This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
80% of the time goes in datapreparation ……blah blah…. In short, the whole datapreparation workflow is a pain, with different parts managed or owned by different teams or people distributed across different geographies depending upon the company size and data compliances required. What is the problem statement?
The Datamarts capability opens endless possibilities for organizations to achieve their data analytics goals on the Power BI platform. This article is an excerpt from the book Expert Data Modeling with Power BI, Third Edition by Soheil Bakhshi, a completely updated and revised edition of the bestselling guide to Power BI and data modeling.
Given they’re built on deep learning models, LLMs require extraordinary amounts of data. Regardless of where this data came from, managing it can be difficult. MLOps is also ideal for data versioning and tracking, so the data scientists can keep track of different iterations of the data used for training and testing LLMs.
Image generated by Gemini Spark is an open-source distributed computing framework for high-speed data processing. It is widely supported by platforms like GCP and Azure, as well as Databricks, which was founded by the creators of Spark. This practice vastly enhances the speed of my datapreparation for machine learning projects.
It covers everything from datapreparation and model training to deployment, monitoring, and maintenance. Empowering Startups and Entrepreneurs | InvestBegin.com | investbegin In this article, we will explore the various aspects of MLOps projects, including the challenges they face and the tools and techniques used to overcome them.
Tutorials Microsoft Azure Machine Learning Microsoft Azure Machine Learning (Azure ML) is a cloud-based platform for building, training, and deploying machine learning models. Azure ML integrates seamlessly with other Microsoft Azure services, offering scalability, security, and advanced analytics capabilities.
You have to learn only those parts of technology that are useful in data science as well as help you land a job. Don’t worry; you have landed at the right place; in this article, I will give you a crystal clear roadmap to learning data science. Because this is the only effective way to learn Data Analysis.
BPCS’s deep understanding of Databricks can help organizations of all sizes get the most out of the platform, with services spanning data migration, engineering, science, ML, and cloud optimization. HPCC is a high-performance computing platform that helps organizations process and analyze large amounts of data.
Preparing for Power BI interviews is paramount, given the competitive landscape. In earlier articles, you read about creating a heatmap in Power BI and a complete PowerBI tutorial. This article aims to unravel the mysteries surrounding common, complex, and highly challenging Power BI interview questions. Lakhs to ₹9.0
{This article was written without the assistance or use of AI tools, providing an authentic and insightful exploration of PyCaret} Image by Author In the rapidly evolving realm of data science, the imperative to automate machine learning workflows has become an indispensable requisite for enterprises aiming to outpace their competitors.
A traditional machine learning (ML) pipeline is a collection of various stages that include data collection, datapreparation, model training and evaluation, hyperparameter tuning (if needed), model deployment and scaling, monitoring, security and compliance, and CI/CD.
AI in Excel enhances productivity by automating tasks like Data Analysis, forecasting, and report generation. This article explores how to use AI in Excel for smart solutions, highlighting key AI features and tools that boost productivity. Here’s how various AI tools integrate with Excel to boost productivity and efficiency.
With SageMaker JumpStart, you can evaluate, compare, and select foundation models (FMs) quickly based on predefined quality and responsibility metrics to perform tasks such as article summarization and image generation. Baseline testing Use the question set to test the pre-trained model, establishing a performance baseline.
Strategy After researching various approaches, this research article, ‘ Animal Sound Classification Using A Convolutional Neural Network’ intrigued me and I began to study various approaches. Sample Data By using image_location, I am able to store images on disk as opposed to loading all the images in memory.
The global Big Data and Data Engineering Services market, valued at USD 51,761.6 This article explores the key fundamentals of Data Engineering, highlighting its significance and providing a roadmap for professionals seeking to excel in this vital field. million by 2028.
A small portion of the LLM ecosystem; image from scalevp.com In this article, we will provide a comprehensive guide to training, deploying, and improving LLMs. In this article, we will explore the essential steps involved in training LLMs, including datapreparation, model selection, hyperparameter tuning, and fine-tuning.
