This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Overview ETL (Extract, Transform, and Load) is a very common technique in data engineering. Traditionally, ETL processes are […]. Traditionally, ETL processes are […].
This article was published as a part of the Data Science Blogathon. Introduction AWS Glue helps Data Engineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. The post AWS Glue for Handling Metadata appeared first on Analytics Vidhya.
Introduction Apache Airflow is a powerful platform that revolutionizes the management and execution of Extracting, Transforming, and Loading (ETL) data processes. This article explores the intricacies of automating ETL pipelines using Apache Airflow on AWS EC2.
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction If you are familiar with databases, or data warehouses, you have probably heard the term “ETL.” The post AWS Glue: Simplifying ETL Data Processing appeared first on Analytics Vidhya. For the […].
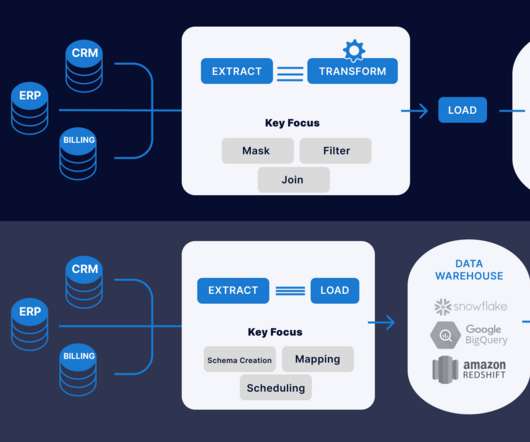
Introduction This article will explain the difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) when data transformation occurs. In ETL, data is extracted from multiple locations to meet the requirements of the target data file and then placed into the file.
Photo by Caspar Camille Rubin on Unsplash AWS Athena is a serverless interactive query system. The sample data used in this article can be downloaded from the link below, Fruit and Vegetable Prices How much do fruits and vegetables cost? Go to the AWS Glue Console. Create a Glue Job to perform ETL operations on your data.
Summary: Selecting the right ETL platform is vital for efficient data integration. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes. What is ETL in Data Integration? Let’s explore some real-world applications of ETL in different sectors.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
Writing data to an AWS data lake and retrieving it to populate an AWS RDS MS SQL database involves several AWS services and a sequence of steps for data transfer and transformation. This process leverages AWS S3 for the data lake storage, AWS Glue for ETL operations, and AWS Lambda for orchestration.
In this article, we will discover how to build an ETL pipeline by consuming data from S3 to AWS Redshift via the Glue service and… Continue reading on MLearning.ai »
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Overview of RAG The RAG pattern lets you retrieve knowledge from external sources, such as PDF documents, wiki articles, or call transcripts, and then use that knowledge to augment the instruction prompt sent to the LLM. For more information about AWS CDK installation, refer to Getting started with the AWS CDK.
In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. Extract, transform and Load Before we begin, let’s shed some light on what an ETL pipeline essentially is. One of them is Azure functions.
With a multitude of articles, videos, audio recordings, and other media created daily across news media companies, readers of all types—individual consumers, corporate subscribers, and more—often find it difficult to find news content that is most relevant to them. We describe how to mitigate this limitation later in this post.
Big data pipelines operate similarly to traditional ETL (Extract, Transform, Load) pipelines but are designed to handle much larger data volumes. Refer to Unlocking the Power of Big Data Article to understand the use case of these data collected from various sources.
Photo by Jeroen den Otter on Unsplash Who should read this article: Machine and Deep Learning Engineers, Solution Architects, Data Scientist, AI Enthusiast, AI Founders What is covered in this article? This article explains how to build a continuous and automated model training pipeline.
In this article, we will highlight the key elements when it comes to process mining architectures as well as the most common mistakes, to help organizations leverage the power of process mining while maintain cost control. What makes the difference is a smart ETL design capturing the nature of process mining data.
This article is a real-life study of building a CI/CD MLOps pipeline. AWS provides several tools to create and manage ML model deployments. 2 If you are somewhat familiar with AWS ML base tools, the first thing that comes to mind is “Sagemaker”. An example would be AWS recognition. S3 buckets.
This article will explore popular data transformation tools, highlighting their key features and how they can enhance data processing in various applications. Typical use cases include ETL (Extract, Transform, Load) tasks, data quality enhancement, and data governance across various industries. What is Data Transformation?
billion 50,067 million 50.067 billion What were Amazon’s AWS sales for the second quarter of 2023? Amazon’s AWS sales for the second quarter of 2023 were $22.1 foreign exchange rates 0 0 0 What were Amazon’s AWS sales for the second quarter of 2023? Amazon’s AWS sales for the second quarter of 2023 were $22.1
These areas may include SQL, database design, data warehousing, distributed systems, cloud platforms (AWS, Azure, GCP), and data pipelines. ETL (Extract, Transform, Load) This is a core data engineering process for moving data from one or more sources to a destination, typically a data warehouse or data lake. First, articles.
