This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
SupportVectorMachine: A Comprehensive Guide — Part1 SupportVectorMachines (SVMs) are a type of supervised learning algorithm used for classification and regression analysis. I will cover only the first 5 subtopics in this article and will cover the rest in my next upcoming article.
SupportVectorMachine: A Comprehensive Guide — Part2 In my last article, we discussed SVMs, the geometric intuition behind SVMs, and also Soft and Hard margins. Transformed Data into 2-D Data Conclusion SupportVectorMachines (SVMs) offer a powerful framework for classification and regression tasks.
Rustic Learning: Machine Learning in Rust — Part 2: Regression and Classification An Introduction to Rust’s Machine Learning crates Photo by Malik Skydsgaard on Unsplash Rustic Learning is a series of articles that explores the use of Rust programming language for machine learning tasks.
It’s also an area that stands to benefit most from automated or semi-automated machine learning (ML) and natural language processing (NLP) techniques. Over the past several years, researchers have increasingly attempted to improve the data extraction process through various ML techniques. This study by Bui et al.
R has simplified the most complex task of geospatial machine learning and data science. Hopefully, this article will serve as a roadmap for leveraging the power of R, a versatile programming language, for spatial analysis, data science and visualization within GIS contexts. I wrote about Python ML here. data = trainData) 5.
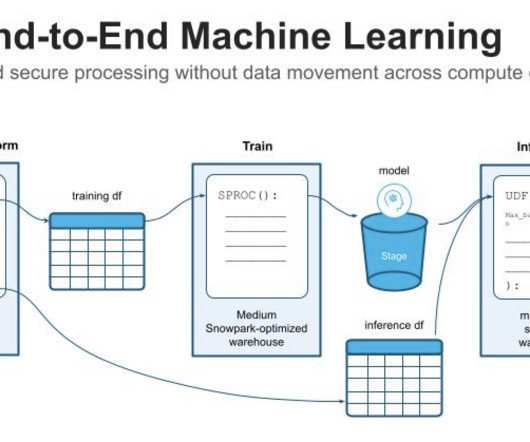
However, these models are evolving, with machine learning now playing an essential role in refining and improving the accuracy and efficiency of credit scoring and decisioning. What Does a Credit Score or Decisioning ML Pipeline Look Like? Say we are part of an ML team working on a decisioning model. Want to learn more?
Images used in my articles are Properties of the Respective Organisations and are used here solely for Reference, Illustrative and Educational Purposes Only. Hand-Written Digits This problem is a simple example of pattern recognition and is widely used in Image Processing and Machine Learning.
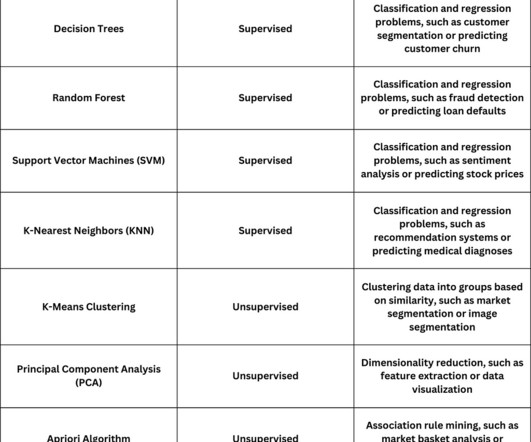
Photo by Andy Kelly on Unsplash Choosing a machine learning (ML) or deep learning (DL) algorithm for application is one of the major issues for artificial intelligence (AI) engineers and also data scientists. ML algorithms and their application [table by author] Table 2. Here I wan to clarify this issue.
In this article, we will explore how AI drug discovery is changing the industry. Machine Learning Machine learning (ML) focuses on training computer algorithms to learn from data and improve their performance, without being explicitly programmed. Hence, the interest in finding new ways we discover and design drugs.
The pedestrian died, and investigators found that there was an issue with the machine learning (ML) model in the car, so it failed to identify the pedestrian beforehand. Therefore, let’s examine how you can improve the overall accuracy of your machine learning models so that they perform well and make reliable and safe predictions.
In this article, we’ll look at the evolution of these state-of-the-art (SOTA) models and algorithms, the ML techniques behind them, the people who envisioned them, and the papers that introduced them. Evolution of SOTA models in NLP and factors affecting them Here is the evolutionary map for this article.
