This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Building an ETL pipeline using Apache […]. Building an ETL pipeline using Apache […]. The post ETL Pipeline with Google DataFlow and Apache Beam appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Overview ETL (Extract, Transform, and Load) is a very common technique in data engineering. Traditionally, ETL processes are […]. Traditionally, ETL processes are […].
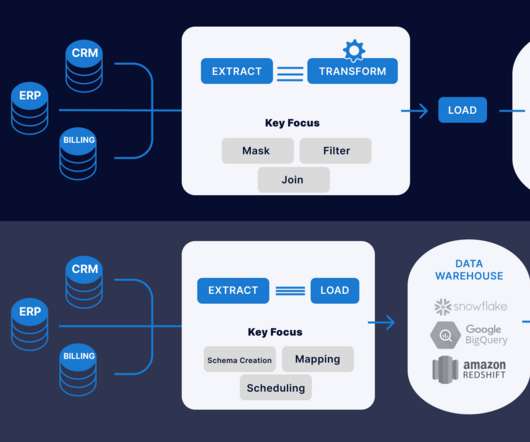
Introduction This article will explain the difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) when data transformation occurs. In ETL, data is extracted from multiple locations to meet the requirements of the target data file and then placed into the file.
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction If you are familiar with databases, or data warehouses, you have probably heard the term “ETL.” The post AWS Glue: Simplifying ETL Data Processing appeared first on Analytics Vidhya. For the […].
Introduction Apache Airflow is a powerful platform that revolutionizes the management and execution of Extracting, Transforming, and Loading (ETL) data processes. This article explores the intricacies of automating ETL pipelines using Apache Airflow on AWS EC2.
This article was published as a part of the Data Science Blogathon. Introduction AWS Glue helps Data Engineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. The managed service offers a simple and cost-effective method of categorizing and managing big data in an enterprise.
In this article, we will highlight the key elements when it comes to process mining architectures as well as the most common mistakes, to help organizations leverage the power of process mining while maintain cost control. Cloud-Based infrastructure with process mining?
In this article, I will explain the modern data stack in detail, list some benefits, and discuss what the future holds. The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. Reverse ETL tools. A Note on the Shift from ETL to ELT.
This entails the use of other technologies such as distributed computing, edge computing, and cloudcomputing. When it comes to data integration, RTOS can work with systems that employ data warehousing, API management, and ETL technologies. Moreover, RTOS is built to be scalable and flexible.
As cloudcomputing platforms make it possible to perform advanced analytics on ever larger and more diverse data sets, new and innovative approaches have emerged for storing, preprocessing, and analyzing information. In this article, we’ll focus on a data lake vs. data warehouse.
This involves working with various tools and technologies, such as ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) processes, to move data from its source to its destination. Cloudcomputing: Cloudcomputing provides a scalable and cost-effective solution for managing and processing large volumes of data.
This article explores the key fundamentals of Data Engineering, highlighting its significance and providing a roadmap for professionals seeking to excel in this vital field. Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load. ETL is vital for ensuring data quality and integrity.
The inherent cost of cloudcomputing : To illustrate the point, Argentina’s minimum wage is currently around 200 dollars per month. And that’s when what usually happens, happened: We came for the ML models, we stayed for the ETLs. But even when the ETLs were well thought out, they were a bit “outdated” in their approach.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content