Cloud Storage Upload Snowflake can easily upload files from cloud storage (AWS S3, Azure Storage, GCP Cloud Storage). Snowflake can not natively read files on these services, so an ETL service is needed to upload the data. ETL applications are often expensive and require some level of expertise to run. What is Reference Data?
Matillion Matillion is a complete ETL tool that integrates with an extensive list of pre-built data source connectors, loads data into cloud data environments such as Snowflake, and then performs transformations to make data consumable by analytics tools such as Tableau and PowerBI. The biggest reason is the ease of use.
sales conversation summaries, insurance coverage, meeting transcripts, contract information) Generate: Generate text content for a specific purpose, such as marketing campaigns, job descriptions, blogs or articles, and email drafting support.
A quick note: the focus of this article is not to discuss the intricacies of crypto trading per se (an economic perspective, so to say) but rather to talk about how we used the best practices of the MLOps methodology to lead a transformation process for a company working in one of the most technically and computationally demanding fields.
Data Wrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis. Competence in data quality, databases, and ETL (Extract, Transform, Load) are essential. Cloud Services: Google Cloud Platform, AWS, Azure.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Integration and ETL (Extract, Transform, Load) Data Engineers develop and manage data pipelines that extract data from various sources, transform it into a suitable format, and load it into the destination systems.
In this article, we’ll focus on a data lake vs. data warehouse. Processing speeds were considerably slower than they are today, so large volumes of data called for an approach in which data was staged in advance, often running ETL (extract, transform, load) processes overnight to enable next-day visibility to key performance indicators.
This article explores the key fundamentals of Data Engineering, highlighting its significance and providing a roadmap for professionals seeking to excel in this vital field. Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load. ETL is vital for ensuring data quality and integrity.
This article endeavors to alleviate those confusions. While traditional data warehouses made use of an Extract-Transform-Load (ETL) process to ingest data, data lakes instead rely on an Extract-Load-Transform (ELT) process. This adds an additional ETL step, making the data even more stale. The concepts will be explained.
In recent years, data engineering teams working with the Snowflake Data Cloud platform have embraced the continuous integration/continuous delivery (CI/CD) software development process to develop data products and manage ETL/ELT workloads more efficiently.
Some of the popular cloud-based vendors are: Hevo Data Equalum AWS DMS On the other hand, there are vendors offering on-premise data pipeline solutions and are mostly preferred by organizations dealing with highly sensitive data. Pricing It is free to use and is licensed under Apache License Version 2.0.
Adopted from [link] In this article, we will first briefly explain what ML workflows and pipelines are. By the end of this article, you will be able to identify the key characteristics of each of the selected orchestration tools and pick the one that is best suited for your use case! Programming language: Airflow is very versatile.
And because it takes more than technologies and processes to succeed with MLOps, he will also share details on: 1 Brainly’s ML use cases, 2 MLOps culture, 3 Team structure, 4 And technologies Brainly uses to deliver AI services to its clients, Enjoy the article! quality attributes) and metadata enrichment (e.g.,
This article aims to guide you through the intricacies of Data Analyst interviews, offering valuable insights with a comprehensive list of top questions. By the end of this article, you’ll explore data analytics certification courses that will significantly help you advance your career in the data domain.
In this article, we’ll explore how AI can transform unstructured data into actionable intelligence, empowering you to make informed decisions, enhance customer experiences, and stay ahead of the competition. These capture the semantic relationships between words, facilitating tasks like classification and clustering within ETL pipelines.
In this article, we will discuss the importance of data versioning control in machine learning and explore various methods and tools for implementing it with different types of data sources. It supports most major cloud providers, such as AWS, GCP, and Azure. The remote repository can be on the same computer, or it can be on the cloud.
And that’s what we’re going to focus on in this article, which is the second in my series on Software Patterns for Data Science & ML Engineering. In this article, we’ll talk about Jupyter notebooks specifically from a business and product point of view. There are some outspoken critics , as well as passionate fans.
This article will discuss managing unstructured data for AI and ML projects. is similar to the traditional Extract, Transform, Load (ETL) process. Tooling : Apache Tika , ElasticSearch , Databricks , and AWS Glue for metadata extraction and management. How to properly manage unstructured data. Unstructured.io
This article was originally an episode of the ML Platform Podcast , a show where Piotr Niedźwiedź and Aurimas Griciūnas, together with ML platform professionals, discuss design choices, best practices, example tool stacks, and real-world learnings from some of the best ML platform professionals. Or did you call them something different here?
If prompted, set up a user profile for SageMaker Studio by providing a user name and specifying AWS Identity and Access Management (IAM) permissions. AWS SDKs and authentication Verify that your AWS credentials (usually from the SageMaker role) have Amazon Bedrock access. Open a SageMaker Studio notebook: Choose JupyterLab.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content