This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
For production grade LLM apps, you need a robust datapipeline. This article talks about the different stages of building a Gen AI datapipeline and what is included in these stages.
This article was published as a part of the Data Science Blogathon. Introduction Data acclimates to countless shapes and sizes to complete its journey from a source to a destination. The post Developing an End-to-End Automated DataPipeline appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction These days companies seem to seek ways to integrate data from multiple sources to earn a competitive advantage over other businesses. The post Getting Started with DataPipeline appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. The post All About DataPipeline and Kafka Basics appeared first on Analytics Vidhya. The post All About DataPipeline and Kafka Basics appeared first on Analytics Vidhya.
In today’s data-driven world, extracting, transforming, and loading (ETL) data is crucial for gaining valuable insights. While many ETL tools exist, dbt (data build tool) is emerging as a game-changer.
This article was published as a part of the Data Science Blogathon. Introduction In this blog, we will explore one interesting aspect of the pandas read_csv function, the Python Iterator parameter, which can be used to read relatively large input data.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Apache Spark is a framework used in cluster computing environments. The post Building a DataPipeline with PySpark and AWS appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction ETL pipelines can be built from bash scripts. You will learn about how shell scripting can implement an ETL pipeline, and how ETL scripts or tasks can be scheduled using shell scripting. What is shell scripting?
This article was published as a part of the Data Science Blogathon. Dale Carnegie” Apache Kafka is a Software Framework for storing, reading, and analyzing streaming data. The post Build a Simple Realtime DataPipeline appeared first on Analytics Vidhya. Introduction “Learning is an active process.
This article was published as a part of the Data Science Blogathon. Introduction With the development of data-driven applications, the complexity of integrating data from multiple simple decision-making sources is often considered a significant challenge.
This article was published as a part of the Data Science Blogathon. Introduction ETL is the process that extracts the data from various data sources, transforms the collected data, and loads that data into a common data repository. Azure Data Factory […]. Azure Data Factory […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction In this article we will be discussing Binary Image Classification. The post Image Classification with TensorFlow : Developing the DataPipeline (Part 1) appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction to Apache Airflow “Apache Airflow is the most widely-adopted, open-source workflow management platform for data engineering pipelines. Most organizations today with complex datapipelines to […].
This article was published as a part of the Data Science Blogathon. Introduction When creating datapipelines, Software Engineers and Data Engineers frequently work with databases using Database Management Systems like PostgreSQL.
Introduction Apache Airflow is a powerful platform that revolutionizes the management and execution of Extracting, Transforming, and Loading (ETL) data processes. It offers a scalable and extensible solution for automating complex workflows, automating repetitive tasks, and monitoring datapipelines.
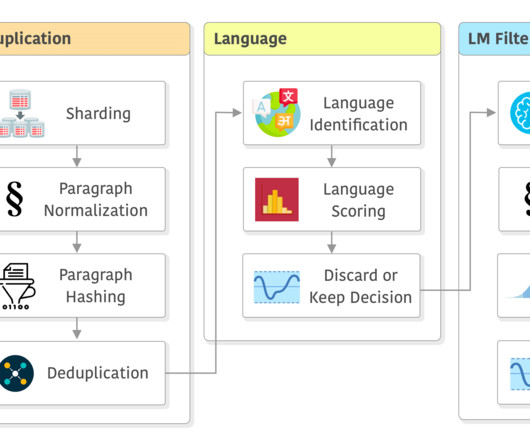
This article provides a short introduction to the pipeline used to create the data to train large language models (LLMs) such as LLaMA using Common Crawl (CC).
Datapipelines have been crucial for brands in a number of ways. In March, Hubspot talked about the shift towards incorporating big data into marketing pipelines in B2B campaigns. “A However, it is important to use the right datapipelines to leverage these benefits.
Introduction Managing a datapipeline, such as transferring data from CSV to PostgreSQL, is like orchestrating a well-timed process where each step relies on the previous one. Apache Airflow streamlines this process by automating the workflow, making it easy to manage complex data tasks.
Modern datapipeline platform provider Matillion today announced at Snowflake Data Cloud Summit 2024 that it is bringing no-code Generative AI (GenAI) to Snowflake users with new GenAI capabilities and integrations with Snowflake Cortex AI, Snowflake ML Functions, and support for Snowpark Container Services.
ChatGPT plugins can be used to extend the capabilities of ChatGPT in a variety of ways, such as: Accessing and processing external data Performing complex computations Using third-party services In this article, we’ll dive into the top 6 ChatGPT plugins tailored for data science.
This article was published as a part of the Data Science Blogathon. Introduction In this article, we will learn about machine learning using Spark. Our previous articles discussed Spark databases, installation, and working of Spark in Python. In this article, we will mainly talk about […].
Business success is based on how we use continuously changing data. That’s where streaming datapipelines come into play. This article explores what streaming datapipelines are, how they work, and how to build this datapipeline architecture. What is a streaming datapipeline?
