This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction on Big Data & Hadoop The amount of data in our world is growing exponentially. The post Getting Started with Big Data & Hadoop appeared first on Analytics Vidhya. It is estimated that at least 2.5
This article was published as a part of the Data Science Blogathon. HBase is an open-source non-relational, scalable, distributed database written in Java. It is developed as a part of the Hadoop ecosystem and runs on top of HDFS. The post Getting Started with NoSQL Database Called HBase appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Apache Sqoop is a big data engine for transferring data between Hadoop and relational database servers. Sqoop transfers data from RDBMS (Relational Database Management System) such as MySQL and Oracle to HDFS (Hadoop Distributed File System).
This article was published as a part of the Data Science Blogathon. Introduction Since the 1970s, relational database management systems have solved the problems of storing and maintaining large volumes of structured data. The post A Brief Introduction to Apache HBase and it’s Architecture appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction HBase is a column-oriented non-relational database management system that operates on Hadoop Distributed File System (HDFS). HBase provides a fault-tolerant manner of storing sparse data sets, which are prevalent in several big data use cases.
This article was published as a part of the Data Science Blogathon What is the need for Hive? The official description of Hive is- ‘Apache Hive data warehouse software project built on top of Apache Hadoop for providing data query and analysis.
This article was published as a part of the Data Science Blogathon. Introduction Impala is an open-source and native analytics database for Hadoop. Vendors such as Cloudera, Oracle, MapReduce, and Amazon have shipped Impala. If you want to learn all things Impala, you’ve come to the right place.
This article was published as a part of the Data Science Blogathon. Introduction One of the sources of Big Data is the traditional application management system or the interaction of applications with relational databases using RDBMS. Big Data storage and analysis […].
Introduction This article will be a deep guide for Beginners in Apache Oozie. Apache Oozie is a workflow scheduler system for managing Hadoop jobs. It enables users to plan and carry out complex data processing workflows while handling several tasks and operations throughout the Hadoop ecosystem.
This article was published as a part of the Data Science Blogathon. Introduction Hive is a popular data warehouse built on top of Hadoop that is used by companies like Walmart, Tiktok, and AT&T. It is an important technology for data engineers to learn and master. It uses a declarative language called HQL, also known […].
This article was published as a part of the Data Science Blogathon. Different organizations make use of different databases like an oracle database storing transactional data, MySQL for storing product data, and many others for different tasks. storing the data […].
This article was published as a part of the Data Science Blogathon. Relational databases, enterprise data warehouses, and NoSQL systems are all examples of data storage. Introduction Apache SQOOP is a tool designed to aid in the large-scale export and import of data into HDFS from structured data repositories.
The good news is that a number of Hadoop solutions can be invaluable for people that are trying to get the most bang for their buck. How does Hadoop technology help with key couponing and frugal living? Fortunately, Hadoop and other big data technologies are playing an important role in addressing all of these challenges.
In this article, we will discuss about Apache Flume, […] The post A Dive into Apache Flume: Installation, Setup, and Configuration appeared first on Analytics Vidhya. Flume is a tool that is very dependable, distributed, and customizable. einsteinerupload of.
This article was published as a part of the Data Science Blogathon. Introduction Modern applications and products deal with large amounts of data. The quantity of data being processed and utilised in modern times is enormous. So, the question arises? How to manage large files and data.
Summary: This article compares Spark vs Hadoop, highlighting Spark’s fast, in-memory processing and Hadoop’s disk-based, batch processing model. Introduction Apache Spark and Hadoop are potent frameworks for big data processing and distributed computing. What is Apache Hadoop? What is Apache Spark?
Tom Dietterich, a professor of the Department of Electrical Engineering and Computer Science at Portland State University, has written an article on the impact of big data in this field. Maintaining product databases. Database Design Electronic System Management. Advanced Communication Data mining tools like Hadoop.
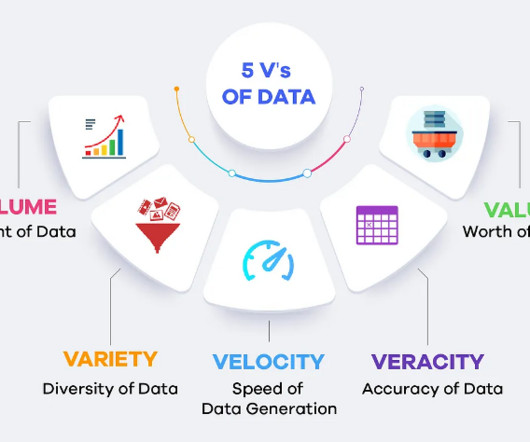
This article was published as a part of the Data Science Blogathon. The post A Beginners’ Guide to Apache Hadoop’s HDFS appeared first on Analytics Vidhya. Introduction With a huge increment in data velocity, value, and veracity, the volume of data is growing exponentially with time.
In this article, we will delve into the concept of data lakes, explore their differences from data warehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. This is particularly advantageous when dealing with exponentially growing data volumes.
And for searching the term you landed on multiple blogs, articles as well YouTube videos, because this is a very vast topic, or I, would say a vast Industry. I’m not saying those are incorrect or wrong even though every article has its mindset behind the term ‘ Data Science ’.
Hadoop, Snowflake, Databricks and other products have rapidly gained adoption. In this article, we’ll focus on a data lake vs. data warehouse. Apache Hadoop, for example, was initially created as a mechanism for distributed storage of large amounts of information. Other platforms defy simple categorization, however.