To address this challenge, data scientists harness the power of machine learning to predict customer churn and develop strategies for customer retention. I write about Machine Learning on Medium || Github || Kaggle || Linkedin. ? Our project uses Comet ML to: 1. The entire code can be found on both GitHub and Kaggle.
⚠ You can solve the below-mentioned questions from this blog ⚠ ✔ What if I am building Low code — No code ML automation tool and I do not have any orchestrator or memory management system ? ✔ how to reduce the complexity and computational expensiveness of ML models ? will my data help in this ?
Basically, Machine learning is a part of the Artificial intelligence field, which is mainly defined as a technic that gives the possibility to predict the future based on a massive amount of past known or unknown data. ML algorithms can be broadly divided into supervised learning , unsupervised learning , and reinforcement learning.
Today, we see tools and systems with machine-learning capabilities in almost every industry. Healthcare organizations are using healthcare AI/ML solutions to achieve operational efficiency and deliver quality patient care. Finance institutions are using machine learning to overcome healthcare fraud challenges. Isn’t it so?
Introduction Machine Learning (ML) is revolutionising the business world by enabling companies to make smarter, data-driven decisions. As an advanced technology that learns from data patterns, ML automates processes, enhances efficiency, and personalises customer experiences. What is Machine Learning?
Summary: Machine Learning and Deep Learning are AI subsets with distinct applications. ML works with structured data, while DL processes complex, unstructured data. ML requires less computing power, whereas DL excels with large datasets. Key Takeaways ML requires structured data, while DL handles complex, unstructured data.
Source: [link] Similarly, while building any machine learning-based product or service, training and evaluating the model on a few real-world samples does not necessarily mean the end of your responsibilities. We are going to discuss all of them later in this article.
Photo by Shahadat Rahman on Unsplash Introduction Machine learning (ML) focuses on developing algorithms and models that can learn from data and make predictions or decisions. One of the goals of ML is to enable computers to process and analyze data in a way that is similar to how humans process information.
Artificial intelligence (AI) is a broad term that encompasses the ability of computers and machines to perform tasks that normally require human intelligence, such as reasoning, learning, decision-making, and problem-solving. But first, let’s start from the bottom and better understand where we are now in the age of AI.
Artificial intelligence (AI) is a broad term that encompasses the ability of computers and machines to perform tasks that normally require human intelligence, such as reasoning, learning, decision-making, and problem-solving. But first, let’s start from the bottom and better understand where we are now in the age of AI.
In this comprehensive article, we delve into the depths of feature scaling in Machine Learning, uncovering its importance, methods, and advantages while showcasing practical examples using Python. Understanding Feature Scaling in Machine Learning: Feature scaling stands out as a fundamental process.
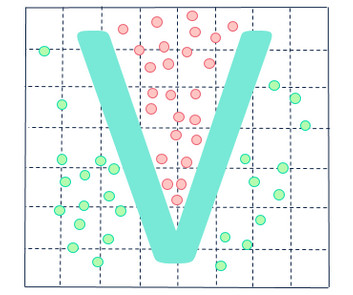
Before we discuss the above related to kernels in machine learning, let’s first go over a few basic concepts: SupportVectorMachine , S upport Vectors and Linearly vs. Non-linearly Separable Data. The linear kernel is ideal for linear problems, such as logistic regression or supportvectormachines ( SVMs ).
What is machine learning? Machine learning (ML) is a subset of artificial intelligence (AI) that focuses on learning from what the data science comes up with. Some examples of data science use cases include: An international bank uses ML-powered credit risk models to deliver faster loans over a mobile app.
One such intriguing aspect is the potential to predict a user’s race based on their tweets, a task that merges the realms of Natural Language Processing (NLP), machine learning, and sociolinguistics. With the preprocessed data in hand, we can now employ pyCaret, a powerful machine learning library, to build our predictive models.
Keras is popular high-level API machine learning framework in python that was created by Google. This particular article is about the loss functions available in Keras. Hinge Losses — Another set of losses for classification problems, but commonly used in supportvectormachines. Example taken from docs.
PyTorch This essential library is an open-source ML framework capable of speeding up research prototyping, allowing companies to enter the production deployment phase. Key PyTorch features include robust cloud support, a rich ecosystem of tools, distributed training and native ONNX (Open Neural Network Exchange) support.
In the subsequent sections of this article, we will explore the challenges and limitations associated with artificial intelligence in IoT, as well as the key technologies and techniques driving this convergence. Unsupervised learning Unsupervised learning involves training machine learning models with unlabeled datasets.