Image Credits: Pixabay Although AI is often in the spotlight, the focus on strong data foundations and effective data strategies is often overlooked. Natural Language Processing (NLP) is an example of where traditional methods can struggle with complex text data. GenAI prompts can address such challenges effectively.
The key to being truly data-driven is having access to accurate, complete, and reliable data. In fact, Gartner recently found that organizations believe […] The post How to Assess Data Quality Readiness for Modern DataPipelines appeared first on DATAVERSITY.
This article was published as a part of the Data Science Blogathon. Introduction A deep learning task typically entails analyzing an image, text, or table of data (cross-sectional and time-series) to produce a number, label, additional text, additional images, or a mix of these.
Datapipelines are like insurance. ETL processes are constantly toiling away behind the scenes, doing heavy lifting to connect the sources of data from the real world with the warehouses and lakes that make the data useful. You only know they exist when something goes wrong.
Datapipelines are a set of processes that move data from one place to another, typically from the source of data to a storage system. These processes involve data extraction from various sources, transformation to fit business or technical needs, and loading into a final destination for analysis or reporting.
It was only a few years ago that BI and data experts excitedly claimed that petabytes of unstructured data could be brought under control with datapipelines and orderly, efficient data warehouses. But as big data continued to grow and the amount of stored information increased every […].
In part one of this blog post, we described why there are many challenges for developers of datapipeline testing tools (complexities of technologies, large variety of data structures and formats, and the need to support diverse CI/CD pipelines).
In part one of this article, we discussed how data testing can specifically test a data object (e.g., table, column, metadata) at one particular point in the datapipeline.
Those who want to design universal datapipelines and ETL testing tools face a tough challenge because of the vastness and variety of technologies: Each datapipeline platform embodies a unique philosophy, architectural design, and set of operations.
Today’s datapipelines use transformations to convert raw data into meaningful insights. Yet, ensuring the accuracy and reliability of these transformations is no small feat – tools and methods to test the variety of data and transformation can be daunting.
Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier. What is an ETL datapipeline in ML? Datapipelines often run real-time processing.
Data integration processes benefit from automated testing just like any other software. Yet finding a datapipeline project with a suitable set of automated tests is rare. Even when a project has many tests, they are often unstructured, do not communicate their purpose, and are hard to run.
Suppose you’re in charge of maintaining a large set of datapipelines from cloud storage or streaming data into a data warehouse. How can you ensure that your data meets expectations after every transformation? That’s where data quality testing comes in.
This article was published as a part of the Data Science Blogathon. “Preponderance data opens doorways to complex and Avant analytics.” ” Introduction to SQL Queries Data is the premium product of the 21st century.
Introduction Integrating data proficiently is crucial in today’s era of data-driven decision-making. Azure Data Factory (ADF) is a pivotal solution for orchestrating this integration. What is Azure Data Factory […] The post What is Azure Data Factory (ADF)?
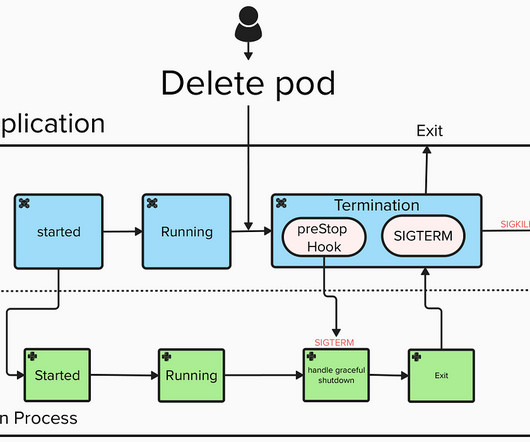
Graceful External Termination: Handling Pod Deletions in Kubernetes Data Ingestion and Streaming Jobs When running big-datapipelines in Kubernetes, especially streaming jobs, its easy to overlook how these jobs deal with termination. If not handled correctly, this can lead to locks, data issues, and a negative user experience.
Where exactly within an organization does the primary responsibility lie for ensuring that a datapipeline project generates data of high quality, and who exactly holds that responsibility? Who is accountable for ensuring that the data is accurate? Is it the data engineers? The data scientists?
What Is Continuous Delivery? Continuous delivery (CD) refers to a software engineering approach where teams produce software in short cycles, ensuring that software can be reliably released at any time. Its main goals are to build, test, and release software faster and more frequently.
The same expectation applies to data, […] The post Leveraging DataPipelines to Meet the Needs of the Business: Why the Speed of Data Matters appeared first on DATAVERSITY. Today, businesses and individuals expect instant access to information and swift delivery of services.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
Companies are spending a lot of money on data and analytics capabilities, creating more and more data products for people inside and outside the company. These products rely on a tangle of datapipelines, each a choreography of software executions transporting data from one place to another.
which play a crucial role in building end-to-end datapipelines, to be included in your CI/CD pipelines. Declarative Database Change Management Approaches For insights into database change management tool selection for Snowflake, check out this article.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content