This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction Data acclimates to countless shapes and sizes to complete its journey from a source to a destination. The post Developing an End-to-End Automated DataPipeline appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction When creating datapipelines, Software Engineers and Data Engineers frequently work with databases using Database Management Systems like PostgreSQL.
This article was published as a part of the Data Science Blogathon. Introduction These days companies seem to seek ways to integrate data from multiple sources to earn a competitive advantage over other businesses. The post Getting Started with DataPipeline appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction ETL pipelines can be built from bash scripts. You will learn about how shell scripting can implement an ETL pipeline, and how ETL scripts or tasks can be scheduled using shell scripting. What is shell scripting?
This article was published as a part of the Data Science Blogathon. Dale Carnegie” Apache Kafka is a Software Framework for storing, reading, and analyzing streaming data. The post Build a Simple Realtime DataPipeline appeared first on Analytics Vidhya. Introduction “Learning is an active process.
This article was published as a part of the Data Science Blogathon. Introduction In this article, we will learn about machine learning using Spark. Our previous articles discussed Spark databases, installation, and working of Spark in Python. In this article, we will mainly talk about […].
Datapipelines have been crucial for brands in a number of ways. In March, Hubspot talked about the shift towards incorporating big data into marketing pipelines in B2B campaigns. “A However, it is important to use the right datapipelines to leverage these benefits.
Introduction Managing a datapipeline, such as transferring data from CSV to PostgreSQL, is like orchestrating a well-timed process where each step relies on the previous one. Apache Airflow streamlines this process by automating the workflow, making it easy to manage complex data tasks.
ChatGPT plugins can be used to extend the capabilities of ChatGPT in a variety of ways, such as: Accessing and processing external data Performing complex computations Using third-party services In this article, we’ll dive into the top 6 ChatGPT plugins tailored for data science.
Business success is based on how we use continuously changing data. That’s where streaming datapipelines come into play. This article explores what streaming datapipelines are, how they work, and how to build this datapipeline architecture. What is a streaming datapipeline?
In part one of this article, we discussed how data testing can specifically test a data object (e.g., table, column, metadata) at one particular point in the datapipeline.
This article was published as a part of the Data Science Blogathon. “Preponderance data opens doorways to complex and Avant analytics.” ” Introduction to SQL Queries Data is the premium product of the 21st century.
Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier. What is an ETL datapipeline in ML? Datapipelines often run real-time processing.
Data integration processes benefit from automated testing just like any other software. Yet finding a datapipeline project with a suitable set of automated tests is rare. Even when a project has many tests, they are often unstructured, do not communicate their purpose, and are hard to run.
In this blog, we will explore the benefits of enabling the CI/CD pipeline for database platforms. We will also discuss the difference between imperative and declarative database change management approaches. These environments house the database and schema objects required for both governed and non-governed instances.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
These procedures are central to effective data management and crucial for deploying machine learning models and making data-driven decisions. The success of any data initiative hinges on the robustness and flexibility of its big datapipeline. What is a DataPipeline?
How to consume a Linked Data Event Stream and store it in a TimescaleDB database Photo by Scott Graham on Unsplash Linked data event stream Linked Data Event Streams represent and share fast and slow-moving data on the Web using the Resource Description Framework (RDF). and PostgreSQL 14.4
Interactive analytics applications make it easy to get and build reports from large unstructured data sets fast and at scale. In this article, we’re going to look at the top 5. Firebolt makes engineering a sub-second analytics experience possible by delivering production-grade data applications & analytics.
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. VisiData works with CSV files, Excel spreadsheets, SQL databases, and many other data sources.
To provide you with a comprehensive overview, this article explores the key players in the MLOps and FMOps (or LLMOps) ecosystems, encompassing both open-source and closed-source tools, with a focus on highlighting their key features and contributions. Dolt Dolt is an open-source relational database system built on Git.
Real-time data streaming pipelines play a crutial role in achieving this objective. Within this article, we will explore the significance of these pipelines and utilise robust tools such as Apache Kafka and Spark to manage vast streams of data efficiently.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
The global Big Data and Data Engineering Services market, valued at USD 51,761.6 This article explores the key fundamentals of Data Engineering, highlighting its significance and providing a roadmap for professionals seeking to excel in this vital field. What is Data Engineering? million by 2028.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage.
Not only does it involve the process of collecting, storing, and processing data so that it can be used for analysis and decision-making, but these professionals are responsible for building and maintaining the infrastructure that makes this possible; and so much more. Think of data engineers as the architects of the data ecosystem.
