This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction ETLpipelines can be built from bash scripts. You will learn about how shell scripting can implement an ETLpipeline, and how ETL scripts or tasks can be scheduled using shell scripting. What is shell scripting?
This article was published as a part of the Data Science Blogathon. Introduction Data acclimates to countless shapes and sizes to complete its journey from a source to a destination. Be it a streaming job or a batch job, ETL and ELT are irreplaceable.
This article was published as a part of the Data Science Blogathon. Introduction ETL is the process that extracts the data from various data sources, transforms the collected data, and loads that data into a common data repository. Azure Data Factory […].
In today’s data-driven world, extracting, transforming, and loading (ETL) data is crucial for gaining valuable insights. While many ETL tools exist, dbt (data build tool) is emerging as a game-changer.
Introduction Apache Airflow is a powerful platform that revolutionizes the management and execution of Extracting, Transforming, and Loading (ETL) data processes. It offers a scalable and extensible solution for automating complex workflows, automating repetitive tasks, and monitoring datapipelines.
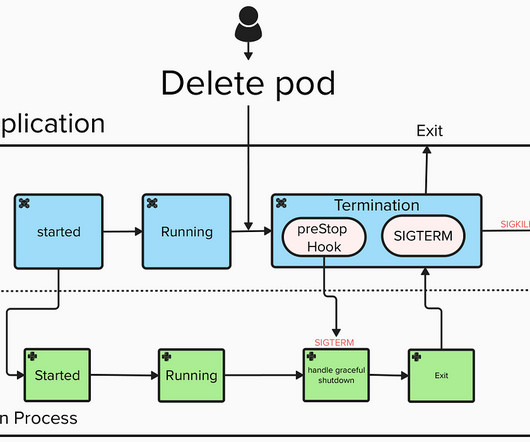
Graceful External Termination: Handling Pod Deletions in Kubernetes Data Ingestion and Streaming Jobs When running big-datapipelines in Kubernetes, especially streaming jobs, its easy to overlook how these jobs deal with termination. If not handled correctly, this can lead to locks, data issues, and a negative user experience.
However, efficient use of ETLpipelines in ML can help make their life much easier. This article explores the importance of ETLpipelines in machine learning, a hands-on example of building ETLpipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
DataOps, which focuses on automated tools throughout the ETL development cycle, responds to a huge challenge for data integration and ETL projects in general. ETL projects are increasingly based on agile processes and automated testing. extract, transform, load) projects are often devoid of automated testing.
Datapipelines are like insurance. ETL processes are constantly toiling away behind the scenes, doing heavy lifting to connect the sources of data from the real world with the warehouses and lakes that make the data useful. You only know they exist when something goes wrong.
Those who want to design universal datapipelines and ETL testing tools face a tough challenge because of the vastness and variety of technologies: Each datapipeline platform embodies a unique philosophy, architectural design, and set of operations.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Following best practices and using suitable tools enhances data integrity and quality, supporting informed decision-making. Introduction The ETL process is crucial in modern data management.
Summary: Selecting the right ETL platform is vital for efficient data integration. Consider your business needs, compare features, and evaluate costs to enhance data accuracy and operational efficiency. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes.
Data integration processes benefit from automated testing just like any other software. Yet finding a datapipeline project with a suitable set of automated tests is rare. Even when a project has many tests, they are often unstructured, do not communicate their purpose, and are hard to run.
DataOps, which focuses on automated tools throughout the ETL development cycle, responds to a huge challenge for data integration and ETL projects in general. ETL projects are increasingly based on agile processes and automated testing. extract, transform, load) projects are often devoid of automated testing.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
These procedures are central to effective data management and crucial for deploying machine learning models and making data-driven decisions. The success of any data initiative hinges on the robustness and flexibility of its big datapipeline. What is a DataPipeline?
Big Data is the collection and processing of huge volumes of different data types, which financial institutions use to gain insights into their business processes and make key company decisions. The Role Of Big Data In Fintech. ETL and Business Intelligence solutions make dealing with large volumes of data easy.
In recent years, data engineering teams working with the Snowflake Data Cloud platform have embraced the continuous integration/continuous delivery (CI/CD) software development process to develop data products and manage ETL/ELT workloads more efficiently.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
Data Scientists and ML Engineers typically write lots and lots of code. From writing code for doing exploratory analysis, experimentation code for modeling, ETLs for creating training datasets, Airflow (or similar) code to generate DAGs, REST APIs, streaming jobs, monitoring jobs, etc. Related post MLOps Is an Extension of DevOps.
In August 2019, Data Works was acquired and Dave worked to ensure a successful transition. David: My technical background is in ETL, data extraction, data engineering and data analytics. An ETL process was built to take the CSV, find the corresponding text articles and load the data into a SQLite database.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Warehousing: Amazon Redshift, Google BigQuery, etc.
