This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This article was published as a part of the Data Science Blogathon Introduction Spark is an analytics engine that is used by data scientists all over the world for Big Data Processing. It is built on top of Hadoop and can process batch as well as streaming data. Hadoop is a framework for distributed computing that […].
This article was published as a part of the Data Science Blogathon. Introduction Apache Hive is a data warehouse system built on top of Hadoop which gives the user the flexibility to write complex MapReduce programs in form of SQL- like queries.
This article was published as a part of the Data Science Blogathon What is the need for Hive? The official description of Hive is- ‘Apache Hive data warehouse software project built on top of Apache Hadoop for providing data query and analysis.
This article was published as a part of the Data Science Blogathon. Introduction Apache Hadoop is the most used open-source framework in the industry to store and process large data efficiently. Hive is built on the top of Hadoop for providing data storage, query and processing capabilities.
This article was published as a part of the Data Science Blogathon. It is developed as a part of the Hadoop ecosystem and runs on top of HDFS. HBase is an open-source non-relational, scalable, distributed database written in Java. It provides random real-time read and write access to the given data. It is possible to […].
This article was published as a part of the Data Science Blogathon. Introduction Hive is a popular data warehouse built on top of Hadoop that is used by companies like Walmart, Tiktok, and AT&T. It is an important technology for data engineers to learn and master. It uses a declarative language called HQL, also known […].
Python, R, and SQL: These are the most popular programming languages for data science. Hadoop and Spark: These are like powerful computers that can process huge amounts of data quickly. Python, R, and SQL: These are the most popular programming languages for data science. Statistics provides the language to do this effectively.
Summary: This article compares Spark vs Hadoop, highlighting Spark’s fast, in-memory processing and Hadoop’s disk-based, batch processing model. Introduction Apache Spark and Hadoop are potent frameworks for big data processing and distributed computing. What is Apache Hadoop? What is Apache Spark?
This article was published as a part of the Data Science Blogathon. Introduction Hi Everyone, In this guide, we will discuss Apache Sqoop. We will discuss the Sqoop import and export processes with different modes and also cover Sqoop-hive integration. In this guide, I will go over Apache Sqoop in depth so that whenever you […].
At first glance, they may seem like two sides of the same coin, but a closer look reveals distinct differences and unique career opportunities. This article aims to demystify these domains, shedding light on what sets them apart, the essential skills they demand, and how to navigate a career path in either field. What is Coding?
Python, R, and SQL: These are the most popular programming languages for data science. Hadoop and Spark: These are like powerful computers that can process huge amounts of data quickly. Python, R, and SQL: These are the most popular programming languages for data science. Statistics provides the language to do this effectively.
This article explains what PySpark is, some common PySpark functions, and data analysis of the New York City Taxi & Limousine Commission Dataset using PySpark. With PySpark, you can write Python and SQL-like commands to manipulate and analyze data in a distributed processing environment. This member-only story is on us.
This article helps you choose the right path by exploring their differences, roles, and future opportunities. Descriptive analytics is a fundamental method that summarizes past data using tools like Excel or SQL to generate reports. Big data platforms such as Apache Hadoop and Spark help handle massive datasets efficiently.
Summary: This article provides a comprehensive guide on Big Data interview questions, covering beginner to advanced topics. This article helps aspiring candidates excel by covering the most frequently asked Big Data interview questions. Familiarise yourself with essential tools like Hadoop and Spark. What is YARN in Hadoop?
Alation catalogs and crawls all of your data assets, whether it is in a traditional relational data set (MySQL, Oracle, etc), a SQL on Hadoop system (Presto, SparkSQL,etc), a BI visualization or something in a file system, such as HDFS or AWS S3.
With expertise in programming languages like Python , Java , SQL, and knowledge of big data technologies like Hadoop and Spark, data engineers optimize pipelines for data scientists and analysts to access valuable insights efficiently. Big Data Technologies: Hadoop, Spark, etc. ETL Tools: Apache NiFi, Talend, etc.
In this article, we will delve into the concept of data lakes, explore their differences from data warehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management. This is particularly advantageous when dealing with exponentially growing data volumes.
There are different programming languages and in this article, we will explore 8 programming languages that play a crucial role in the realm of Data Science. SQL: Mastering Data Manipulation Structured Query Language (SQL) is a language designed specifically for managing and manipulating databases.
This article explores the key fundamentals of Data Engineering, highlighting its significance and providing a roadmap for professionals seeking to excel in this vital field. Among these tools, Apache Hadoop, Apache Spark, and Apache Kafka stand out for their unique capabilities and widespread usage. million by 2028.