Pipelines must have robust data integration capabilities that integrate data from multiple data silos, including the extensive list of applications used throughout the organization, databases and even mainframes. Changes to one database must also be reflected in any other database in real time.
Modin empowers practitioners to use pandas on data at scale, without requiring them to change a single line of code. Modin leverages our cutting-edge academic research on dataframes — the abstraction underlying pandas to bring the best of databases and distributed systems to dataframes. Run operations in pandas - all in Snowflake!
Elementl / Dagster Labs Elementl and Dagster Labs are both companies that provide platforms for building and managing datapipelines. Elementl’s platform is designed for data engineers, while Dagster Labs’ platform is designed for data scientists. However, there are some critical differences between the two companies.
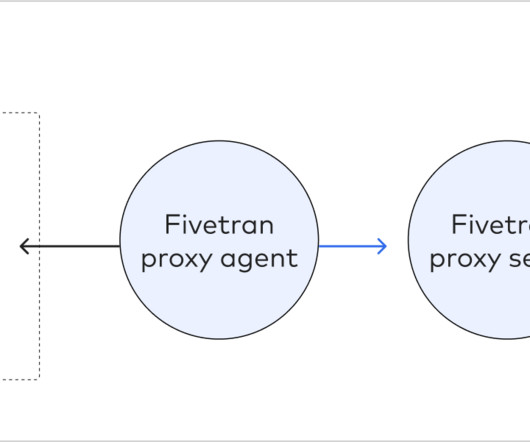
Production databases are a data-rich environment, and Fivetran would help us to migrate data by moving data from on-prem to the supported destinations; ensuring that this data remains uncorrupted throughout enhancements and transformations is crucial. We will now go over all the topics one by one.
Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication. Standard data science practices could also be contributing to this issue. In practice, tabular data is anything but clean and uncomplicated.
Author’s note: this article about data observability and its role in building trusted data has been adapted from an article originally published in Enterprise Management 360. Is your data ready to use? Data observability is a key element of data operations (DataOps).
There are many platforms and sources that generate this kind of data. In this article, we will go through the basics of streaming data, what it is, and how it differs from traditional data. We will also get familiar with tools that can help record this data and further analyse it.
This article was co-written by Lawrence Liu & Safwan Islam While the title ‘ Machine Learning Engineer ’ may sound more prestigious than ‘Data Engineer’ to some, the reality is that these roles share a significant overlap. Generative AI has unlocked the value of unstructured text-based data.
For this, we have to build an entire machine-learning system around our models that manages their lifecycle, feeds properly prepared data into them, and sends their output to downstream systems. An ML system needs to transform the data into features, train models, and make predictions. It can also transform incoming data on the fly.
As data is the foundation of any machine learning project, it is essential to have a system in place for tracking and managing changes to data over time. However, data versioning control is frequently given little attention, leading to issues such as data inconsistencies and the inability to reproduce results.
However, there is a lot more to know about DataOps, as it has its own definition, principles, benefits, and applications in real-life companies today – which we will cover in this article! Automated testing to ensure data quality. There are many inefficiencies that riddle a datapipeline and DataOps aims to deal with that.
Data integration is essentially the Extract and Load portion of the Extract, Load, and Transform (ELT) process. Data ingestion involves connecting your data sources, including databases, flat files, streaming data, etc, to your data warehouse. Snowflake provides native ways for data ingestion.
David: My technical background is in ETL, data extraction, data engineering and data analytics. I spent over a decade of my career developing large-scale datapipelines to transform both structured and unstructured data into formats that can be utilized in downstream systems.
Managing unstructured data is essential for the success of machine learning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging. This article will discuss managing unstructured data for AI and ML projects. How to properly manage unstructured data.
Developers can seamlessly build datapipelines, ML models, and data applications with User-Defined Functions and Stored Procedures. You can set up your own environment in your local system and then check in/deploy the code back to Snowflake using Snowpark (more on this later in the article).
Collecting, storing, and processing large datasets Data engineers are also responsible for collecting, storing, and processing large volumes of data. This involves working with various data storage technologies, such as databases and data warehouses, and ensuring that the data is easily accessible and can be analyzed efficiently.
This individual is responsible for building and maintaining the infrastructure that stores and processes data; the kinds of data can be diverse, but most commonly it will be structured and unstructured data. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable.
In this blog, we’ll explore how Matillion Jobs can simplify the data transformation process by allowing users to visualize the data flow of a job from start to finish. We won’t explore testing in this article, but it is still useful to explore. Database : Source Database of the table. What is Matillion ETL?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content