This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon. Introduction to Classification Algorithms In this article, we shall analyze loan risk using 2 different supervisedlearning classification algorithms. These algorithms are decisiontrees and random forests.
This article was published as a part of the Data Science Blogathon. Types of Machine Learning Algorithms 3. DecisionTree 7. Machine Learning […]. Table of Contents 1. Introduction 2. Simple Linear Regression 4. Multilinear Regression 5. Logistic Regression 6.
as described via the relevant Wikipedia article here: [link] ) and other factors, the digital age will keep producing hardware and software tools that are both wondrous, and/or overwhelming (e.g., For instance, in the table below, we juxtapose four authors’ professional opinions with DS-Dojo’s curriculum. IoT, Web 3.0,
Arguably, one of the most important concepts in machine learning is classification. This article will illustrate the difference between classification and regression in machine learning. In this article, I’ve covered one of the most famous classification and regression algorithms in machine learning, namely the DecisionTree.
Machine learning is playing a very important role in improving the functionality of task management applications. In January, Towards Data Science published an article on this very topic. “In Although there are many types of learning, Michalski defined the two most common types of learning: SupervisedLearning.
To harness this data effectively, researchers and programmers frequently employ machine learning to enhance user experiences. Emerging daily are sophisticated methodologies for data scientists encompassing supervised, unsupervised, and reinforcement learning techniques. Is reinforcement learningsupervised or unsupervised?
Multi-class classification in machine learning Multi-class classification in machine learning is a type of supervisedlearning problem where the goal is to predict one of multiple classes or categories based on input features.
We shall look at various types of machine learning algorithms such as decisiontrees, random forest, K nearest neighbor, and naïve Bayes and how you can call their libraries in R studios, including executing the code. R Studios and GIS In a previous article, I wrote about GIS and R., Types of machine learning with R.
In this article, we’ll explore what random forests are, why they’re practical, and how to use them. Since random forests are a subset of supervisedlearning algorithms, they depend on labeled data. The algorithm builds a collection of decisiontrees and models that segment data into branches according to specific criteria.
Artificial intelligence (AI) is a broad term that encompasses the ability of computers and machines to perform tasks that normally require human intelligence, such as reasoning, learning, decision-making, and problem-solving. Let’s dig deeper and learn more about them!
Artificial intelligence (AI) is a broad term that encompasses the ability of computers and machines to perform tasks that normally require human intelligence, such as reasoning, learning, decision-making, and problem-solving. Let’s dig deeper and learn more about them!
Basically, Machine learning is a part of the Artificial intelligence field, which is mainly defined as a technic that gives the possibility to predict the future based on a massive amount of past known or unknown data. ML algorithms can be broadly divided into supervisedlearning , unsupervised learning , and reinforcement learning.
Summary: The blog provides a comprehensive overview of Machine Learning Models, emphasising their significance in modern technology. It covers types of Machine Learning, key concepts, and essential steps for building effective models. The global Machine Learning market was valued at USD 35.80 billion by 2031 at a CAGR of 34.20%.
In the subsequent sections of this article, we will explore the challenges and limitations associated with artificial intelligence in IoT, as well as the key technologies and techniques driving this convergence. These advantages have a transformative impact across various industries and domains.
Summary : This article equips Data Analysts with a solid foundation of key Data Science terms, from A to Z. By understanding crucial concepts like Machine Learning, Data Mining, and Predictive Modelling, analysts can communicate effectively, collaborate with cross-functional teams, and make informed decisions that drive business success.
Among the different learning paradigms in Machine Learnin g, “Eager Learning” and “Lazy Learning” are two prominent approaches. In this article, we will delve into the differences and characteristics of these two methods, shedding light on their unique advantages and use cases.
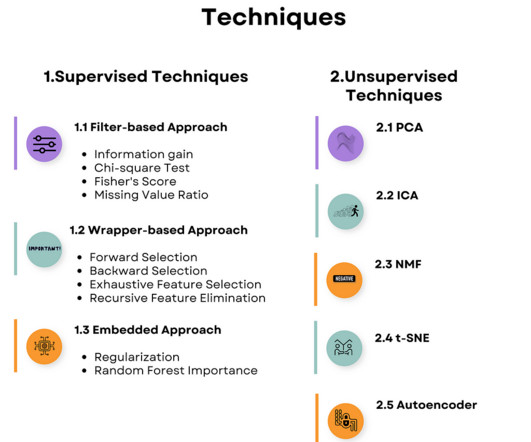
We’ll answer exactly that question in this article. The two main categories of feature selection are supervised and unsupervised machine learning techniques. The two main categories of feature selection are supervised and unsupervised machine learning techniques. Here’s the overview.
Before we feed data into a learning algorithm, we need to make sure that we pre-process the data. This article will discuss the Top 4 Recommendations for building amazing training datasets. DecisionTrees and Random Forests are scale-invariant. If you like this article, please clap. 2019) Python Machine Learning.
However, these models are evolving, with machine learning now playing an essential role in refining and improving the accuracy and efficiency of credit scoring and decisioning. Now that we have a firm grasp on the underlying business case, we will now define a machine learning pipeline in the context of credit models.
This blog explores the difference between Machine Learning and Deep Learning , highlighting their unique characteristics, benefits, and challenges. This article aims to provide a clear comparison, helping you understand when to use Machine Learning and when to opt for Deep Learning based on specific needs and resources.
Subcategories of machine learning Some of the most commonly used machine learning algorithms include linear regression , logistic regression, decisiontree , Support Vector Machine (SVM) algorithm, Naïve Bayes algorithm and KNN algorithm.
With advances in machine learning, deep learning, and natural language processing, the possibilities of what we can create with AI are limitless. In this article, we will explore the essential steps involved in creating AI and the tools and techniques required to build robust and reliable AI systems. Can I create my own AI?
Summary: This article compares Artificial Intelligence (AI) vs Machine Learning (ML), clarifying their definitions, applications, and key differences. While AI aims to replicate human intelligence across various domains, ML focuses on learning from data to improve performance.
It showcases expertise and demonstrates a commitment to continuous learning and growth. This article aims to guide you through the intricacies of Data Analyst interviews, offering valuable insights with a comprehensive list of top questions. Explain the difference between supervised and unsupervised learning.
They are: Based on shallow, simple, and interpretable machine learning models like support vector machines (SVMs), decisiontrees, or k-nearest neighbors (kNN). Relies on explicit decision boundaries or feature representations for sample selection. This article provides a hands-on implementation of QBC in scikit-learn.
Before we discuss the above related to kernels in machine learning, let’s first go over a few basic concepts: Support Vector Machine , S upport Vectors and Linearly vs. Non-linearly Separable Data. Support Vector Machine Support Vector Machine ( SVM ) is a supervisedlearning algorithm used for classification and regression analysis.
Introduction Artificial Intelligence (AI) and Data Science are revolutionising how we analyse data, make decisions, and solve complex problems. The synergy between AI and Data Science enhances data-driven decision-making, powering innovations across healthcare, finance, and technology industries.
At the core of machine learning, two primary learning techniques drive these innovations. These are known as supervisedlearning and unsupervised learning. Supervisedlearning and unsupervised learning differ in how they process data and extract insights.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.































Let's personalize your content