This article explores the top 10 AI jobs in India and the essential skills required to excel in these roles. Proficiency in programming languages like Python and SQL. Familiarity with SQL for database management. Hadoop , Apache Spark ) is beneficial for handling large datasets effectively. million by 2027.
In my 7 years of Data Science journey, I’ve been exposed to a number of different databases including but not limited to Oracle Database, MS SQL, MySQL, EDW, and Apache Hadoop. Now let’s get into the main topic of the article. I’ll leave these methods on you to embark on your own research and familiarize yourself.
This article will serve as an ultimate guide to choosing between Data Science and Data Analytics. At the end of this article, you will fully understand what it entails to be a data scientist or data analyst. Before going into the main purpose of this article, what is data? What do you mean by data?
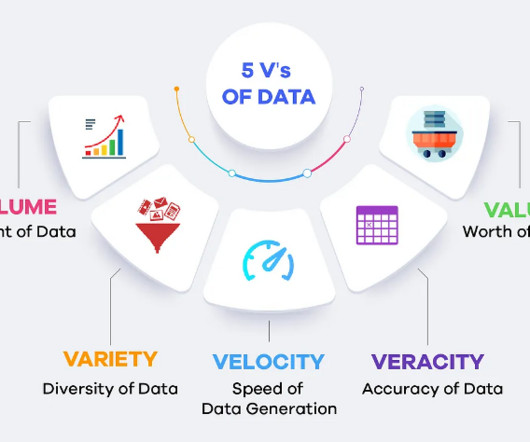
Advances in big data technology like Hadoop, Hive, Spark and Machine Learning algorithms have made it possible to interpret and utilize this variety of data effectively. Examples include Excel files, SQL databases, and data warehouses. Variety Data comes in a myriad of formats including text, images, videos, and more.
The fields have evolved such that to work as a data analyst who views, manages and accesses data, you need to know Structured Query Language (SQL) as well as math, statistics, data visualization (to present the results to stakeholders) and data mining. It’s also necessary to understand data cleaning and processing techniques.
That’s why, in this article, we’ll explore why data science is not only a good career choice but also a thriving and promising one. Big data tools : Familiarity with big data tools like Hadoop, Spark, and NoSQL databases is advantageous for handling large-scale datasets. Is data science a good career?
This article compares Tableau and Power BI, examining their features, pricing, and suitability for different organisations. This article will guide readers in selecting the right BI tool—Tableau or Power BI—for their needs in 2024. Tableau supports many data sources, including cloud databases, SQL databases, and Big Data platforms.
In this article, let’s understand an explanation of how to enhance problem-solving skills as a data engineer. Hadoop, Spark). Hadoop, Spark). Practice coding with the help of languages that are used in data engineering like Python, SQL, Scala, or Java.
Because they are the most likely to communicate data insights, they’ll also need to know SQL, and visualization tools such as Power BI and Tableau as well. Like their counterparts in the machine learning world, engineers need to know a variety of scripted languages such as SQL for database management, Scala, Java, and of course Python.
For instance, technical power users can explore the actual data through Compose , the intelligent SQL editor. Those less familiar with SQL can search for technical terms using natural language. The data catalog supports human understanding by surfacing useful metadata (like usage statistics, conversations, and wiki-like articles).
This article throws light on the 10 best cities for Data Scientists offering the best Data Science salary in India. With the abundance of data available, organizations across various industries are leveraging data science to gain valuable insights and make informed decisions. What is Data Science?
In this article, we will discuss the importance of data versioning control in machine learning and explore various methods and tools for implementing it with different types of data sources. LakeFS is fully compatible with many ecosystems of data engineering tools such as AWS, Azure, Spark, Databrick, MlFlow, Hadoop and others.
This article endeavors to alleviate those confusions. It can include technologies that range from Oracle, Teradata and Apache Hadoop to Snowflake on Azure, RedShift on AWS or MS SQL in the on-premises data center, to name just a few. While this is encouraging, it is also creating confusion in the market.
This article will discuss managing unstructured data for AI and ML projects. Here’s the structured equivalent of this same data in tabular form: With structured data, you can use query languages like SQL to extract and interpret information. Popular data lake solutions include Amazon S3 , Azure Data Lake , and Hadoop.
This article will guide you through the concept of a data quality framework, its essential components, and how to implement it effectively within your organization. Other Apache Griffin is an open-source data quality solution for big data environments, particularly within the Hadoop and Spark ecosystems.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content