This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
If you’re diving into the world of machine learning, AWS Machine Learning provides a robust and accessible platform to turn your data science dreams into reality. Whether you’re a solo developer or part of a large enterprise, AWS provides scalable solutions that grow with your needs. Hey dear reader!
Lets assume that the question What date will AWS re:invent 2024 occur? The corresponding answer is also input as AWS re:Invent 2024 takes place on December 26, 2024. If the question was Whats the schedule for AWS events in December?, This setup uses the AWS SDK for Python (Boto3) to interact with AWS services.
It seems straightforward at first for batch data, but the engineering gets even more complicated when you need to go from batch data to incorporating real-time and streaming data sources, and from batch inference to real-time serving. You can also find Tecton at AWS re:Invent.
Purina used artificialintelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The AWS Cloud Development Kit (AWS CDK) is an open-source software development framework for defining cloud infrastructure as code with modern programming languages and deploying it through AWS CloudFormation.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificialintelligence (AI) to personalize experiences at scale. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
Data engineers build datapipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these datapipelines in an overall workflow. Organizations can harness the full potential of their data while reducing risk and lowering costs.
It is used by businesses across industries for a wide range of applications, including fraud prevention, marketing automation, customer service, artificialintelligence (AI), chatbots, virtual assistants, and recommendations. AWS SageMaker also has a CLI for model creation and management.
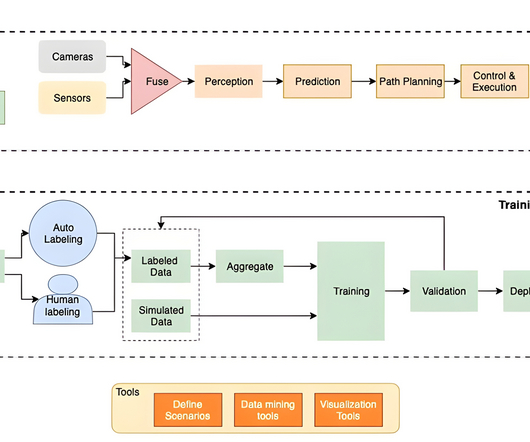
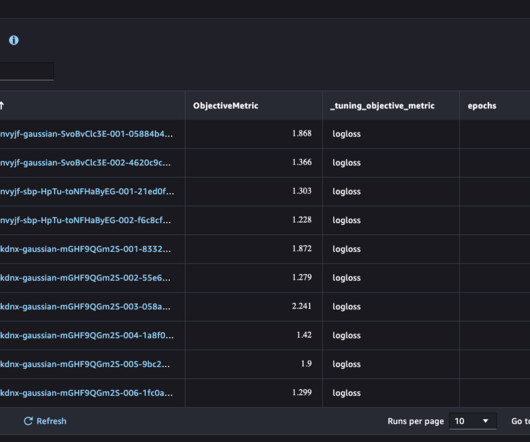
For more information about distributed training with SageMaker, refer to the AWS re:Invent 2020 video Fast training and near-linear scaling with DataParallel in Amazon SageMaker and The science behind Amazon SageMaker’s distributed-training engines. In a later post, we will do a deep dive into the DNNs used by ADAS systems.
SnapLogic uses Amazon Bedrock to build its platform, capitalizing on the proximity to data already stored in Amazon Web Services (AWS). Control plane and data plane implementation SnapLogic’s Agent Creator platform follows a decoupled architecture, separating the control plane and data plane for enhanced security and scalability.
In an era where cloud technology is not just an option but a necessity for competitive business operations, the collaboration between Precisely and Amazon Web Services (AWS) has set a new benchmark for mainframe and IBM i modernization. Solution page Precisely on Amazon Web Services (AWS) Precisely brings data integrity to the AWS cloud.
Each platform offers unique capabilities tailored to varying needs, making the platform a critical decision for any Data Science project. Major Cloud Platforms for Data Science Amazon Web Services ( AWS ), Microsoft Azure, and Google Cloud Platform (GCP) dominate the cloud market with their comprehensive offerings.
Consider the following picture, which is an AWS view of the a16z emerging application stack for large language models (LLMs). This pipeline could be a batch pipeline if you prepare contextual data in advance, or a low-latency pipeline if you’re incorporating new contextual data on the fly.