The global Big Data and Data Engineering Services market, valued at USD 51,761.6 This article explores the key fundamentals of Data Engineering, highlighting its significance and providing a roadmap for professionals seeking to excel in this vital field. What is Data Engineering? million by 2028. from 2025 to 2030.
This individual is responsible for building and maintaining the infrastructure that stores and processes data; the kinds of data can be diverse, but most commonly it will be structured and unstructured data. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable.
This article was co-written by Mayank Singh & Ayush Kumar Singh Your organization’s datapipelines will inevitably run into issues, ranging from simple permission errors to significant network or infrastructure incidents. Configure your ETL tool to send emails to that address and invite people to join the Slack channel.
However, it can be the OS that runs powerful embedded systems capable of collecting, governing, and managing huge amounts of data and running advanced analytics. When it comes to data integration, RTOS can work with systems that employ data warehousing, API management, and ETL technologies.
Putting the T for Transformation in ELT (ETL) is essential to any datapipeline. After extracting and loading your data into the Snowflake AI Data Cloud , you may wonder how best to transform it. Coalesce Coalesce is a code-first UI-drive transformation tool used exclusively for Snowflake.
This article is a real-life study of building a CI/CD MLOps pipeline. ” Hence the very first thing to do is to make sure that the data being used is of high quality and that any errors or anomalies are detected and corrected before proceeding with ETL and data sourcing. Redshift, S3, and so on.
In this article, I will explain the modern data stack in detail, list some benefits, and discuss what the future holds. What Is the Modern Data Stack? The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform.
Set specific, measurable targets Data science goals to “increase sales” lack the clarity needed to evaluate success and secure ongoing funding. Audit existing data assets Inventory internal datasets, ETL capabilities, past analytical initiatives, and available skill sets.
In this blog, we’ll explore how Matillion Jobs can simplify the data transformation process by allowing users to visualize the data flow of a job from start to finish. What is Matillion ETL? Whether you’re new to Matillion or just looking to improve your ETL skills, keep reading to learn more!
In this blog, we’ll explore how Matillion Jobs can simplify the data transformation process by allowing users to visualize the data flow of a job from start to finish. With that, let’s dive in What is Matillion ETL? Read Components These are the components that define the source of data that is to be transformed.
This involves creating data validation rules, monitoring data quality, and implementing processes to correct any errors that are identified. Creating datapipelines and workflows Data engineers create datapipelines and workflows that enable data to be collected, processed, and analyzed efficiently.
This also consists of the ability to perform root cause analysis on data problems, optimize datapipelines for performance, and enable data integrity and quality. In this article, let’s understand an explanation of how to enhance problem-solving skills as a data engineer. Hadoop, Spark).
Find out how to weave data reliability and quality checks into the execution of your datapipelines and more. More Speakers and Sessions Announced for the 2024 Data Engineering Summit Ranging from experimentation platforms to enhanced ETL models and more, here are some more sessions coming to the 2024 Data Engineering Summit.
Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust datapipelines. These pipelines cover the entire lifecycle of an ML project, from data ingestion and preprocessing, to model training, evaluation, and deployment. It is lightweight.
Data transformation tools simplify this process by automating data manipulation, making it more efficient and reducing errors. These tools enable seamless data integration across multiple sources, streamlining data workflows. What is Data Transformation?
We hope our experience dealing with these challenges can help you understand the complexity of the crypto world and perhaps give you cool insights on how to deal with your own data problems and team management. And that’s when what usually happens, happened: We came for the ML models, we stayed for the ETLs. What’s in the box?
As data is the foundation of any machine learning project, it is essential to have a system in place for tracking and managing changes to data over time. However, data versioning control is frequently given little attention, leading to issues such as data inconsistencies and the inability to reproduce results.
For this, we have to build an entire machine-learning system around our models that manages their lifecycle, feeds properly prepared data into them, and sends their output to downstream systems. An ML system needs to transform the data into features, train models, and make predictions. This can seem daunting.
Speed: The agent on the source database will filter the data before sending it through the datapipeline. That’s why filtering close to the source improves the efficiency and increases the speed but only copying data, which is required. HVA also allows the capture of changes directly from various DBMS articles.
It truly is an all-in-one data lake solution. HPCC Systems and Spark also differ in that they work with distinct parts of the big datapipeline. Spark is more focused on data science, ingestion, and ETL, while HPCC Systems focuses on ETL and data delivery and governance.
When workers get their hands on the right data, it not only gives them what they need to solve problems, but also prompts them to ask, “What else can I do with data?” ” through a truly data literate organization. What is data democratization?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content