This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction on ETL Pipeline ETL pipelines are a set of processes used to transfer data from one or more sources to a database, like a data warehouse.
In this article, Ashutosh Kumar discusses the emergence of modern data solutions that have led to the development of ELT and ETL with unique features and advantages. ELT is more popular due to its ability to handle large and unstructured datasets like in data lakes.
This article was published as a part of the Data Science Blogathon. Building an ETL pipeline using Apache […]. Building an ETL pipeline using Apache […]. The post ETL Pipeline with Google DataFlow and Apache Beam appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Organizations with a separate transactional database and data warehouse typically have many data engineering activities. The post Apache Airflow used for Performing ETL appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction ETL pipelines can be built from bash scripts. You will learn about how shell scripting can implement an ETL pipeline, and how ETL scripts or tasks can be scheduled using shell scripting. What is shell scripting?
This article was published as a part of the Data Science Blogathon. Introduction Azure data factory (ADF) is a cloud-based ETL (Extract, Transform, Load) tool and data integration service which allows you to create a data-driven workflow. In this article, I’ll show […]. In this article, I’ll show […].
This article was published as a part of the Data Science Blogathon. Source: [link] Introduction If you are familiar with databases, or data warehouses, you have probably heard the term “ETL.” The post AWS Glue: Simplifying ETL Data Processing appeared first on Analytics Vidhya. For the […].
Introduction This article will be a deep guide for Beginners in Apache Oozie. Users of Oozie can describe dependencies between various jobs […] The post Difference between ETL and ELT Pipeline appeared first on Analytics Vidhya. Apache Oozie is a workflow scheduler system for managing Hadoop jobs.
This article was published as a part of the Data Science Blogathon. Be it a streaming job or a batch job, ETL and ELT are irreplaceable. Before designing an ETL job, choosing optimal, performant, and cost-efficient tools […]. The post Developing an End-to-End Automated Data Pipeline appeared first on Analytics Vidhya.
ETL (Extract, Transform, Load) is a crucial process in the world of data analytics and business intelligence. In this article, we will explore the significance of ETL and how it plays a vital role in enabling effective decision making within businesses. What is ETL? Let’s break down each step: 1.
DataOps, which focuses on automated tools throughout the ETL development cycle, responds to a huge challenge for data integration and ETL projects in general. ETL projects are increasingly based on agile processes and automated testing. extract, transform, load) projects are often devoid of automated testing. The […].
Summary: This article highlights the primary differences between JDBC and ODBC and their unique applications and use cases. JDBC, for Java-specific environments, offers efficient Java-based database connectivity, while ODBC provides a versatile, language-independent solution. What is JDBC?
The post Why ETL Needs Open Source to Address the Long Tail of Integrations appeared first on DATAVERSITY. Over the last year, our team has interviewed more than 200 companies about their data integration use cases. What we discovered is that data integration in 2021 is still a mess. The Unscalable Current Situation At least 80 of […].
Summary: This article explores the significance of ETL Data in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
However, efficient use of ETL pipelines in ML can help make their life much easier. This article explores the importance of ETL pipelines in machine learning, a hands-on example of building ETL pipelines with a popular tool, and suggests the best ways for data engineers to enhance and sustain their pipelines.
Summary: Selecting the right ETL platform is vital for efficient data integration. Introduction In today’s data-driven world, businesses rely heavily on ETL platforms to streamline data integration processes. What is ETL in Data Integration? Let’s explore some real-world applications of ETL in different sectors.
Summary: The ETL process, which consists of data extraction, transformation, and loading, is vital for effective data management. Introduction The ETL process is crucial in modern data management. What is ETL? ETL stands for Extract, Transform, Load.
Have you ever been in a situation when you had to represent the ETL team by being up late for L3 support only to find out that one of your […]. The post Rethinking Extract Transform Load (ETL) Designs appeared first on DATAVERSITY.
In this article we’re going to check what is an Azure function and how we can employ it to create a basic extract, transform and load (ETL) pipeline with minimal code. Extract, transform and Load Before we begin, let’s shed some light on what an ETL pipeline essentially is. One of them is Azure functions.
DataOps, which focuses on automated tools throughout the ETL development cycle, responds to a huge challenge for data integration and ETL projects in general. ETL projects are increasingly based on agile processes and automated testing. extract, transform, load) projects are often devoid of automated testing. The […].
There are advantages and disadvantages to both ETL and ELT. The post Understanding the ETL vs. ELT Alphabet Soup and When to Use Each appeared first on DATAVERSITY. To understand which method is a better fit, it’s important to understand what it means when one letter comes before the other.
The sample data used in this article can be downloaded from the link below, Fruit and Vegetable Prices How much do fruits and vegetables cost? Glue Crawler Setup The next step is setting up a Glue crawler to extract the schema of this file and create a database. Create a Glue Job to perform ETL operations on your data.
In this article, we will delve into the concept of data lakes, explore their differences from data warehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. This ensures data consistency and integrity.
Writing data to an AWS data lake and retrieving it to populate an AWS RDS MS SQL database involves several AWS services and a sequence of steps for data transfer and transformation. This process leverages AWS S3 for the data lake storage, AWS Glue for ETL operations, and AWS Lambda for orchestration.
Big data pipelines operate similarly to traditional ETL (Extract, Transform, Load) pipelines but are designed to handle much larger data volumes. Components of a Big Data Pipeline Data Sources (Collection): Data originates from various sources, such as databases, APIs, and log files.
