This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction Data is defined as information that has been organized in a meaningful way. Data collection is critical for businesses to make informed decisions, understand customers’ […]. The post DataLake or Data Warehouse- Which is Better?
In this article, Ashutosh Kumar discusses the emergence of modern data solutions that have led to the development of ELT and ETL with unique features and advantages. ELT is more popular due to its ability to handle large and unstructured datasets like in datalakes.
This article was published as a part of the Data Science Blogathon. The post How a Delta Lake is Process with Azure Synapse Analytics appeared first on Analytics Vidhya.
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
In this contributed article, Sida Shen, product marketing manager, CelerData, discusses how data lakehouse architectures promise the combined strengths of datalakes and data warehouses, but one question arises: why do we still find the need to transfer data from these lakehouses to proprietary data warehouses?
While databases were the traditional way to store large amounts of data, a new storage method has developed that can store even more significant and varied amounts of data. These are called datalakes. What Are DataLakes? However, even digital information has to be stored somewhere.
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As datalakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.
Dremio, the unified lakehouse platform for self-service analytics and AI, announced a breakthrough in datalake analytics performance capabilities, extending its leadership in self-optimizing, autonomous Iceberg data management.
In this contributed article, Tom Scott, CEO of Streambased, outlines the path event streaming systems have taken to arrive at the point where they must adopt analytical use cases and looks at some possible futures in this area.
Within the Data Management industry, it’s becoming clear that the old model of rounding up massive amounts of data, dumping it into a datalake, and building an API to extract needed information isn’t working. The post Why Graph Databases Are an Essential Choice for Master Data Management appeared first on DATAVERSITY.
Data warehouse vs. datalake, each has their own unique advantages and disadvantages; it’s helpful to understand their similarities and differences. In this article, we’ll focus on a datalake vs. data warehouse. It is often used as a foundation for enterprise datalakes.
Writing data to an AWS datalake and retrieving it to populate an AWS RDS MS SQL database involves several AWS services and a sequence of steps for data transfer and transformation. This process leverages AWS S3 for the datalake storage, AWS Glue for ETL operations, and AWS Lambda for orchestration.
to store and analyze this data to get valuable business insights from it. You will study top 11 azure interview questions in this article which will discuss different data services like Azure Cosmos […] The post Top 11 Azure Data Services Interview Questions in 2023 appeared first on Analytics Vidhya.
The size and the variety of data that enterprises have to deal with have become more complex and larger. Traditional relational databases provide certain benefits, but they are not suitable to handle big and various data. In this article, we will discuss shortcomings of indexing in Athena and S3 and how we can deal with them.
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. The datalake can then refine, enrich, index, and analyze that data. and various countries in Europe.
Data mining is a fascinating field that blends statistical techniques, machine learning, and database systems to reveal insights hidden within vast amounts of data. Businesses across various sectors are leveraging data mining to gain a competitive edge, improve decision-making, and optimize operations.
Be sure to check out his talk, “ What is a Time-series Database and Why do I Need One? Most data scientists are familiar with the concept of time series data and work with it often. The time series database (TSDB) , however, is still an underutilized tool in the data science community. at ODSC West 2023.
Whether it’s data management, analytics, or scalability, AWS can be the top-notch solution for any SaaS company. In this article we will list 10 things AWS can do for your SaaS company. This article finally gets to the core question we started with: what can AWS do for your SaaS business? Data storage databases.
As the Internet of Things (IoT) continues to revolutionize industries and shape the future, data scientists play a crucial role in unlocking its full potential. A recent article on Analytics Insight explores the critical aspect of data engineering for IoT applications.
The Future of the Single Source of Truth is an Open DataLake Organizations that strive for high-performance data systems are increasingly turning towards the ELT (Extract, Load, Transform) model using an open datalake. To DIY you need to: host an API, build a UI, and run or rent a database.
Comprehensive data privacy laws in at least four states are going into effect this year, and more than a dozen states have similar legislation in the works. Database management may become increasingly complex as organizations must account for more of these laws. They can then make the most of their most valuable resource.
The success of any data initiative hinges on the robustness and flexibility of its big data pipeline. What is a Data Pipeline? A traditional data pipeline is a structured process that begins with gathering data from various sources and loading it into a data warehouse or datalake.
Our goal was to improve the user experience of an existing application used to explore the counters and insights data. The data is stored in a datalake and retrieved by SQL using Amazon Athena. The problem Making data accessible to users through applications has always been a challenge.
Interactive analytics applications make it easy to get and build reports from large unstructured data sets fast and at scale. In this article, we’re going to look at the top 5. Firebolt makes engineering a sub-second analytics experience possible by delivering production-grade data applications & analytics.