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. As always, AWS welcomes your feedback.
SageMaker Feature Store now makes it effortless to share, discover, and access feature groups across AWS accounts. With this launch, account owners can grant access to select feature groups by other accounts using AWS Resource Access Manager (AWS RAM). Their task is to construct and oversee efficient datapipelines.
In this post, we will talk about how BMW Group, in collaboration with AWS Professional Services, built its Jupyter Managed (JuMa) service to address these challenges. For example, teams using these platforms missed an easy migration of their AI/ML prototypes to the industrialization of the solution running on AWS.
Generative artificialintelligence (generative AI) has enabled new possibilities for building intelligent systems. Given the data sources, LLMs provided tools that would allow us to build a Q&A chatbot in weeks, rather than what may have taken years previously, and likely with worse performance.
Instead, organizations are increasingly looking to take advantage of transformative technologies like machine learning (ML) and artificialintelligence (AI) to deliver innovative products, improve outcomes, and gain operational efficiencies at scale.
Confluent Confluent provides a robust data streaming platform built around Apache Kafka. AI credits from Confluent can be used to implement real-time datapipelines, monitor data flows, and run stream-based ML applications.
In order to train a model using data stored outside of the three supported storage services, the data first needs to be ingested into one of these services (typically Amazon S3). This requires building a datapipeline (using tools such as Amazon SageMaker Data Wrangler ) to move data into Amazon S3.
In this post, we show you how SnapLogic , an AWS customer, used Amazon Bedrock to power their SnapGPT product through automated creation of these complex DSL artifacts from human language. SnapLogic background SnapLogic is an AWS customer on a mission to bring enterprise automation to the world.
AWS recently released Amazon SageMaker geospatial capabilities to provide you with satellite imagery and geospatial state-of-the-art machine learning (ML) models, reducing barriers for these types of use cases. In the following sections, we dive into each pipeline in more detail.
As one of the largest AWS customers, Twilio engages with data, artificialintelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. Access to Amazon Bedrock FMs isn’t granted by default.
Whether logs are coming from Amazon Web Services (AWS), other cloud providers, on-premises, or edge devices, customers need to centralize and standardize security data. After the security log data is stored in Amazon Security Lake, the question becomes how to analyze it. Subscribe an AWS Lambda function to the SQS queue.
Working with the AWS Generative AI Innovation Center , DoorDash built a solution to provide Dashers with a low-latency self-service voice experience to answer frequently asked questions, reducing the need for live agent assistance, in just 2 months. “We You can deploy the solution in your own AWS account and try the example solution.
In this post, we discuss how to bring data stored in Amazon DocumentDB into SageMaker Canvas and use that data to build ML models for predictive analytics. Without creating and maintaining datapipelines, you will be able to power ML models with your unstructured data stored in Amazon DocumentDB.
Building a deployment pipeline for generative artificialintelligence (AI) applications at scale is a formidable challenge because of the complexities and unique requirements of these systems. Generative AI applications require continuous ingestion, preprocessing, and formatting of vast amounts of data from various sources.
AWS is especially well suited to provide enterprises the tools necessary for deploying LLMs at scale to enable critical decision-making. In their implementation of generative AI technology, enterprises have real concerns about data exposure and ownership of confidential information that may be sent to LLMs.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). And finally, some activities, such as those involved with the latest advances in artificialintelligence (AI), are simply not practically possible, without hardware acceleration.
This process significantly benefits from the MLOps features of SageMaker, which streamline the data science workflow by harnessing the powerful cloud infrastructure of AWS. The following diagram illustrates the inference pipeline. Click here to open the AWS console and follow along.
Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud. Data Processing and Analysis : Techniques for data cleaning, manipulation, and analysis using libraries such as Pandas and Numpy in Python.
Cloud Computing, APIs, and Data Engineering NLP experts don’t go straight into conducting sentiment analysis on their personal laptops. Data Engineering Platforms Spark is still the leader for datapipelines but other platforms are gaining ground. Google Cloud is starting to make a name for itself as well.
Give the features a try and send us feedback either through the AWS forum for Amazon Comprehend or through your usual AWS support contacts. About the Authors Aman Tiwari is a General Solutions Architect working with Worldwide Commercial Sales at AWS.
