This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Image Source: GitHub Table of Contents What is DataEngineering? The post How to Implement DataEngineering in Practice? Initially, we have the definition of Software […]. Initially, we have the definition of Software […].
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a centralized repository for storing, processing, and securing massive amounts of structured, semi-structured, and unstructured data. DataLakes are an important […].
This article was published as a part of the Data Science Blogathon. Introduction Today, DataLake is most commonly used to describe an ecosystem of IT tools and processes (infrastructure as a service, software as a service, etc.) that work together to make processing and storing large volumes of data easy.
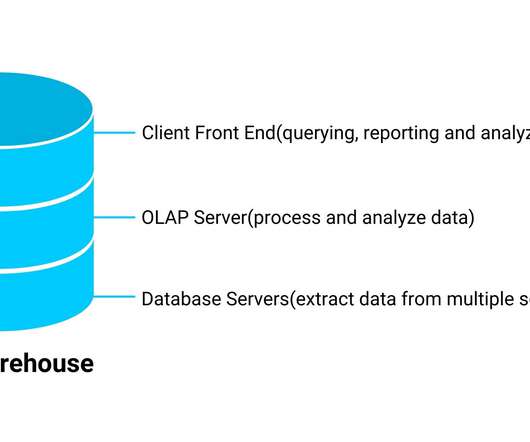
By their definition, the types of data it stores and how it can be accessible to users differ. This article will discuss some of the features and applications of data warehouses, data marts, and data […]. The post Data Warehouses, Data Marts and DataLakes appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Data is defined as information that has been organized in a meaningful way. Data collection is critical for businesses to make informed decisions, understand customers’ […]. The post DataLake or Data Warehouse- Which is Better?
ArticleVideo Book This article was published as a part of the Data Science Blogathon. Introduction DataLake architecture for different use cases – Elegant. The post A Guide to Build your DataLake in AWS appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a central data repository that allows us to store all of our structured and unstructured data on a large scale. The post A Detailed Introduction on DataLakes and Delta Lakes appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. The post How a Delta Lake is Process with Azure Synapse Analytics appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Most of you would know the different approaches for building a data and analytics platform. You would have already worked on systems that used traditional warehouses or Hadoop-based datalakes. Selecting one among […].
This article was published as a part of the Data Science Blogathon. Introduction In the modern data world, Lakehouse has become one of the most discussed topics for building a data platform.
A recent article on Analytics Insight explores the critical aspect of dataengineering for IoT applications. Understanding the intricacies of dataengineering empowers data scientists to design robust IoT solutions, harness data effectively, and drive innovation in the ever-expanding landscape of connected devices.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
In today’s rapidly evolving digital landscape, seamless data, applications, and device integration are more pressing than ever. Enter Microsoft Fabric, a cutting-edge solution designed to revolutionize how we interact with technology.
to store and analyze this data to get valuable business insights from it. You will study top 11 azure interview questions in this article which will discuss different data services like Azure Cosmos […] The post Top 11 Azure Data Services Interview Questions in 2023 appeared first on Analytics Vidhya.
To make your data management processes easier, here’s a primer on datalakes, and our picks for a few datalake vendors worth considering. What is a datalake? First, a datalake is a centralized repository that allows users or an organization to store and analyze large volumes of data.
Introduction Enterprises have been building data platforms for the last few decades, and data architectures have been evolving. Let’s first look at how things have changed and how […].
Traditional relational databases provide certain benefits, but they are not suitable to handle big and various data. That is when datalake products started gaining popularity, and since then, more companies introduced lake solutions as part of their data infrastructure. AWS Athena and S3. How to improve indexing.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
We’ve just wrapped up our first-ever DataEngineering Summit. If you weren’t able to make it, don’t worry, you can watch the sessions on-demand and keep up-to-date on essential dataengineering tools and skills. It also addresses the strategies and best practices for implementing a data mesh.
Dataengineering is a hot topic in the AI industry right now. And as data’s complexity and volume grow, its importance across industries will only become more noticeable. But what exactly do dataengineers do? So let’s do a quick overview of the job of dataengineer, and maybe you might find a new interest.
Data and governance foundations – This function uses a data mesh architecture for setting up and operating the datalake, central feature store, and data governance foundations to enable fine-grained data access. This framework considers multiple personas and services to govern the ML lifecycle at scale.
We couldn’t be more excited to announce the first sessions for our second annual DataEngineering Summit , co-located with ODSC East this April. Join us for 2 days of talks and panels from leading experts and dataengineering pioneers. Is Gen AI A DataEngineering or Software Engineering Problem?
