustering billions of web attacks into botnets ,” there!
The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference. Examples of other PBAs now available include AWS Inferentia and AWS Trainium , Google TPU, and Graphcore IPU. Suppliers of data center GPUs include NVIDIA, AMD, Intel, and others.
We also recommend reading the full article on the SAP Community blog site. The key components of Instana are host agents and agent sensors deployed on platforms like IBM Cloud®, AWS, and Azure. Supported cloud platforms with IBM Instana IBM Instana supports IBM Cloud, AWS, Azure and SAP.
This article will take you through the steps to start serving Watson NLP models using standalone containers. The same image can also be deployed on a cloud container service like AWS ECS or IBM Code Engine; or on a Kubernetes or OpenShift cluster. We won’t go into those details in this article though.
AWS customer Vericast is a marketing solutions company that makes data-driven decisions to boost marketing ROIs for its clients. Dynamic scaling of feature engineering jobs – A combination of various AWS services is used for this, but most notably SageMaker Processing.
This allows AWS customers to access it as an API, which eliminates the need to manage the underlying infrastructure and ensures that sensitive information remains securely managed and protected. Because we’re picking the longest articles, we ensure the length is not due to repeated sequences. We will clean that up. df['text'].iloc[2215]
Botnets Detection at Scale — Lesson Learned from Clustering Billions of Web Attacks into Botnets. Originally posted on OpenDataScience.com Read more data science articles on OpenDataScience.com , including tutorials and guides from beginner to advanced levels! And remember to get your pass soon.
In this article, we will explore the top machine learning deployment tools and platforms that can help organizations streamline their deployment process, improve model performance, and achieve their business goals. The model’s accessibility can also be enhanced by making it easily available to other applications through API calls.
In this article, we want to dig deeper into the fundamentals of machine learning as an engineering discipline and outline answers to key questions: Why does ML need special treatment in the first place? Prior to the cloud, setting up and operating a cluster that can handle workloads like this would have been a major technical challenge.
Summary: The article explores the differences between data driven and AI driven practices. To confirm seamless integration, you can use tools like Apache Hadoop, Microsoft Power BI, or Snowflake to process structured data and Elasticsearch or AWS for unstructured data. Adapt models to new data and include the latest trends or patterns.
How we designed scalable infrastructure with cost-efficiency in mind The Kubernetes distribution of Snorkel Flow involves a set of deployments running in a Kubernetes cluster containing pods that run various components of the platform. the orchestrator for our Ray cluster). Pods that are “flexible” can be safely moved to a new node.
The broad potential is why companies including AWS , IBM , Glean , Google, Microsoft, NVIDIA, Oracle and Pinecone are adopting RAG. By using RAG on a PC, users can link to a private knowledge source – whether that be emails, notes or articles – to improve responses. PCs equipped with NVIDIA RTX GPUs can now run some AI models locally.
TensorFlow is desired for its flexibility for ML and neural networks, PyTorch for its ease of use and innate design for NLP, and scikit-learn for classification and clustering. AWS Cloud, Azure Cloud, and others are all compatible with many other frameworks and languages, making them necessary for any NLP skill set.
How we designed scalable infrastructure with cost-efficiency in mind The Kubernetes distribution of Snorkel Flow involves a set of deployments running in a Kubernetes cluster containing pods that run various components of the platform. the orchestrator for our Ray cluster). Pods that are “flexible” can be safely moved to a new node.
This article aims to provide some strategies, tips, and tricks you can apply to optimize your infrastructure while deploying them. Even for basic inference on LLM, multiple accelerators or multi-node computing clusters like multiple Kubernetes pods are required. So is there a way to keep these expenses in check? Sure there is.
Scalability : Metaflow easily scales workflows from local environments to the cloud and has tight integration with AWS services like AWS Batch, S3, and Step Functions. AWS Integration : As Netflix developed Metaflow, it closely integrates with Amazon Web Services (AWS) infrastructure.
These attributes are only default values; you can override them and retain granular control over the AWS models you create. Install ipywidgets and then use the execution role associated with the current notebook as the AWS account role with SageMaker access. This is useful where limited labeled data is available for training.
Falcon 180B was trained by TII on Amazon SageMaker , on a cluster of approximately 4K A100 GPUs. The model is deployed in an AWS secure environment and under your VPC controls, helping ensure data security. Olivier Cruchan t is a Principal Machine Learning Specialist Solutions Architect at AWS, based in France.
How we designed scalable infrastructure with cost-efficiency in mind The Kubernetes distribution of Snorkel Flow involves a set of deployments running in a Kubernetes cluster containing pods that run various components of the platform. the orchestrator for our Ray cluster). Pods that are “flexible” can be safely moved to a new node.
Because the models are hosted and deployed on AWS, your data, whether used for evaluating the model or using it at scale, is never shared with third parties. In the AWS Management Console for SageMaker Studio, go to SageMaker JumpStart under Prebuilt and automated solutions.
Don’t worry; you have landed at the right place; in this article, I will give you a crystal clear roadmap to learning data science. Amazon SageMaker is a managed service offered by Amazon Web Services (AWS) that provides a comprehensive platform for building, training, and deploying machine learning models at scale. What to do next?
In this blog, we will review the steps to create Snowflake-managed Iceberg tables with AWS S3 as external storage and read them from a Spark or Databricks environment. To learn more about Iceberg tables in Snowflake, read our article: What are Iceberg Tables in Snowflake and when to use them? What are Iceberg Tables in Snowflake?
Build Classification and Regression Models with Spark on AWS Suman Debnath | Principal Developer Advocate, Data Engineering | Amazon Web Services This immersive session will cover optimizing PySpark and best practices for Spark MLlib. Free and paid passes are available now–register here.
Thrive in the Data Tooling Tornado Adam Breindel | Independent Consultant In this talk, Adam Breindel, a leading Apache Spark instructor and authority on neural-net fraud detection, streaming analytics and cluster management code, will help you navigate the data tooling landscape. NET, and AWS.
Adopted from [link] In this article, we will first briefly explain what ML workflows and pipelines are. By the end of this article, you will be able to identify the key characteristics of each of the selected orchestration tools and pick the one that is best suited for your use case! Programming language: Airflow is very versatile.
This article offers a decent overview of how databases approach the scaling challenge. Graph database performance Search HackerNews and you’ll undoubtedly find a benchmarking article for your preferred graph database, together with comments explaining why it should be disregarded. .”
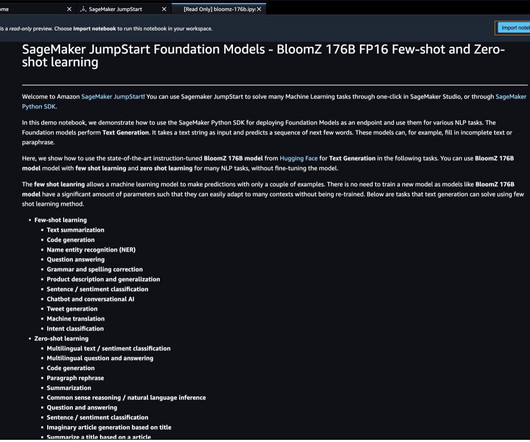
We cover prompts for the following NLP tasks: Text summarization Common sense reasoning Question answering Sentiment classification Translation Pronoun resolution Text generation based on article Imaginary article based on title Code for all the steps in this demo is available in the following notebook. nnWho is he referring to?nn
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content