This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
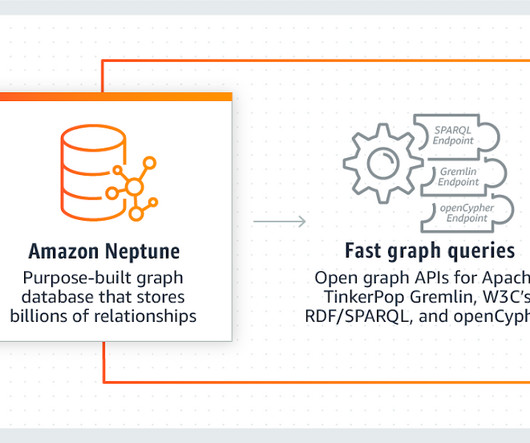
Traditional databases, while still valuable, often falter when it comes to handling highly connected data. Enter the unsung heroes of the data world: graph databases. These powerful tools are designed to manage and query intricate data relationships effortlessly.
This article was published as a part of the Data Science Blogathon. Introduction In this article, we will be looking for a very common yet very important topic i.e. SQL also pronounced as Ess-cue-ell. The post Introduction to SQL for DataEngineering appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction When creating data pipelines, Software Engineers and DataEngineers frequently work with databases using Database Management Systems like PostgreSQL.
This article was published as a part of the Data Science Blogathon. Introduction A data model is an abstraction of real-world events that we use to create, capture, and store data in a database that user applications require, omitting unnecessary details.
This article was published as a part of the Data Science Blogathon. Introduction Have you ever thought of a means to get new data? The post Web Scrapping- Tool for DataEngineering appeared first on Analytics Vidhya. The usefulness of the topic is one that easily helps other disciplines.
This article was published as a part of the Data Science Blogathon. Introduction Dear DataEngineers, this article is a very interesting topic. Let me give some flashback; a few years ago, Mr.Someone in the discussion coined the new word how ACID and BASE properties of DATA. Everyone started […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon Pretty much everything or all sorts of information available online is. The post What is relational about Relational Databases? appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Pre-requisites A Basic understanding of Databases. The post A beginner’s Guide to Database: Part 1 appeared first on Analytics Vidhya. Introduction Here I am going.
This article was published as a part of the Data Science Blogathon. Introduction Amazon Athena is an interactive query service based on open-source Apache Presto that allows you to analyze data stored in Amazon S3 using ANSI SQL directly.
This article was published as a part of the Data Science Blogathon Overview When Apache Cassandra first came out, it included a command-line interface for dealing with thrift. Manipulation of data in this manner was inconvenient and caused knowing the API’s intricacies.
This article was published as a part of the Data Science Blogathon. Introduction Apache Sqoop is a big dataengine for transferring data between Hadoop and relational database servers. Big Data Sqoop can also be […].
This article was published as a part of the Data Science Blogathon. Introduction Source: Image by Pexels from Pixabay Have you ever wondered about the dark side of databases? We, software developers, rely on databases to store and manage important data for our applications.
This article was published as a part of the Data Science Blogathon. Introduction As an SQL Developer, you regularly work with enormous amounts of data stored in different tables that are present inside databases. The post Database Normalization- A Step-by-Step Guide with Examples appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Source: Photo by Kylo on Unsplash As a database (DB) designer, getting the design right from the start is important. The post Database Design Mistakes and Ways to Avoid Them appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction When we hear the word “DATABASE”, the first thought that comes to our mind is SQL! No doubt, SQL and relational databases are widely popular and used extensively for storing data.
This article was published as a part of the Data Science Blogathon. Introduction Organizations with a separate transactional database and data warehouse typically have many dataengineering activities. For example, they extract, transform and load data from various sources into their data warehouse.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Let’s consider a scenario where you are working on a. The post How to connect MongoDB database with Django appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction One of the sources of Big Data is the traditional application management system or the interaction of applications with relational databases using RDBMS. Big Data storage and analysis […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon. Data Science without data is similar to fishing without fish. The post Getting Started with MongoDB database for Data Science appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Apache CouchDB is an open-source, document-based NoSQL database developed by Apache Software Foundation and used by big companies like Apple, GenCorp Technologies, and Wells Fargo.
This article was published as a part of the Data Science Blogathon Overview of Apache Calcite Making your own SQL database or running SQL queries against a NoSQL database seems to be a very daunting task. And if we are talking about a distributed database, then the complexity increases many times over.
This article was published as a part of the Data Science Blogathon. Introduction The structured data we generally deal with gets stored in a tabular format in relational databases. And stored data in these databases can be accessed by a query language called “sequel” or SQL. But, it is […].
This article was published as a part of the Data Science Blogathon. Introduction A NoSQL database is a non-relational database that does not use the traditional table-based schema of a relational database. NoSQL databases are often used for big data and real-time web applications.