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
The Future of the Single Source of Truth is an Open DataLake Organizations that strive for high-performance data systems are increasingly turning towards the ELT (Extract, Load, Transform) model using an open datalake.
These data requirements could be satisfied with a strong data governance strategy. Governance can — and should — be the responsibility of every data user, though how that’s achieved will depend on the role within the organization. This article will focus on how dataengineers can improve their approach to data governance.
The success of any data initiative hinges on the robustness and flexibility of its big data pipeline. What is a Data Pipeline? A traditional data pipeline is a structured process that begins with gathering data from various sources and loading it into a data warehouse or datalake.
Data Mesh More data management systems in 2023 will also shift toward a data mesh architecture. This decentralized architecture breaks datalakes into smaller domains specific to a given team or department. Observability means ensuring databases are transparent, accurate and high-quality.
DataEngineerDataengineers are responsible for the end-to-end process of collecting, storing, and processing data. They use their knowledge of data warehousing, datalakes, and big data technologies to build and maintain data pipelines. So what are you waiting for?
Big data isn’t an abstract concept anymore, as so much data comes from social media, healthcare data, and customer records, so knowing how to parse all of that is needed. This pushes into big data as well, as many companies now have significant amounts of data and large datalakes that need analyzing.
Beyond his technical achievements, James is a sought-after speaker and is a prolific voice in the data community through his blog, JamesSerra.com. James Serra discusses data lakehouses, which merge datalakes and data warehouses. It lets you store a wide variety of data in a cost-effective way, like a datalake.
Editor’s note: This article originally appeared in Forbes. I think one of the most important things I see people do right, is to make sure that you build the data foundation from the ground up correctly,” said Ali Ghodsi, CEO of Databricks. Vidya Setlur. Director of Research, Tableau. Kristin Adderson. February 14, 2022 - 6:11pm.
Editor’s note: This article originally appeared in Forbes. I think one of the most important things I see people do right, is to make sure that you build the data foundation from the ground up correctly,” said Ali Ghodsi, CEO of Databricks. Vidya Setlur. Director of Research, Tableau. Kristin Adderson. February 14, 2022 - 6:11pm.
Our goal was to improve the user experience of an existing application used to explore the counters and insights data. The data is stored in a datalake and retrieved by SQL using Amazon Athena. In his spare time, Eitan enjoys jogging and reading the latest machine learning articles.
As data is the foundation of any machine learning project, it is essential to have a system in place for tracking and managing changes to data over time. However, data versioning control is frequently given little attention, leading to issues such as data inconsistencies and the inability to reproduce results.
In a prior blog , we pointed out that warehouses, known for high-performance data processing for business intelligence, can quickly become expensive for new data and evolving workloads. To do so, Presto and Spark need to readily work with existing and modern data warehouse infrastructures.
Managing unstructured data is essential for the success of machine learning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. This article will discuss managing unstructured data for AI and ML projects. How to properly manage unstructured data.
In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. EL stands for extract and load, and its primary goal is to just move the data from one place to another where the destination is usually a Data Warehouse or a DataLake.
Modern data catalogs surface a wide range of data asset types. For instance, Alation can return wiki-like articles, conversations, and business intelligence objects, in addition to traditional tables. Modern data catalogs also facilitate data quality checks. Communicate and Visualize Results.
HPCC Systems — The Kit and Kaboodle for Big Data and Data Science Bob Foreman | Software Engineering Lead | LexisNexis/HPCC Join this session to learn how ECL can help you create powerful data queries through a comprehensive and dedicated datalake platform.
To provide you with a comprehensive overview, this article explores the key players in the MLOps and FMOps (or LLMOps) ecosystems, encompassing both open-source and closed-source tools, with a focus on highlighting their key features and contributions. For example, neptune.ai
Data Morph: A Cautionary Tale of Summary Statistics Visualization in Bayesian Workflow Using Python or R Harnessing Bayesian Statistics for Business-Centric Data Science DataEngineering and Big Data Join this track to learn the latest techniques and processes to analyze raw data and automate data into mechanical processes and algorithms.
Using Azure ML to Train a Serengeti Data Model, Fast Option Pricing with DL, and How To Connect a GPU to a Container Using Azure ML to Train a Serengeti Data Model for Animal Identification In this article, we will cover how you can train a model using Notebooks in Azure Machine Learning Studio. Check a few of them out here.
sales conversation summaries, insurance coverage, meeting transcripts, contract information) Generate: Generate text content for a specific purpose, such as marketing campaigns, job descriptions, blogs or articles, and email drafting support.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content