There are several choices to consider, each with its own set of advantages and disadvantages: Data warehouses are used to store data that has been processed for a specific function from one or more sources. Datalakes hold raw data that has not yet been altered to meet a specific purpose.
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. With Great Expectations , data teams can express what they “expect” from their data using simple assertions.
In the early days of business analysis and underwriting, data was managed with simply a pen and paper and, of course, Excel spreadsheets. As technology has advanced, databases, warehouses, and datalakes have enabled information to be collected, stored, and managed electronically.
The combination of large language models (LLMs), including the ease of integration that Amazon Bedrock offers, and a scalable, domain-oriented data infrastructure positions this as an intelligent method of tapping into the abundant information held in various analytics databases and datalakes.
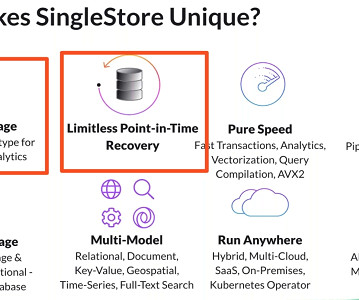
Real-time Analytics & Built-in Machine Learning Models with a Single Database Akmal Chaudhri, Senior Technical Evangelist at SingleStore, explores the importance of delivering real-time experiences in today’s big data industry and how data models and algorithms rely on powerful and versatile data infrastructure.
In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different data platform solution. Hence, DataLake emerged, which handles unstructured and structured data with huge volume. This article endeavors to alleviate those confusions.
blog series, we experiment with the most interesting blends of data and tools. Whether it’s mixing traditional sources with modern datalakes, open-source devops on the cloud with protected internal legacy tools, SQL with noSQL, web-wisdom-of-the-crowd with in-house handwritten notes, or IoT […]. In the “Will They Blend?”
As data is the foundation of any machine learning project, it is essential to have a system in place for tracking and managing changes to data over time. However, data versioning control is frequently given little attention, leading to issues such as data inconsistencies and the inability to reproduce results.
blog series, we experiment with the most interesting blends of data and tools. Whether it’s mixing traditional sources with modern datalakes, open-source DevOps on the cloud with protected internal legacy tools, SQL with noSQL, web-wisdom-of-the-crowd with in-house handwritten notes, or IoT […]. In the “Will They Blend?”
To provide you with a comprehensive overview, this article explores the key players in the MLOps and FMOps (or LLMOps) ecosystems, encompassing both open-source and closed-source tools, with a focus on highlighting their key features and contributions. Dolt Dolt is an open-source relational database system built on Git.
Social media conversations, comments, customer reviews, and image data are unstructured in nature and hold valuable insights, many of which are still being uncovered through advanced techniques like Natural Language Processing (NLP) and machine learning. Many find themselves swamped by the volume and complexity of unstructured data.
This article explores the nuances of mainframe optimization, outlining the drivers, common patterns, and key methods and tools for effective implementation. Cloud-based DevOps provides a modern, agile environment for developing and maintaining applications and services that interact with the organization’s mainframe data.
In this article, we want to dig deeper into the fundamentals of machine learning as an engineering discipline and outline answers to key questions: Why does ML need special treatment in the first place? ML use cases rarely dictate the master data management solution, so the ML stack needs to integrate with existing data warehouses.
Challenges associated with these stages involve not knowing all touchpoints where data is persisted, maintaining a data pre-processing pipeline for document chunking, choosing a chunking strategy, vector database, and indexing strategy, generating embeddings, and any manual steps to purge data from vector stores and keep it in sync with source data.
The global Big Data and Data Engineering Services market, valued at USD 51,761.6 This article explores the key fundamentals of Data Engineering, highlighting its significance and providing a roadmap for professionals seeking to excel in this vital field. This section explores essential aspects of Data Engineering.
REGISTER NOW Designing and implementing data infrastructure Data engineers are responsible for choosing and configuring the right tools and technologies to store, process, and analyze data. This might involve setting up databases, datalakes, and streaming platforms.
Managing unstructured data is essential for the success of machine learning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. This article will discuss managing unstructured data for AI and ML projects. How to properly manage unstructured data.
The Datamarts capability opens endless possibilities for organizations to achieve their data analytics goals on the Power BI platform. This article is an excerpt from the book Expert Data Modeling with Power BI, Third Edition by Soheil Bakhshi, a completely updated and revised edition of the bestselling guide to Power BI and data modeling.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your data warehouse. Snowflake provides native ways for data ingestion.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content