Instead, businesses tend to rely on advanced tools and strategies—namely artificialintelligence for IT operations (AIOps) and machine learning operations (MLOps)—to turn vast quantities of data into actionable insights that can improve IT decision-making and ultimately, the bottom line.
Solution workflow In this section, we discuss how the different components work together, from data acquisition to spatial modeling and forecasting, serving as the core of the UHI solution. Janosch Woschitz is a Senior Solutions Architect at AWS, specializing in AI/ML. Outside work, he is a travel enthusiast.
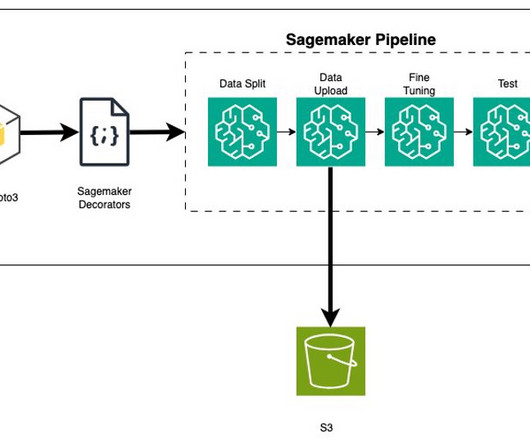
Build and Run DataPipelines with Sagemaker Pipelines by Jake Teo This article shows how to run long-running, repetitive, centrally managed, and traceable datapipelines leveraging AWS’s MLOps platform, Sagemaker, and its underlying services, Sagemaker pipelines, and Studio.
With the emergence of cloud hyperscalers like AWS, Google, and Microsoft, the shift to the cloud has accelerated significantly. Instead of performing major surgery on their critical business systems, enterprises are opting for real-time data integration built around inherently reliable and scalable change data capture (CDC) technology.
Introduction In the rapidly evolving field of ArtificialIntelligence , datasets like the Pile play a pivotal role in training models to understand and generate human-like text. The dataset is openly accessible, making it a go-to resource for researchers and developers in ArtificialIntelligence.
This field is often referred to as explainable artificialintelligence (XAI). Amazon SageMaker Clarify is a feature of Amazon SageMaker that enables data scientists and ML engineers to explain the predictions of their ML models. Solution overview SageMaker algorithms have fixed input and output data formats.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Big Data Processing: Apache Hadoop, Apache Spark, etc.
What if every decision, recommendation, and prediction made by artificialintelligence (AI) was as reliable as your most trusted team members? Next, you’ll see valuable AI use cases and how data integrity powers success. Technology-driven insights and capabilities depend on trusted data.
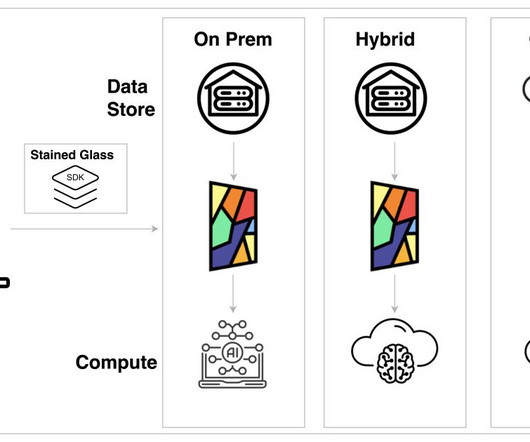
” Das Kamhout, VP and Senior Principal Engineer of the Cloud and Enterprise Solutions Group at Intel Watsonx.data supports our customers’ increasing needs around hybrid cloud deployments and is available on premises and across multiple cloud providers, including IBM Cloud and Amazon Web Services (AWS).
Cloud Services The only two to make multiple lists were Amazon Web Services (AWS) and Microsoft Azure. Most major companies are using one of the two, so excelling in one or the other will help any aspiring data scientist. Saturn Cloud is picking up a lot of momentum lately too thanks to its scalability.
It supports batch and real-time data processing, making it a preferred choice for large enterprises with complex data workflows. Informatica’s AI-powered automation helps streamline datapipelines and improve operational efficiency. AWS Glue AWS Glue is a fully managed ETL service provided by Amazon Web Services.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content