This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction In this article, we will be discussing SupportVectorMachines. The post SupportVectorMachine: Introduction appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon Introduction to SupportVectorMachine(SVM) SVM is a powerful supervised algorithm that works best on smaller datasets but on complex ones. The post SupportVectorMachine(SVM): A Complete guide for beginners appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. The post Understanding Naïve Bayes and SupportVectorMachine and their implementation in Python appeared first on Analytics Vidhya. Introduction In this digital world, spam is the most troublesome challenge that.
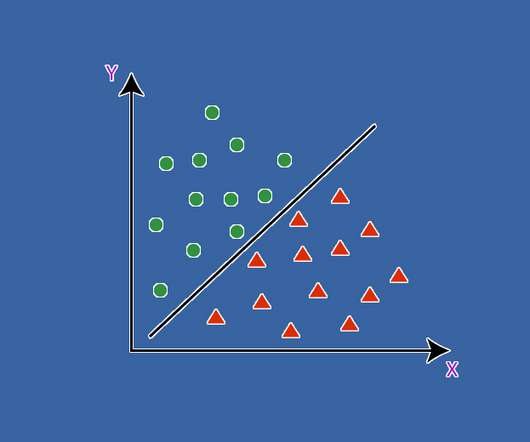
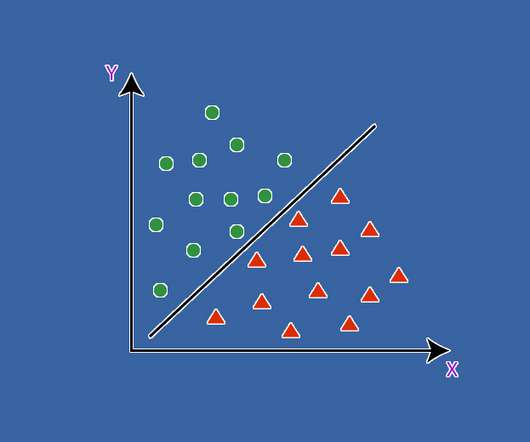
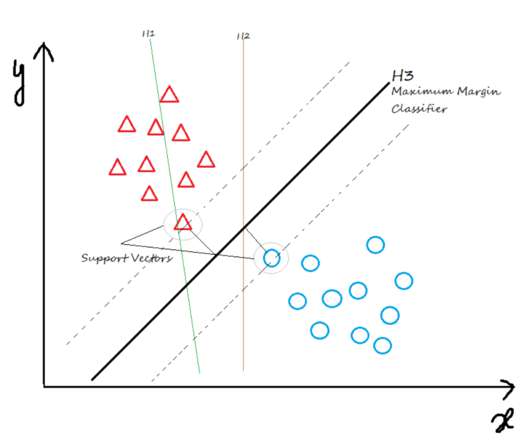
This article was published as a part of the Data Science Blogathon. Introduction This article will cover the concepts of Iterators, Generators, and Decorators in Python. Later, we will discuss the Maximal-Margin Classifier and Soft Margin Classifier for SupportVectorMachine.
SupportVectorMachines (SVMs) are powerful for solving regression and classification problems. You should have this approach in your machine learning arsenal, and this article provides all the mathematics you need to know -- it's not as hard you might think.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction SupportVectorMachine (SVM) is one of the Machine Learning. The post The A-Z guide to SupportVectorMachine appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction Classification problems are often solved using supervised learning algorithms such as Random Forest Classifier, SupportVectorMachine, Logistic Regressor (for binary class classification) etc. One-Class […].
This article was published as a part of the Data Science Blogathon Introduction Hello Everyone, I hope you are doing well. Ever wondered, how great would it be, if we could predict, whether our request for a loan, will be approved or not, simply by the use of machine learning, from the ease and comfort […].
This article was published as a part of the Data Science Blogathon. The post The Mathematics Behind SupportVectorMachine Algorithm (SVM) appeared first on Analytics Vidhya. Introduction One of the classifiers that we come across while learning about.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction A SupportVectorMachine (SVM) is a very powerful and. The post SupportVectorMachine and Principal Component Analysis Tutorial for Beginners appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Source Overview In this article, we will learn the working of. The post Start Learning SVM (SupportVectorMachine) Algorithm Here! appeared first on Analytics Vidhya.
ArticleVideo Book This article was published as a part of the Data Science Blogathon. Introduction This article aims to provide a basic understanding. The post Introduction to SVM(SupportVectorMachine) Along with Python Code appeared first on Analytics Vidhya.
