This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Overview: Assume the job of a DataEngineer, extracting data from. The post Implementing ETL Process Using Python to Learn DataEngineering appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction At the highest level, ETL converts your data before uploading, while ELT converts data only after uploading to your repository. The post ETL & ELT – DataEngineering Essentials appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon A data scientist’s ability to extract value from data is closely related to how well-developed a company’s data storage and processing infrastructure is.
ArticleVideo Book This article was published as a part of the Data Science Blogathon. Introduction ETL pipelines look different today than they used to. The post Is manual ETL better than No-Code ETL: Are ETL tools dead? appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Overview ETL (Extract, Transform, and Load) is a very common technique in dataengineering. Traditionally, ETL processes are […]. Traditionally, ETL processes are […].
This article was published as a part of the Data Science Blogathon. Introduction Processing large amounts of raw data from various sources requires appropriate tools and solutions for effective data integration. Building an ETL pipeline using Apache […]. Building an ETL pipeline using Apache […].
This article was published as a part of the Data Science Blogathon. The post ETL and Workflow Orchestration Tools appeared first on Analytics Vidhya. We’ll continue […].
This article talks about several best practices for writing ETLs for building training datasets. It delves into several software engineering techniques and patterns applied to ML.
This article was published as a part of the Data Science Blogathon. Introduction Organizations with a separate transactional database and data warehouse typically have many dataengineering activities. For example, they extract, transform and load data from various sources into their data warehouse.
This article was published as a part of the Data Science Blogathon. Introduction Data is ubiquitous in our modern life. Obtaining, structuring, and analyzing these data into new, relevant information is crucial in today’s world. The post ETL vs ELT in 2022: Do they matter? appeared first on Analytics Vidhya.
In this article, we will discuss use cases and methods for using ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) processes along with SQL to integrate data from various sources.
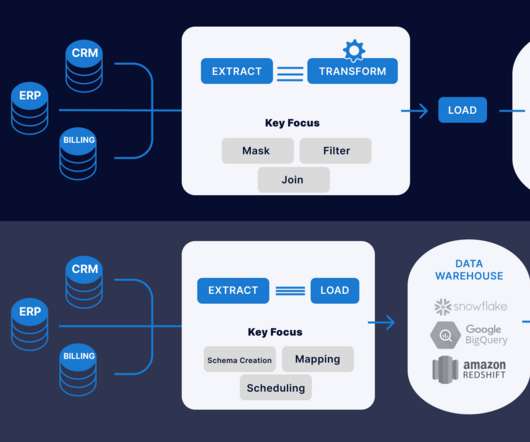
Introduction This article will explain the difference between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) when data transformation occurs. In ETL, data is extracted from multiple locations to meet the requirements of the target data file and then placed into the file.
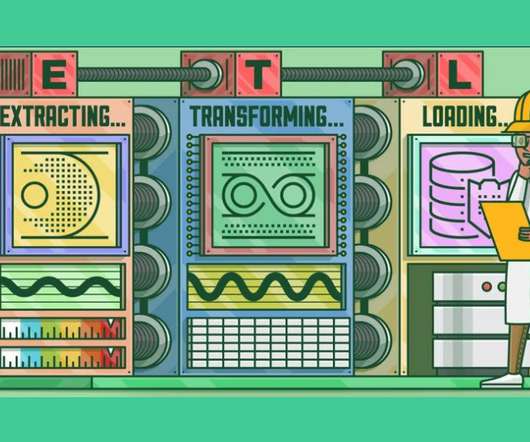
This article was published as a part of the Data Science Blogathon What is ETL? ETL is a process that extracts data from multiple source systems, changes it (through calculations, concatenations, and so on), and then puts it into the Data Warehouse system. ETL stands for Extract, Transform, and Load.
This article was published as a part of the Data Science Blogathon. Introduction AWS Glue helps DataEngineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. It provides organizations with […].
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction If you are familiar with databases, or data warehouses, you have probably heard the term “ETL.” As the amount of data at organizations grow, making use of that data in analytics to derive business insights grows as well.
This article was published as a part of the Data Science Blogathon. Introduction Data acclimates to countless shapes and sizes to complete its journey from a source to a destination. Be it a streaming job or a batch job, ETL and ELT are irreplaceable.
This article was published as a part of the Data Science Blogathon. Introduction Data scientists, engineers, and BI analysts often need to analyze, process, or query different data sources.
Learn the basics of dataengineering to improve your ML modelsPhoto by Mike Benna on Unsplash It is not news that developing Machine Learning algorithms requires data, often a lot of data. Collecting this data is not trivial, in fact, it is one of the most relevant and difficult parts of the entire workflow.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for dataengineers to enhance and sustain their pipelines.
In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. Extract, transform and Load Before we begin, let’s shed some light on what an ETL pipeline essentially is. One of them is Azure functions.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
Summary: The fundamentals of DataEngineering encompass essential practices like data modelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is DataEngineering?
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Dataengineering is a rapidly growing field that designs and develops systems that process and manage large amounts of data. There are various architectural design patterns in dataengineering that are used to solve different data-related problems.
