This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Different components in the Hadoop Framework Introduction Hadoop is. The post HIVE – A DATAWAREHOUSE IN HADOOP FRAMEWORK appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Have you ever wondered how big IT giants store and process huge amounts of data? storing the data […]. storing the data […].
This article was published as a part of the Data Science Blogathon. Introduction Apache Hive is a datawarehouse system built on top of Hadoop which gives the user the flexibility to write complex MapReduce programs in form of SQL- like queries.
This article was published as a part of the Data Science Blogathon What is the need for Hive? The official description of Hive is- ‘Apache Hive datawarehouse software project built on top of Apache Hadoop for providing data query and analysis.
This article was published as a part of the Data Science Blogathon. Introduction Hive is a popular datawarehouse built on top of Hadoop that is used by companies like Walmart, Tiktok, and AT&T. It is an important technology for data engineers to learn and master.
This article was published as a part of the Data Science Blogathon. Introduction Most of you would know the different approaches for building a data and analytics platform. You would have already worked on systems that used traditional warehouses or Hadoop-based data lakes. Selecting one among […].
Data lakes and datawarehouses are probably the two most widely used structures for storing data. In this article, we will explore both, unfold their key differences and discuss their usage in the context of an organization. DataWarehouses and Data Lakes in a Nutshell. Key Differences.
This article was published as a part of the Data Science Blogathon. Introduction Apache SQOOP is a tool designed to aid in the large-scale export and import of data into HDFS from structured data repositories. Relational databases, enterprise datawarehouses, and NoSQL systems are all examples of data storage.
As cloud computing platforms make it possible to perform advanced analytics on ever larger and more diverse data sets, new and innovative approaches have emerged for storing, preprocessing, and analyzing information. Hadoop, Snowflake, Databricks and other products have rapidly gained adoption.
As data lakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident. Understanding Data Lakes A data lake is a centralized repository that stores structured, semi-structured, and unstructured data in its raw format.
Summary: This article provides a comprehensive guide on Big Data interview questions, covering beginner to advanced topics. Introduction Big Data continues transforming industries, making it a vital asset in 2025. The global Big Data Analytics market, valued at $307.51 First, lets understand the basics of Big Data.
The global Big Data and Data Engineering Services market, valued at USD 51,761.6 This article explores the key fundamentals of Data Engineering, highlighting its significance and providing a roadmap for professionals seeking to excel in this vital field. ETL is vital for ensuring data quality and integrity.
The success of any data initiative hinges on the robustness and flexibility of its big data pipeline. What is a Data Pipeline? A traditional data pipeline is a structured process that begins with gathering data from various sources and loading it into a datawarehouse or data lake.
Data engineering is a rapidly growing field that designs and develops systems that process and manage large amounts of data. There are various architectural design patterns in data engineering that are used to solve different data-related problems.
Data has to be stored somewhere. Datawarehouses are repositories for your cleaned, processed data, but what about all that unstructured data your organization is starting to notice? What is a data lake? Snowflake Snowflake is a cross-cloud platform that looks to break down data silos.
This article endeavors to alleviate those confusions. While traditional datawarehouses made use of an Extract-Transform-Load (ETL) process to ingest data, data lakes instead rely on an Extract-Load-Transform (ELT) process. This adds an additional ETL step, making the data even more stale.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently.
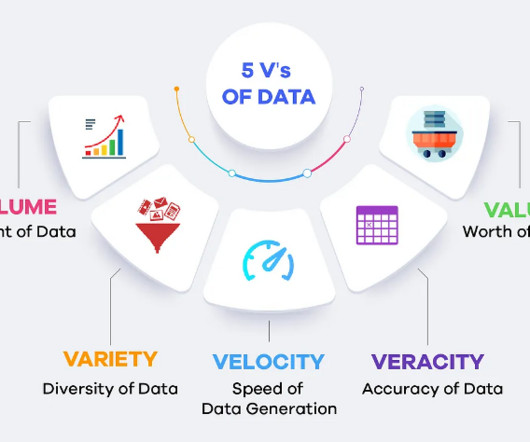
The real advantage of big data lies not just in the sheer quantity of information but in the ability to process it in real-time. Variety Data comes in a myriad of formats including text, images, videos, and more. Veracity Veracity relates to the accuracy and trustworthiness of the data.
Collecting, storing, and processing large datasets Data engineers are also responsible for collecting, storing, and processing large volumes of data. This involves working with various data storage technologies, such as databases and datawarehouses, and ensuring that the data is easily accessible and can be analyzed efficiently.
In my 7 years of Data Science journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and Apache Hadoop. A lot of you who are already in the data science field must be familiar with BigQuery and its advantages.
Data from various sources, collected in different forms, require data entry and compilation. That can be made easier today with virtual datawarehouses that have a centralized platform where data from different sources can be stored. One challenge in applying data science is to identify pertinent business issues.
Image generated with Midjourney Organizations increasingly rely on data to make business decisions, develop strategies, or even make data or machine learning models their key product. As such, the quality of their data can make or break the success of the company. What is a data quality framework?
Data fabric and DataOps are a part of the continued evolution of data management-centric approaches that improve data architecture, efficiency, and quality. These approaches extend the continuum of enterprise datawarehouses, federated data marts, big data (Hadoop), and virtualization on top of distributed cloud file storage.
As data is the foundation of any machine learning project, it is essential to have a system in place for tracking and managing changes to data over time. However, data versioning control is frequently given little attention, leading to issues such as data inconsistencies and the inability to reproduce results.
Social media conversations, comments, customer reviews, and image data are unstructured in nature and hold valuable insights, many of which are still being uncovered through advanced techniques like Natural Language Processing (NLP) and machine learning. Many find themselves swamped by the volume and complexity of unstructured data.
Yet the question remains: How much value have organizations derived from big data? In this article, we’ll take stock of what big data has achieved from a c-suite perspective (with special attention to business transformation and customer experience.). Big Data as an Enabler of Digital Transformation.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
































Let's personalize your content