Supportvectormachines (SVM) are at the forefront of machine learning techniques used for both classification and regression tasks. This article delves into the essential components of SVM and its advantages and disadvantages, providing a comprehensive overview of its functionalities and challenges.
This article was published as a part of the Data Science Blogathon. Introduction Supportvectormachine is one of the most famous and decorated machine learning algorithms in classification problems.
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Before the sudden rise of neural networks, SupportVectorMachines. The post Top 15 Questions to Test your Data Science Skills on SVM appeared first on Analytics Vidhya.
They are also used in machine learning, such as supportvectormachines and k-means clustering. Robust inference: Robust inference is a technique that is used to make inferences that are not sensitive to outliers or extreme observations. These are often used to infer causal relationships between variables.
SupportVectorMachine: A Comprehensive Guide — Part1 SupportVectorMachines (SVMs) are a type of supervised learning algorithm used for classification and regression analysis. I will cover only the first 5 subtopics in this article and will cover the rest in my next upcoming article.
10 Python packages for data science and machine learning In this article, we will highlight some of the top Python packages for data science that aspiring and practicing data scientists should consider adding to their toolbox. Scikit-learn Scikit-learn is a powerful library for machine learning in Python.
SupportVectorMachine: A Comprehensive Guide — Part2 In my last article, we discussed SVMs, the geometric intuition behind SVMs, and also Soft and Hard margins. Transformed Data into 2-D Data Conclusion SupportVectorMachines (SVMs) offer a powerful framework for classification and regression tasks.
In this article, we’ll dive […] The post Are You Making These Common Mistakes in Classification Modeling? Imagine building a cutting-edge model that dazzles with high accuracy, only to find it crumbles under real-world pressure. appeared first on Analytics Vidhya.
as described via the relevant Wikipedia article here: [link] ) and other factors, the digital age will keep producing hardware and software tools that are both wondrous, and/or overwhelming (e.g., For instance, in the table below, we juxtapose four authors’ professional opinions with DS-Dojo’s curriculum. IoT, Web 3.0,
10 Python packages for data science and machine learning In this article, we will highlight some of the top Python packages for data science that aspiring and practicing data scientists should consider adding to their toolbox. Scikit-learn Scikit-learn is a powerful library for machine learning in Python.
Rustic Learning: Machine Learning in Rust — Part 2: Regression and Classification An Introduction to Rust’s Machine Learning crates Photo by Malik Skydsgaard on Unsplash Rustic Learning is a series of articles that explores the use of Rust programming language for machine learning tasks.
How to use kernels in machine learning Kernels, the unsung heroes of AI and machine learning, wield their transformative magic through algorithms like SupportVectorMachines (SVM).
Summary: SupportVectorMachine (SVM) is a supervised Machine Learning algorithm used for classification and regression tasks. Among the many algorithms, the SVM algorithm in Machine Learning stands out for its accuracy and effectiveness in classification tasks. What is the SVM Algorithm in Machine Learning?
Machine learning is playing a very important role in improving the functionality of task management applications. In January, Towards Data Science published an article on this very topic. “In Both of these types of learning are used by machine learning algorithms in modern task management applications. Logistic Regression.
R has simplified the most complex task of geospatial machine learning and data science. Hopefully, this article will serve as a roadmap for leveraging the power of R, a versatile programming language, for spatial analysis, data science and visualization within GIS contexts. data = trainData) 5.
In this article, we will provide an overview of gradient descent, including the mathematical concepts behind it, the different variants of gradient descent, and the challenges and limitations associated with it. Recommender Systems: In recommender systems, gradient descent is used to optimize […]
Summary: The article explores the differences between data driven and AI driven practices. Develop Hybrid Models Combine traditional analytical methods with modern algorithms such as decision trees, neural networks, and supportvectormachines.
Machine Learning for Beginners Learn the essentials of machine learning including how SupportVectorMachines, Naive Bayesian Classifiers, and Upper Confidence Bound algorithms work. After this talk, you will have an intuitive understanding of these three algorithms and real-life problems where they can be applied.
Images used in my articles are Properties of the Respective Organisations and are used here solely for Reference, Illustrative and Educational Purposes Only. Hand-Written Digits This problem is a simple example of pattern recognition and is widely used in Image Processing and Machine Learning.
This includes one paper from 2020 that conducted feature extraction using a denoising autoencoder alongside a deep neural network, and a flattened vector and supportvectormachines to evaluate study relevance. used ML and NLP to generate automatic summaries of full-text articles, achieving high rates of recall (91.2%
Did you know SupportVector Regression (SVR) represents one of the most powerful predictive modeling techniques in machine learning? As an extension of SupportVectorMachines (SVM) , SupportVector Regression has revolutionized how data scientists approach complex regression problems.
