This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The excitement is building for the fourteenth edition of AWS re:Invent, and as always, Las Vegas is set to host this spectacular event. The sessions showcase how Amazon Q can help you streamline coding, testing, and troubleshooting, as well as enable you to make the most of your data to optimize business operations.
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
In a major move to revolutionize AI education, Amazon has launched the AWS AI Ready courses, offering eight free courses in AI and generative AI. This initiative is a direct response to the findings of an AWS study that pointed out a “strong demand” for AI-savvy professionals and the potential for higher salaries in this field.
Amazon SageMaker Data Wrangler provides a visual interface to streamline and accelerate datapreparation for machine learning (ML), which is often the most time-consuming and tedious task in ML projects. About the Authors Charles Laughlin is a Principal AI Specialist at Amazon Web Services (AWS).
Amazon Web Services (AWS) addresses this gap with Amazon SageMaker Canvas , a low-code ML service that simplifies model development and deployment. SageMaker Canvas guides users through the entire ML lifecycle using a point-and-click interface, built-in datapreparation tools, and automated model building capabilities.
Generative artificialintelligence (AI) is transforming the customer experience in industries across the globe. At AWS, our top priority is safeguarding the security and confidentiality of our customers’ workloads. With the AWS Nitro System , we delivered a first-of-its-kind innovation on behalf of our customers.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
It also comes with ready-to-deploy code samples to help you get started quickly with deploying GeoFMs in your own applications on AWS. For a full architecture diagram demonstrating how the flow can be implemented on AWS, see the accompanying GitHub repository. Lets dive in! Solution overview At the core of our solution is a GeoFM.
Yes, the AWS re:Invent season is upon us and as always, the place to be is Las Vegas! are the sessions dedicated to AWS DeepRacer ! Generative AI is at the heart of the AWS Village this year. You marked your calendars, you booked your hotel, and you even purchased the airfare. And last but not least (and always fun!)
It offers an unparalleled suite of tools that cater to every stage of the ML lifecycle, from datapreparation to model deployment and monitoring. You may be prompted to subscribe to this model through AWS Marketplace. On the AWS Marketplace listing , choose Continue to subscribe. Check out the Cohere on AWS GitHub repo.
Datapreparation for LLM fine-tuning Proper datapreparation is key to achieving high-quality results when fine-tuning LLMs for specific purposes. Importance of quality data in fine-tuning Data quality is paramount in the fine-tuning process.
Training an LLM is a compute-intensive and complex process, which is why Fastweb, as a first step in their AI journey, used AWS generative AI and machine learning (ML) services such as Amazon SageMaker HyperPod. The team opted for fine-tuning on AWS.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificialintelligence (AI) to personalize experiences at scale. Additionally, Feast promotes feature reuse, so the time spent on datapreparation is reduced greatly.
This required custom integration efforts, along with complex AWS Identity and Access Management (IAM) policy management, further complicating the model governance process. Several activities are performed in this phase, such as creating the model, datapreparation, model training, evaluation, and model registration.
Purina used artificialintelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The solution focuses on the fundamental principles of developing an AI/ML application workflow of datapreparation, model training, model evaluation, and model monitoring.
Specifically, we cover the computer vision and artificialintelligence (AI) techniques used to combine datasets into a list of prioritized tasks for field teams to investigate and mitigate. Datapreparation SageMaker Ground Truth employs a human workforce made up of Northpower volunteers to annotate a set of 10,000 images.
It does so by covering the end-to-end ML workflow: whether you’re looking for powerful datapreparation and AutoML, managed endpoint deployment, simplified MLOps capabilities, or the ability to configure foundation models for generative AI , SageMaker Canvas can help you achieve your goals. Choose Enable with AWS Organizations.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
Importing data from the SageMaker Data Wrangler flow allows you to interact with a sample of the data before scaling the datapreparation flow to the full dataset. This improves time and performance because you don’t need to work with the entirety of the data during preparation.
Businesses face significant hurdles when preparingdata for artificialintelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage.
In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud. Amazon SageMaker Amazon SageMaker is a fully managed ML service offered by AWS, designed to reduce the time and cost associated with training and tuning ML models at scale.