With a multitude of articles, videos, audio recordings, and other media created daily across news media companies, readers of all types—individual consumers, corporate subscribers, and more—often find it difficult to find news content that is most relevant to them. We describe how to mitigate this limitation later in this post.
And for searching the term you landed on multiple blogs, articles as well YouTube videos, because this is a very vast topic, or I, would say a vast Industry. I’m not saying those are incorrect or wrong even though every article has its mindset behind the term ‘ Data Science ’.
Overview of RAG The RAG pattern lets you retrieve knowledge from external sources, such as PDF documents, wiki articles, or call transcripts, and then use that knowledge to augment the instruction prompt sent to the LLM. Set the parameters for the ETL job as follows and run the job: Set --job_type to BASELINE.
This article is an excerpt from the book Expert Data Modeling with Power BI, Third Edition by Soheil Bakhshi, a completely updated and revised edition of the bestselling guide to Power BI and data modeling. The Datamart’s data is usually stored in databases containing a moving frame required for data analysis, not the full history of data.
David: My technical background is in ETL, data extraction, data engineering and data analytics. An ETL process was built to take the CSV, find the corresponding text articles and load the data into a SQLite database. cord19q has the logic for ETL, building the embeddings index and running the custom BERT QA model.
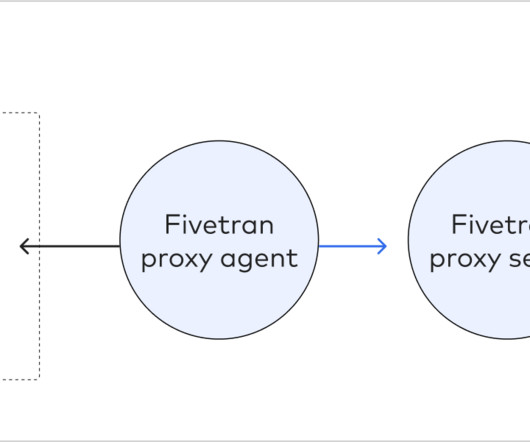
Production databases are a data-rich environment, and Fivetran would help us to migrate data by moving data from on-prem to the supported destinations; ensuring that this data remains uncorrupted throughout enhancements and transformations is crucial. Hence, Fivetran must have a way to connect or establish access to your source database.
The project I did to land my business intelligence internship — CAR BRAND SEARCH ETL PROCESS WITH PYTHON, POSTGRESQL & POWER BI 1. The article will be presented in 5 sections, which will be described as follows: Section 1: Brief description that acts as the motivating foundation of this research. We set up our database in pgadmin4.
What is Matillion ETL? Matillion ETL is a platform designed to help you speed up your data pipeline development by connecting it to many different data sources, enabling teams to rapidly integrate and build sophisticated data transformations in a cloud environment with a very intuitive low-code/no-code GUI. With that, let’s dive in!
With that, let’s dive in What is Matillion ETL? Matillion ETL is a platform designed to help you speed up your data pipeline development by connecting it to many different data sources, enabling teams to rapidly integrate and build sophisticated data transformations in a cloud environment with a very intuitive low-code/no-code GUI.
This article discusses five commonly used architectural design patterns in data engineering and their use cases. ETL Design Pattern The ETL (Extract, Transform, Load) design pattern is a commonly used pattern in data engineering. In the extraction phase, the data is collected from various sources and brought into a staging area.
In recent years, data engineering teams working with the Snowflake Data Cloud platform have embraced the continuous integration/continuous delivery (CI/CD) software development process to develop data products and manage ETL/ELT workloads more efficiently.
This article is a real-life study of building a CI/CD MLOps pipeline. One Data Engineer: Cloud database integration with our cloud expert. If you aren’t aware already, let’s introduce the concept of ETL. ETL usually stands for “Extract, Transform and Load,” and it refers to a process in data warehousing.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Their primary responsibilities include: Data Collection and Preparation Data Scientists start by gathering relevant data from various sources, including databases, APIs, and online platforms. ETL Tools: Apache NiFi, Talend, etc.
In this article, I will explain the modern data stack in detail, list some benefits, and discuss what the future holds. Reverse ETL tools. The modern data stack is also the consequence of a shift in analysis workflow, fromextract, transform, load (ETL) to extract, load, transform (ELT). A Note on the Shift from ETL to ELT.
In this article, I’ll introduce you to a unified architecture for ML systems built around the idea of FTI pipelines and a feature store as the central component. The feature repository is essentially a database storing pre-computed and versioned features. This can seem daunting. It can also transform incoming data on the fly.
This article explores the key fundamentals of Data Engineering, highlighting its significance and providing a roadmap for professionals seeking to excel in this vital field. They are responsible for building and maintaining data architectures, which include databases, data warehouses, and data lakes. million by 2028.
These areas may include SQL, database design, data warehousing, distributed systems, cloud platforms (AWS, Azure, GCP), and data pipelines. ETL (Extract, Transform, Load) This is a core data engineering process for moving data from one or more sources to a destination, typically a data warehouse or data lake. First, articles.
In Matillion ETL, the Git integration enables an organization to connect to any Git offering (e.g., For Matillion ETL, the Git integration requires a stronger understanding of the workflows and systems to effectively manage a larger team. This is a key component of the “Data Productivity Cloud” and closing the ETL gap with Matillion.
In my 7 years of Data Science journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and Apache Hadoop. Now let’s get into the main topic of the article. A well designed database utilizes views at the right place and at the right time.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content