In this article, we will highlight the key elements when it comes to process mining architectures as well as the most common mistakes, to help organizations leverage the power of process mining while maintain cost control. Depending the organization situation and data strategy, on premises or hybrid approaches should be also considered.
Enrich dataengineering skills by building problem-solving ability with real-world projects, teaming with peers, participating in coding challenges, and more. Globally several organizations are hiring dataengineers to extract, process and analyze information, which is available in the vast volumes of data sets.
Getting Started with AI in High-Risk Industries, How to Become a DataEngineer, and Query-Driven Data Modeling How To Get Started With Building AI in High-Risk Industries This guide will get you started building AI in your organization with ease, axing unnecessary jargon and fluff, so you can start today.
Data-driven culture cannot exist without the democratization of the data. Data democratization certainly does not mean unrestricted access to all […]. The post How a Modern DataEngineering Stack Can Help Create a Data-Driven Culture appeared first on DATAVERSITY.
After this, the data is analyzed, business logic is applied, and it is processed for further analytical tasks like visualization or machine learning. Big data pipelines operate similarly to traditional ETL (Extract, Transform, Load) pipelines but are designed to handle much larger data volumes.
And for searching the term you landed on multiple blogs, articles as well YouTube videos, because this is a very vast topic, or I, would say a vast Industry. I’m not saying those are incorrect or wrong even though every article has its mindset behind the term ‘ Data Science ’.
Data Scientists and ML Engineers typically write lots and lots of code. From writing code for doing exploratory analysis, experimentation code for modeling, ETLs for creating training datasets, Airflow (or similar) code to generate DAGs, REST APIs, streaming jobs, monitoring jobs, etc.
In August 2019, Data Works was acquired and Dave worked to ensure a successful transition. David: My technical background is in ETL, data extraction, dataengineering and data analytics. An ETL process was built to take the CSV, find the corresponding text articles and load the data into a SQLite database.
What is Reference Data? Snowflake can not natively read files on these services, so an ETL service is needed to upload the data. Once an ETL process is set up, it is easy for users to break the pipeline by adding fields or modifying the source file in unexpected ways.
With the “Data Productivity Cloud” launch, Matillion has achieved a balance of simplifying source control, collaboration, and dataops by elevating Git integration to a “first-class citizen” within the framework. In Matillion ETL, the Git integration enables an organization to connect to any Git offering (e.g.,
Your dataengineers, analysts, and data scientists are working to find answers to your questions and deliver insights to help you make decisions. Click to learn more about author Helena Schwenk.
In this article, I will explain the modern data stack in detail, list some benefits, and discuss what the future holds. What Is the Modern Data Stack? The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform.
This article is a real-life study of building a CI/CD MLOps pipeline. Two Data Scientists: Responsible for setting up the ML models training and experimentation pipelines. One DataEngineer: Cloud database integration with our cloud expert. If you aren’t aware already, let’s introduce the concept of ETL.
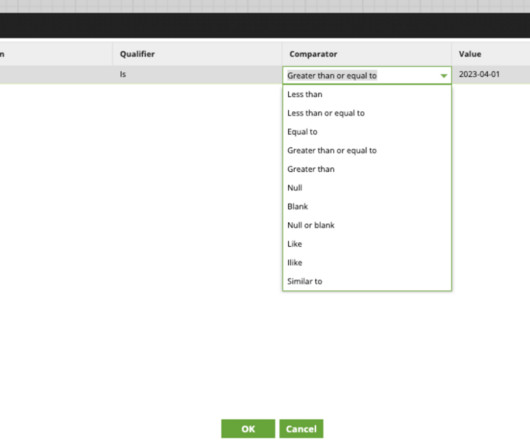
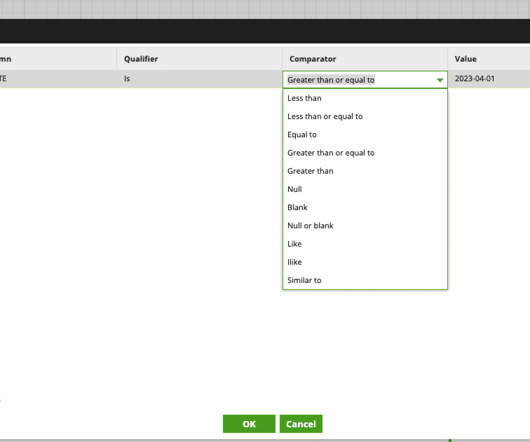
In this blog, we’ll explore how Matillion Jobs can simplify the data transformation process by allowing users to visualize the data flow of a job from start to finish. What is Matillion ETL? Whether you’re new to Matillion or just looking to improve your ETL skills, keep reading to learn more!
In this blog, we’ll explore how Matillion Jobs can simplify the data transformation process by allowing users to visualize the data flow of a job from start to finish. With that, let’s dive in What is Matillion ETL? Read Components These are the components that define the source of data that is to be transformed.
More Speakers and Sessions Announced for the 2024 DataEngineering Summit Ranging from experimentation platforms to enhanced ETL models and more, here are some more sessions coming to the 2024 DataEngineering Summit. Learn more about them here!
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content