Understanding their differences is essential for businesses looking to implement machine learning effectively. This article provides a clear comparison between supervised and unsupervised learning, covering their unique characteristics, applications, and key differences.
In this article, we’ll look at the evolution of these state-of-the-art (SOTA) models and algorithms, the ML techniques behind them, the people who envisioned them, and the papers that introduced them. Evolution of SOTA models in NLP and factors affecting them Here is the evolutionary map for this article.
This article will explain the concept of hyperparameter tuning and the different methods that are used to perform this tuning, and their implementation using python Photo by Denisse Leon on Unsplash Table of Content Model Parameters Vs Model Hyperparameters What is hyperparameter tuning? C can take any positive float value.
Correctly predicting the tags of the questions is a very challenging problem as it involves the prediction of a large number of labels among several hundred thousand possible labels. In the second part, I will present and explain the four main categories of XML algorithms along with some of their limitations.
In this article, I will show you what algorithm to use for each purpose and attain the desirable outcome you want without spending time going through each algorithm trying to figure out which one you want. – Algorithms: SupportVectorMachines (SVM), Random Forest, Neural Networks.
You can start with simpler algorithms such as decision trees, Naive Bayes , and logistic regression, and steadily move to more complex ones like neural networks and supportvectormachines (SVM). If this article has been able to add to your knowledge, please share it with your colleagues and link it to your stories.
In this article, we will discuss some of the factors to consider while selecting a classification & Regression machine learning algorithm based on the characteristics of the data. For larger datasets, more complex algorithms such as Random Forest, SupportVectorMachines (SVM), or Neural Networks may be more suitable.
Some popular classification algorithms include logistic regression, decision trees, random forests, supportvectormachines (SVMs), and neural networks. Choose a suitable classification algorithm based on the type of classification problem and the data.
In this article, we will delve into the concepts of generative and discriminative models, exploring their definitions, working principles, and applications. SupportVectorMachines (SVM): SVM finds an optimal hyperplane to separate different classes in high-dimensional spaces. What are some popular discriminative models?
In this article, we will explore how AI drug discovery is changing the industry. Hence, the interest in finding new ways we discover and design drugs. AI has already helped identify promising candidate therapeutics, and it didn’t take years but months or even days. We will look at success stories, AI benefits, and limitations.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














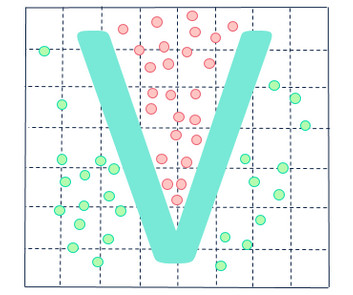


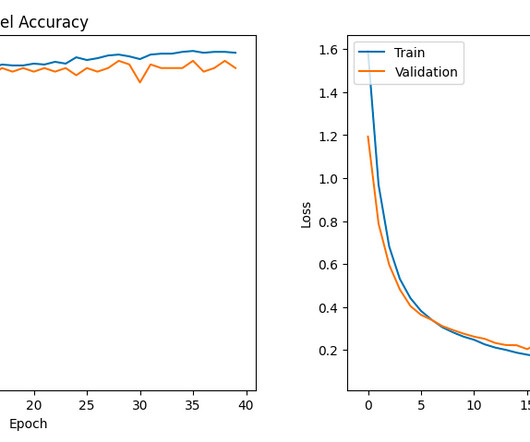


















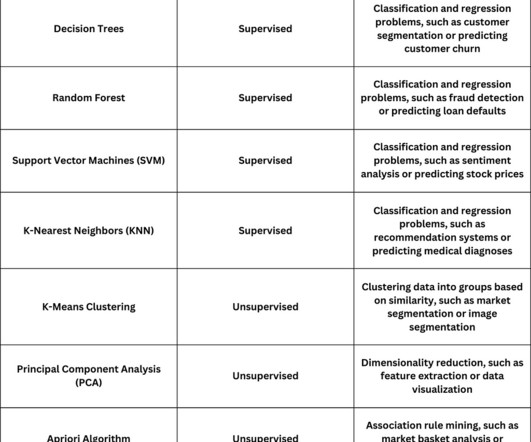










Let's personalize your content