Revolutionizing Healthcare through Data Science and Machine Learning Image by Cai Fang on Unsplash Introduction In the digital transformation era, healthcare is experiencing a paradigm shift driven by integrating data science, machine learning, and information technology.
This article delves into using deep learning to enhance the effectiveness of classic ML models. Background Information Decision trees, random forests, and linear regression are just a few examples of classic machine-learning models that have been used extensively in business for years.
I hope you find this article to be helpful. The algorithm works by fitting a hyperplane that encloses the normal data points while excluding the anomalies. Hopefully this blog has provided you with a comprehensive overview of anomaly detection methods and how to implement them using Python code. If you’d like, add me on LinkedIn !
Hidden secret to empower semantic search This is the third article of building LLM-powered AI applications series. From the previous article , we know that in order to provide context to LLM, we need semantic search and complex query to find relevant context (traditional keyword search, full-text search won’t be enough).
Conclusion In this article, we introduced the concept of calibration in deep neural networks. Supportvectormachine classifiers as applied to AVIRIS data.” We’re committed to supporting and inspiring developers and engineers from all walks of life. Refer to Table 1 of the paper for an overview of all the results.
With advances in machine learning, deep learning, and natural language processing, the possibilities of what we can create with AI are limitless. In this article, we will explore the essential steps involved in creating AI and the tools and techniques required to build robust and reliable AI systems. Can I create my own AI?
This data needs to be analysed and be in a structured manner whether it is in the form of emails, texts, documents, articles, and many more. Heres a general overview of the steps: Preprocessing Collecting the text data to be analysed, such as customer reviews, social media posts, or news articles. HTML tags, special characters).
This comprehensive article explores the pivotal role of bioinformatics in advancing biological research, focusing on its real-life applications, remarkable achievements, and the machine learning tools that have propelled the field forward. We’re committed to supporting and inspiring developers and engineers from all walks of life.
The concepts of bias and variance in Machine Learning are two crucial aspects in the realm of statistical modelling and machine learning. Understanding these concepts is paramount for any data scientist, machine learning engineer, or researcher striving to build robust and accurate models. to enhance your skills.
This article explores how AI and Data Science complement each other, highlighting their combined impact and potential. Machine Learning Machine Learning (ML) is a crucial component of Data Science. ML models help predict outcomes, automate tasks, and improve decision-making by identifying patterns in large datasets.
Hinge Loss (SVM Loss): Used for supportvectormachine (SVM) and binary classification problems. R² = 1 — (MSE(model) / MSE(mean value)) Conclusion In this article, we learned how a basic deep learning structure works. We're committed to supporting and inspiring developers and engineers from all walks of life.
Text categorization is supported by a number of programming languages, including R, Python, and Weka, but the main focus of this article will be text classification with R. This article will look at how R can be used to execute text categorization tasks efficiently. We pay our contributors, and we don’t sell ads.
In this article, we will explore some common data science interview questions that will help you prepare and increase your chances of success. Let us first understand the meaning of bias and variance in detail: Bias: It is a kind of error in a machine learning model when an ML Algorithm is oversimplified.
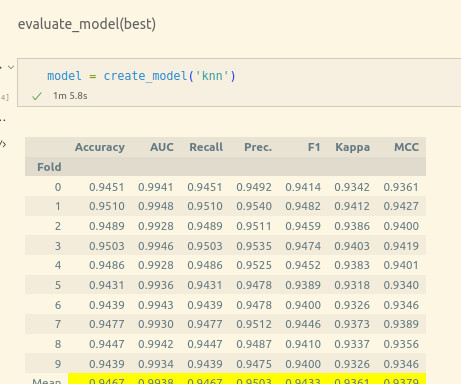
The accuracy of the ML model indicates how many times it was correct overall. Please do follow my page if you gained anything useful from the article. Prediction of Solar Irradiation Using Quantum SupportVectorMachine Learning Algorithm. Precision refers to how well the model predicts a certain category.
Photo by the author Recently I was given a Myo armband, and this article aims to describe how such a device could be exploited to control a robotic manipulator intuitively. I tried several other machine learning classifiers, but SVM turned out to be the best. That is, we will move our arm as if it was the actual hand of the robot.
They are: Based on shallow, simple, and interpretable machine learning models like supportvectormachines (SVMs), decision trees, or k-nearest neighbors (kNN). You can explore more on this topic in this article by Lilian Weng or this one. Traditional Active Learning has the following characteristics.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content