Summary: This article provides a comprehensive guide on Big Data interview questions, covering beginner to advanced topics. This article helps aspiring candidates excel by covering the most frequently asked Big Data interview questions. Familiarise yourself with essential tools like Hadoop and Spark.
Commonly used technologies for data storage are the Hadoop Distributed File System (HDFS), Amazon S3, Google Cloud Storage (GCS), or Azure Blob Storage, as well as tools like Apache Hive, Apache Spark, and TensorFlow for data processing and analytics. Yes, many people still need a data lake (for their relevant data, not all enterprise data).
Components of a Big Data Pipeline Data Sources (Collection): Data originates from various sources, such as databases, APIs, and log files. Examples include transactional databases, social media feeds, and IoT sensors. Batch Processing: For large datasets, frameworks like Apache Hadoop MapReduce or Apache Spark are used.
This article explores the key fundamentals of Data Engineering, highlighting its significance and providing a roadmap for professionals seeking to excel in this vital field. They are responsible for building and maintaining data architectures, which include databases, data warehouses, and data lakes. million by 2028.
In this article, we are going to look at how software development can leverage on Big Data. This is an organized set of data that can be processed, stored, and retrieved from a database in an orderly format using a simplified search engine algorithm. In the past, the primary source of data was mainly spreadsheets and databases.
They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently.
This article will serve as an ultimate guide to choosing between Data Science and Data Analytics. At the end of this article, you will fully understand what it entails to be a data scientist or data analyst. Before going into the main purpose of this article, what is data? What do you mean by data?
Advances in big data technology like Hadoop, Hive, Spark and Machine Learning algorithms have made it possible to interpret and utilize this variety of data effectively. Structured Structured data is quantitative and highly organized, typically managed within relational databases. Examples include HTML files, graphs, and web pages.
In my 7 years of Data Science journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and Apache Hadoop. Now let’s get into the main topic of the article. A well designed database utilizes views at the right place and at the right time.
This article will guide you through effective strategies to learn Python for Data Science, covering essential resources, libraries, and practical applications to kickstart your journey in this thriving field. Additionally, learn about data storage options like Hadoop and NoSQL databases to handle large datasets.
This article discusses five commonly used architectural design patterns in data engineering and their use cases. It is used to extract data from various sources, transform the data to fit a specific data model or schema, and then load the transformed data into a target system such as a data warehouse or a database.
This article explores the top 10 AI jobs in India and the essential skills required to excel in these roles. Familiarity with SQL for database management. Strong understanding of database management systems (e.g., Hadoop , Apache Spark ) is beneficial for handling large datasets effectively. million by 2027.
This article will discuss managing unstructured data for AI and ML projects. Data can come from different sources, such as databases or directly from users, with additional sources, including platforms like GitHub, Notion, or S3 buckets. Examples of vector databases include Weaviate , ChromaDB , and Qdrant. mp4,webm, etc.),
There are different programming languages and in this article, we will explore 8 programming languages that play a crucial role in the realm of Data Science. SQL: Mastering Data Manipulation Structured Query Language (SQL) is a language designed specifically for managing and manipulating databases. Q: Do Data Scientists Use Can Java?
Apache Pinot is a real-time OLAP database built at LinkedIn to deliver scalable real-time analytics with low latency. It can ingest from batch data sources (such as Hadoop HDFS, Amazon S3, and Google Cloud Storage) as well as stream data sources (such as Apache Kafka and Redpanda). He tweets at @markhneedham.
In this article, we will discuss the importance of data versioning control in machine learning and explore various methods and tools for implementing it with different types of data sources. Data from different formats, databases, and sources are combined together for modeling. Basically, every machine learning project needs data.
In this article, we’ll explore how AI can transform unstructured data into actionable intelligence, empowering you to make informed decisions, enhance customer experiences, and stay ahead of the competition. Vector Databases With unprecedented data being generated, we must store and retrieve it efficiently.
That’s why, in this article, we’ll explore why data science is not only a good career choice but also a thriving and promising one. Big data tools : Familiarity with big data tools like Hadoop, Spark, and NoSQL databases is advantageous for handling large-scale datasets. Is data science a good career?
This article endeavors to alleviate those confusions. data platforms and databases), all interacting with one another to provide greater value. A data fabric can consist of multiple data warehouses, data lakes, IoT/Edge devices and transactional databases. While this is encouraging, it is also creating confusion in the market.
This article compares Tableau and Power BI, examining their features, pricing, and suitability for different organisations. This article will guide readers in selecting the right BI tool—Tableau or Power BI—for their needs in 2024. Tableau supports many data sources, including cloud databases, SQL databases, and Big Data platforms.
In this article, let’s understand an explanation of how to enhance problem-solving skills as a data engineer. Hadoop, Spark). Hadoop, Spark). Understanding these fundamentals is essential for effective problem-solving in data engineering.
This article will explore popular data transformation tools, highlighting their key features and how they can enhance data processing in various applications. It integrates well with cloud services, databases, and big data platforms like Hadoop, making it suitable for various data environments. What is Data Transformation?
As models become more complex and the needs of the organization evolve and demand greater predictive abilities, you’ll also find that machine learning engineers use specialized tools such as Hadoop and Apache Spark for large-scale data processing and distributed computing. Check it out here !
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content