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction Amazon Web Services (AWS) is a cloud computing platform offering a wide range of services coming under domains like networking, storage, computing, security, databases, machine learning, etc.
ArticleVideos This article was published as a part of the Data Science Blogathon. Introduction: One of the main concepts of Relational Database Management Systems. The post An Introduction to Normalization Theory appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction The essential element for any organization’s operation is data. Data is getting significant and gaining more traction by the day. Hence it is required to store such a large amount of data carefully.
This article was published as a part of the Data Science Blogathon. Introduction HBase is a column-oriented non-relational database management system that operates on Hadoop Distributed File System (HDFS). HBase provides a fault-tolerant manner of storing sparse data sets, which are prevalent in several big data use cases.
This article was published as a part of the Data Science Blogathon. Image Source: Author Introduction DataEngineers and Data Scientists need data for their Day-to-Day job. Of course, It could be for Data Analytics, Data Prediction, Data Mining, Building Machine Learning Models Etc.,
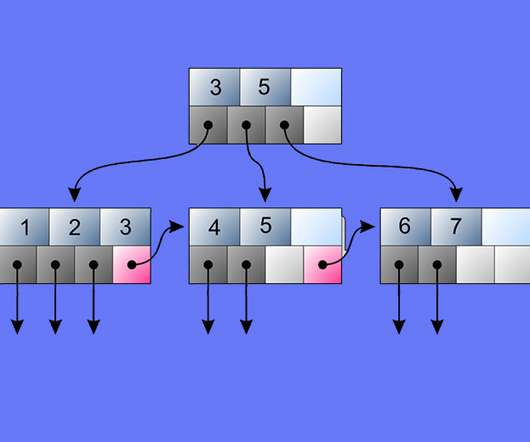
This article was published as a part of the Data Science Blogathon. Introduction Since the 1970s, relational database management systems have solved the problems of storing and maintaining large volumes of structured data.
This article was published as a part of the Data Science Blogathon What is the need for Hive? The official description of Hive is- ‘Apache Hive data warehouse software project built on top of Apache Hadoop for providing data query and analysis.
ArticleVideo Book This article was published as a part of the Data Science Blogathon. Introduction MongoDB is a free open-source No-SQL document database. The post How To Create An Aggregation Pipeline In MongoDB appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Pre-requisites – Basic knowledge of any database. – Basic understanding of. The post A Beginner’s Guide to MySQL: Part 2 appeared first on Analytics Vidhya.
In this article, author Gunnar Morling discusses Postgres database's logical decoding function to retrieve the messages from write-ahead log, process them, and relay them to external consumers, with help of use cases like outbox, audit logs and replication slots. By Gunnar Morling
This article was published as a part of the Data Science Blogathon. Introduction In this article, we will introduce you to the big data ecosystem and the role of Apache Spark in Big data. We will also cover the Distributed database system, the backbone of big data. In today’s world, data is the fuel.
This article was published as a part of the Data Science Blogathon Overview of MongoDB Because of its outstanding performance, extensive developer support, and generous free tier, MongoDB has rapidly become my non-relational database platform of choice.
This article was published as a part of the Data Science Blogathon. Introduction A Database is a collection of inter-related data, and a Database Management System is a set of programs that helps users create and maintain this data. DBMS is a computer-based data record-keeping system.
This article was published as a part of the Data Science Blogathon. It aims to replace conventional backend servers for web and mobile applications by offering multiple services on the same platform like authentication, real-time database, Firestore (NoSQL database), cloud functions, […].
This article was published as a part of the Data Science Blogathon. Introduction Hive is a popular data warehouse built on top of Hadoop that is used by companies like Walmart, Tiktok, and AT&T. It is an important technology for dataengineers to learn and master.
This article was published as a part of the Data Science Blogathon. Introduction NoSQL databases allow us to store vast amounts of data and access them anytime, from any location and device. However, deciding which data modelling technique best suits your needs is complex.
This article was published as a part of the Data Science Blogathon. Introduction In this article, we will build Library Management System using MYSQL. We will build the database, which includes tables. The post Library Management System using MYSQL appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon In this article, we will learn to connect the Snowflake database. The post One-stop-shop for Connecting Snowflake to Python! appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Have you ever wondered how big IT giants store and process huge amounts of data? storing the data […].
What is an online transaction processing database (OLTP)? OLTP is the backbone of modern data processing, a critical component in managing large volumes of transactions quickly and efficiently. This approach allows businesses to efficiently manage large amounts of data and leverage it to their advantage in a highly competitive market.
This article was published as a part of the Data Science Blogathon. Introduction Impala is an open-source and native analytics database for Hadoop. Vendors such as Cloudera, Oracle, MapReduce, and Amazon have shipped Impala. If you want to learn all things Impala, you’ve come to the right place.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content