This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction Dear DataEngineers, this article is a very interesting topic. Let me give some flashback; a few years ago, Mr.Someone in the discussion coined the new word how ACID and BASE properties of DATA. Everyone started […].
This article was published as a part of the Data Science Blogathon. Introduction In today’s era, CloudComputing has become a basic need for every startup or business. Now, developers can quickly develop their applications in the cloud and present them to the end users. Hardware Security: […].
This article was published as a part of the Data Science Blogathon. Introduction The cloud trend has gained tremendous importance in the technology industry and the field of science in recent years. As a result, cloud services […].
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction Amazon Web Services (AWS) is a cloudcomputing platform offering a wide range of services coming under domains like networking, storage, computing, security, databases, machine learning, etc.
This article was published as a part of the Data Science Blogathon. Introduction There are several reasons organizations should use cloudcomputing in the modern world. Businesses of all sizes are switching to the cloud to manage risks, improve data security, streamline processes and decrease costs, or other reasons.
This article was published as a part of the Data Science Blogathon. Introduction AWS Glue helps DataEngineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. It provides organizations with […].
This article was published as a part of the Data Science Blogathon. Overview ETL (Extract, Transform, and Load) is a very common technique in dataengineering. Traditionally, ETL processes are […].
A recent article on Analytics Insight explores the critical aspect of dataengineering for IoT applications. Understanding the intricacies of dataengineering empowers data scientists to design robust IoT solutions, harness data effectively, and drive innovation in the ever-expanding landscape of connected devices.
The data architect job description has become one of the most sought-after jobs on the internet. Data-related jobs are on the rise in today’s data-driven world. We have already explained cloudcomputing job requirements and business intelligence analyst skills in these articles.
This article was published as a part of the Data Science Blogathon. Introduction I’ve always wondered how big companies like Google process their information or how companies like Netflix can perform searches in concise times.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
This article was published as a part of the Data Science Blogathon. Introduction Processing large amounts of raw data from various sources requires appropriate tools and solutions for effective data integration. Building an ETL pipeline using Apache […].
This article was published as a part of the Data Science Blogathon. In this article, we shall discuss the upcoming innovations in the field of artificial intelligence, big data, machine learning and overall, Data Science Trends in 2022. Times change, technology improves and our lives get better.
This article was published as a part of the Data Science Blogathon. It aims to overcome some of the primary drawbacks and flaws of the present internet era by tackling the crucial concerns of data ownership […]. revolution.
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction AWS S3 is one of the object storage services offered by Amazon Web Services or AWS. It allows users to store and retrieve files quickly and securely from anywhere.
This article was published as a part of the Data Science Blogathon. Source: techdemand.io Introduction Web 3.0 may be just as disruptive and usher in a huge paradigm change as Web 2.0. is based on the fundamental concepts of decentralization, openness, and increased consumer utility. often known as Web 3, is […].
This article was published as a part of the Data Science Blogathon. Introduction If you are a beginner or have little time, configuring the environment for your application may be too complicated and time-consuming. You need to consider monitoring, logs, security groups, VMs, backups, etc.
This article was published as a part of the Data Science Blogathon. Introduction A platform for augmented reality called Metaverse enables users to build interactive experiences that combine the virtual and real worlds. Additionally, it can be considered a virtual version of the concept or idea of cyberspace.
This article was published as a part of the Data Science Blogathon. Introduction Currently, most businesses and big-scale companies are generating and storing a large amount of data in their data storage. Many companies are there which are completely data-driven.
This article was published as a part of the Data Science Blogathon. Introduction Data lineage is the process of analyzing the path of the data and how it is involved in different methods with time. Many businesses and companies use it to get an idea of the source, data pathway, and how the data is […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction A Data Warehouse is Built by combining data from multiple. The post A Brief Introduction to the Concept of Data Warehouse appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. convenient Introduction AWS Lambda is a serverless computing service that lets you run code in response to events while having the underlying compute resources managed for you automatically.
This article was published as a part of the Data Science Blogathon. Source:javaguides.net Introduction Spring Boot is an application developed on top of the Spring Framework. It makes it simpler and faster to install, set up, and execute both basic and web-based apps.
