This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction AWS Glue helps DataEngineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. The post AWS Glue for Handling Metadata appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. The post AWS ECS- Amazon’s Container Tool appeared first on Analytics Vidhya. The post AWS ECS- Amazon’s Container Tool appeared first on Analytics Vidhya. But what exactly are these containers? It only holds […].
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction AWS S3 is one of the object storage services offered by Amazon Web Services or AWS. The post Using AWS S3 with Python boto3 appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Data is the most crucial aspect contributing to the business’s success. Organizations are collecting data at an alarming pace to analyze and derive insights for business enhancements.
This article was published as a part of the Data Science Blogathon. Overview ETL (Extract, Transform, and Load) is a very common technique in dataengineering. The post Crafting Serverless ETL Pipeline Using AWS Glue and PySpark appeared first on Analytics Vidhya. Traditionally, ETL processes are […].
This article was published as a part of the Data Science Blogathon. Introduction Ever wondered how to query and analyze raw data? The post Using AWS Athena and QuickSight for Data Analysis appeared first on Analytics Vidhya. Also, have you ever tried doing this with Athena and QuickSight?
This article was published as a part of the Data Science Blogathon. The post Elastic Load Balancer in AWS and its Benefits appeared first on Analytics Vidhya. Introduction The cloud trend has gained tremendous importance in the technology industry and the field of science in recent years. As a result, cloud services […].
This article was published as a part of the Data Science Blogathon. Businesses of all sizes are switching to the cloud to manage risks, improve data security, streamline processes and decrease costs, or other reasons. The post AWS VPC: Creating Your own Virtual Private Network on Cloud appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. The post AWS Elastic BeanStalk Processing and its Components appeared first on Analytics Vidhya. Introduction If you are a beginner or have little time, configuring the environment for your application may be too complicated and time-consuming.
This article was published as a part of the Data Science Blogathon. convenient Introduction AWS Lambda is a serverless computing service that lets you run code in response to events while having the underlying compute resources managed for you automatically.
This article was published as a part of the Data Science Blogathon. Introduction Amazon Athena is an interactive query service based on open-source Apache Presto that allows you to analyze data stored in Amazon S3 using ANSI SQL directly.
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction Nowadays, a lot of data is being generated and consumed, resulting in a huge amount of internet traffic exponentially across the globe. The post AWS Route 53 – The Efficient DNS Solution appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Overview In this article, we will learn how to run/deploy containerized. The post Deploying Machine learning Application on AWS Fargate appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. It is a Lucene-based search engine developed in Java but supports clients in various languages such as Python, C#, Ruby, and PHP. It takes unstructured data from multiple sources as input and stores it […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon. Introduction Data Lake architecture for different use cases – Elegant. The post A Guide to Build your Data Lake in AWS appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a Data Pipeline with PySpark and AWS appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction Amazon Web Services (AWS) is a cloud computing platform offering a wide range of services coming under domains like networking, storage, computing, security, databases, machine learning, etc.
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction If you are familiar with databases, or data warehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well.
This article was published as a part of the Data Science Blogathon. Businesses have adopted Snowflake as migration from on-premise enterprise data warehouses (such as Teradata) or a more flexibly scalable and easier-to-manage alternative to […].
This article was published as a part of the Data Science Blogathon. In this article, we shall discuss the upcoming innovations in the field of artificial intelligence, big data, machine learning and overall, Data Science Trends in 2022. Times change, technology improves and our lives get better.
ArticleVideo BookThis article was published as a part of the Data Science Blogathon Introduction If you are just starting your journey with Snowflake, then I. The post Demystifying Stages in Snowflake appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Data sharing has become so easy today, and we can share the details with just a few clicks. The post How to Encrypt and Decrypt the Data in PySpark? These details can get leaked if the […].
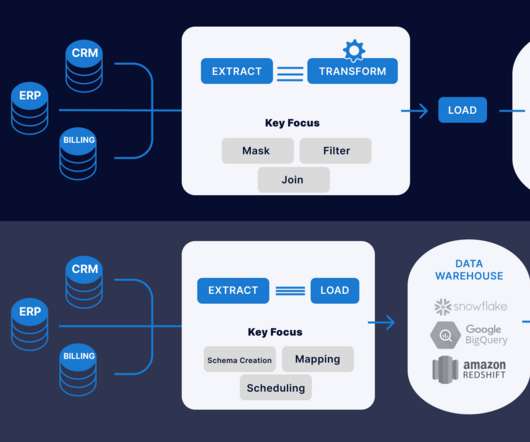
Introduction This article will explain the difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) when data transformation occurs. In ETL, data is extracted from multiple locations to meet the requirements of the target data file and then placed into the file.