To provide you with a comprehensive overview, this article explores the key players in the MLOps and FMOps (or LLMOps) ecosystems, encompassing both open-source and closed-source tools, with a focus on highlighting their key features and contributions. Check out the documentation to get started.
The role of prompt engineer has attracted massive interest ever since Business Insider released an article last spring titled “ AI ‘Prompt Engineer Jobs: $375k Salary, No Tech Backgrund Required.” Sagemaker: Provides a cloud-based platform for fine-tuning and deploying LLM models, simplifying workflow and resource management.
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Nevertheless, many data scientists will agree that they can be really valuable – if used well. And that’s what we’re going to focus on in this article, which is the second in my series on Software Patterns for Data Science & ML Engineering. in a pandas DataFrame) but in the company’s data warehouse (e.g.,
In this article, I will share my learnings of how successful ML platforms work in an eCommerce and what are the best practices a Team needs to follow during the course of building it. The objective of an ML Platform is to automate repetitive tasks and streamline the processes starting from datapreparation to model deployment and monitoring.
Data science teams currently struggle with managing multiple experiments and models and need an efficient way to store, retrieve, and utilize details like model versions, hyperparameters, and performance metrics. Different tools: Your repository consists of multiple tools, libraries, and infrastructure providers like Azure, AWS, and GCP.
The article also addresses challenges like data quality and model complexity, highlighting the importance of ethical considerations in Machine Learning applications. Key steps involve problem definition, datapreparation, and algorithm selection. Data quality significantly impacts model performance.
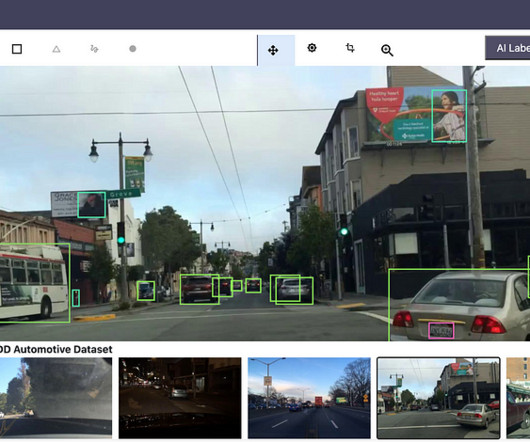
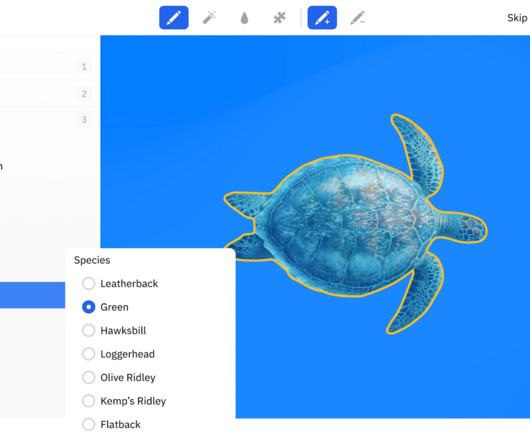
Errors and inconsistencies in the annotated data often lead to noisy data that increases the likelihood of bias and limits the model’s ability to generalize. In this article, you will learn about the importance of image annotation and what you should know for annotating image files for machine learning at scale.
High demand has risen from a range of sectors, including crypto mining, gaming, generic data processing, and AI. Historical data is normally (but not always) independent inter-day, meaning that days can be parsed independently. The same WSJ article states “No one alpha is important.
The financial implications of developing and deploying LLMs are considerable, with costs encompassing data acquisition, computational power, and ongoing maintenance. Code and Content Generation : LLMs can facilitate the generation of written content such as articles, reports, and narratives.
Whether its crafting SEO-optimized articles or personalized email drafts, Jasper accelerates content workflows while maintaining human-like fluency. From customer service chatbots to data-driven decision-making , Watson enables businesses to extract insights from large-scale datasets with precision.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content