This article was published as a part of the Data Science Blogathon. Introduction Data sharing has become so easy today, and we can share the details with just a few clicks. The post How to Encrypt and Decrypt the Data in PySpark? These details can get leaked if the […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon In this article, we will learn to connect the Snowflake database. The post One-stop-shop for Connecting Snowflake to Python! appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Tourism Management System is an integrated software developed for tourism. The post Beginner’s Guide to Cloud based Tourism Management System appeared first on Analytics Vidhya.
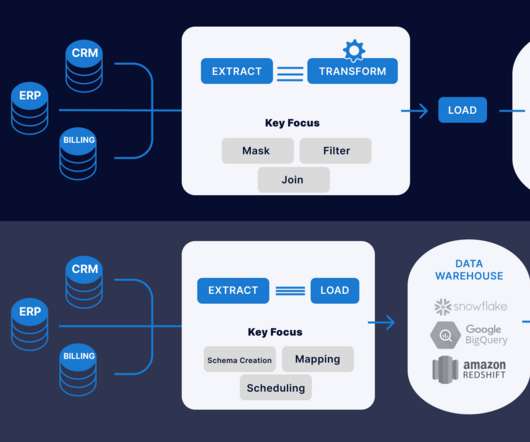
Introduction This article will explain the difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) when data transformation occurs. In ETL, data is extracted from multiple locations to meet the requirements of the target data file and then placed into the file.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction In this article, I will be demonstrating how to deploy. The post Deploying PySpark Machine Learning models with Google Cloud Platform using Streamlit appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. It aims to replace conventional backend servers for web and mobile applications by offering multiple services on the same platform like authentication, real-time database, Firestore (NoSQL database), cloud functions, […].
This article was published as a part of the Data Science Blogathon. It is a Lucene-based search engine developed in Java but supports clients in various languages such as Python, C#, Ruby, and PHP. It takes unstructured data from multiple sources as input and stores it […].
This article was published as a part of the Data Science Blogathon. Introduction Are you a Data Science enthusiast or already a Data Scientist who is trying to make his or her portfolio strong by adding a good amount of hands-on projects to your resume? But have no clue where to get the datasets from so […].
This article was published as a part of the Data Science Blogathon. Introduction Have you ever wondered how websites track user interactions? Must be pretty hard, isn’t it? Well, yes and no. Simple tracking ? super easy but advanced level tracking can send your mind for a six if things don’t work as expected. In […].
This article was published as a part of the Data Science Blogathon. As we all have observed, the growth of data how helps the companies to get insights into data, and that insight is used for the growth of Business. Introduction An ultimate beginners guide on Apache Spark & RDDs!
This article was published as a part of the Data Science Blogathon. Introduction Let’s say you want to create some clusters as fast as possible with less money. What services will you choose? This is when Google Dataproc became the ideal tool that disables clusters when not in use and saves you money and time. […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Amazon Redshift is a data warehouse service in the cloud. The post Understand All About Amazon Redshift! appeared first on Analytics Vidhya.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Data science and dataengineering are incredibly resource intensive. By using cloudcomputing, you can easily address a lot of these issues, as many data science cloud options have databases on the cloud that you can access without needing to tinker with your hardware.
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction If you are familiar with databases, or data warehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well.
In this article, we will highlight the key elements when it comes to process mining architectures as well as the most common mistakes, to help organizations leverage the power of process mining while maintain cost control. Cloud-Based infrastructure with process mining?
Computer science, math, statistics, programming, and software development are all skills required in NLP projects. CloudComputing, APIs, and DataEngineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops.
Other challenges include communicating results to non-technical stakeholders, ensuring data security, enabling efficient collaboration between data scientists and dataengineers, and determining appropriate key performance indicator (KPI) metrics.
This article explores the top 10 AI jobs in India and the essential skills required to excel in these roles. Proficiency in Data Analysis tools for market research. DataEngineerDataEngineers build the infrastructure that allows data generation and processing at scale. million by 2027.
In this article, I will explain the modern data stack in detail, list some benefits, and discuss what the future holds. What Is the Modern Data Stack? The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform.
To provide you with a comprehensive overview, this article explores the key players in the MLOps and FMOps (or LLMOps) ecosystems, encompassing both open-source and closed-source tools, with a focus on highlighting their key features and contributions. This provides end-to-end support for dataengineering and MLOps workflows.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content