This article was published as a part of the Data Science Blogathon. Introduction Are you a Data Science enthusiast or already a Data Scientist who is trying to make his or her portfolio strong by adding a good amount of hands-on projects to your resume? But have no clue where to get the datasets from so […].
Advanced-DataEngineering and ML Ops with Infrastructure as Code This member-only story is on us. Photo by Markus Winkler on Unsplash This story explains how to create and orchestrate machine learning pipelines with AWS Step Functions and deploy them using Infrastructure as Code. Upgrade to access all of Medium.
Customers of every size and industry are innovating on AWS by infusing machine learning (ML) into their products and services. However, implementing security, data privacy, and governance controls are still key challenges faced by customers when implementing ML workloads at scale.
As the demand for the data solutions increased, cloud companies like AWS also jumped in and began providing managed data lake solutions with AWS Athena and S3. In this article, we will discuss shortcomings of indexing in Athena and S3 and how we can deal with them. AWS Athena and S3. Partition limits.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
For the first time ever, the DataEngineering Summit will be in person! Co-located with the leading Data Science and AI Training Conference, ODSC East, this summit will gather the leading minds in DataEngineering in Boston on April 23rd and 24th. NET, and AWS. We’re currently hard at work on the lineup.
Data science and dataengineering are incredibly resource intensive. By using cloud computing, you can easily address a lot of these issues, as many data science cloud options have databases on the cloud that you can access without needing to tinker with your hardware.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
However, extracting valuable insights from the vast amount of data stored in ServiceNow often requires manual effort and building specialized tooling. For a full list of Amazon Q business supported data source connectors, see Amazon Q Business connectors.
Dataengineering has become an integral part of the modern tech landscape, driving advancements and efficiencies across industries. So let’s explore the world of open-source tools for dataengineers, shedding light on how these resources are shaping the future of data handling, processing, and visualization.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
In this article, we will highlight the key elements when it comes to process mining architectures as well as the most common mistakes, to help organizations leverage the power of process mining while maintain cost control. By utilizing these services, organizations can store large volumes of event data without incurring substantial expenses.
Welcome to Beyond the Data, a curious series that investigates the people behind the talent of phData. In this article, we’re featuring Deepa Ganiger, who serves as a Solution Architect/Lead DataEngineer at phData. What do you actually do on any given day as a Solution Architect/Lead DataEngineer?
This approach can help heart stroke patients, doctors, and researchers with faster diagnosis, enriched decision-making, and more informed, inclusive research work on stroke-related health issues, using a cloud-native approach with AWS services for lightweight lift and straightforward adoption. Stroke victims can lose around 1.9
Be sure to check out his talk, “ Build Classification and Regression Models with Spark on AWS ,” there! In the unceasingly dynamic arena of data science, discerning and applying the right instruments can significantly shape the outcomes of your machine learning initiatives. A cordial greeting to all data science enthusiasts!
Scale is worth knowing if you’re looking to branch into dataengineering and working with big data more as it’s helpful for scaling applications. Cloud Services The only two to make multiple lists were Amazon Web Services (AWS) and Microsoft Azure.
Cloud Computing, APIs, and DataEngineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. DataEngineering Platforms Spark is still the leader for data pipelines but other platforms are gaining ground. Google Cloud is starting to make a name for itself as well.
About the Authors Ori Nakar is a Principal cyber-security researcher, a dataengineer, and a data scientist at Imperva Threat Research group. Eitan Sela is a Generative AI and Machine Learning Specialist Solutions Architect at AWS. In his spare time, Eitan enjoys jogging and reading the latest machine learning articles.
With data science and analytics reshaping industries, understanding the distinction between Business Analytics and Data Science is crucial for anyone navigating a career in this field. According to the US Bureau of Labor Statistics, jobs requiring data science skills will grow by 27.9%
Furthermore, the dynamic nature of a customer’s data can also result in a large variance of the processing time and resources required to optimally complete the feature engineering. AWS customer Vericast is a marketing solutions company that makes data-driven decisions to boost marketing ROIs for its clients.
Refer to Unlocking the Power of Big DataArticle to understand the use case of these data collected from various sources. Data Ingestion: Data is collected and funneled into the pipeline using batch or real-time methods, leveraging tools like Apache Kafka, AWS Kinesis, or custom ETL scripts.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content