AWS published Guidance for Optimizing MLOps for Sustainability on AWS to help customers maximize utilization and minimize waste in their ML workloads. The process begins with datapreparation, followed by model training and tuning, and then model deployment and management. This leads to substantial resource consumption.
We use Amazon SageMaker Pipelines , which helps automate the different steps, including datapreparation, fine-tuning, and creating the model. Prerequisites For this walkthrough, complete the following prerequisite steps: Set up an AWS account. Create a SageMaker Studio environment.
You can streamline the process of feature engineering and datapreparation with SageMaker Data Wrangler and finish each stage of the datapreparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface. Choose Create stack.
This post highlights how the UBC CIC uses Amazon Web Services (AWS) to accelerate generative AI development, sharing lessons learned, tools used, and actionable insights you can apply to your projects. Security in generative AI prototyping UBC CIC observes the shared responsibility model through the Amazon Bedrock Data protection features.
Prerequisites To use the model distillation feature, make sure that you have satisfied the following requirements: An active AWS account. Confirm the AWS Regions where the model is available and quotas. Sovik Kumar Nath is an AI/ML and Generative AI Senior Solutions Architect with AWS.
The recently published IDC MarketScape: Asia/Pacific (Excluding Japan) AI Life-Cycle Software Tools and Platforms 2022 Vendor Assessment positions AWS in the Leaders category. AWS met the criteria and was evaluated by IDC along with eight other vendors. AWS is positioned in the Leaders category based on current capabilities.
On December 6 th -8 th 2023, the non-profit organization, Tech to the Rescue , in collaboration with AWS, organized the world’s largest Air Quality Hackathon – aimed at tackling one of the world’s most pressing health and environmental challenges, air pollution. As always, AWS welcomes your feedback.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. An Amazon DataZone domain and an associated Amazon DataZone project configured in your AWS account. Choose Data Wrangler in the navigation pane.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificialintelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API. A copy of your model artifacts is stored in an AWS operated deployment account.
By using the AWS Experience-Based Acceleration (EBA) program, they can enhance efficiency, scalability, and maintainability through close collaboration. To address these challenges and streamline modernization efforts, AWS offers the EBA program.
Artificialintelligence (AI) and machine learning (ML) have seen widespread adoption across enterprise and government organizations. Processing unstructured data has become easier with the advancements in natural language processing (NLP) and user-friendly AI/ML services like Amazon Textract , Amazon Transcribe , and Amazon Comprehend.
Recognizing this challenge as an opportunity for innovation, F1 partnered with Amazon Web Services (AWS) to develop an AI-driven solution using Amazon Bedrock to streamline issue resolution. The objective was to use AWS to replicate and automate the current manual troubleshooting process for two candidate systems.
GenASL is a generative artificialintelligence (AI) -powered solution that translates speech or text into expressive ASL avatar animations, bridging the gap between spoken and written language and sign language. Users can input audio, video, or text into GenASL, which generates an ASL avatar video that interprets the provided data.
In this solution, we fine-tune a variety of models on Hugging Face that were pre-trained on medical data and use the BioBERT model, which was pre-trained on the Pubmed dataset and performs the best out of those tried. We implemented the solution using the AWS Cloud Development Kit (AWS CDK).
Building a production-ready solution in AWS involves a series of trade-offs between resources, time, customer expectation, and business outcome. The AWS Well-Architected Framework helps you understand the benefits and risks of decisions you make while building workloads on AWS.
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
Today, we are happy to announce that with Amazon SageMaker Data Wrangler , you can perform image datapreparation for machine learning (ML) using little to no code. Data Wrangler reduces the time it takes to aggregate and preparedata for ML from weeks to minutes. Choose Import.
Summary: This guide explores ArtificialIntelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deep learning. It equips you to build and deploy intelligent systems confidently and efficiently.
Harnessing the power of big data has become increasingly critical for businesses looking to gain a competitive edge. From deriving insights to powering generative artificialintelligence (AI) -driven applications, the ability to efficiently process and analyze large datasets is a vital capability.
The built-in project templates provided by Amazon SageMaker include integration with some of third-party tools, such as Jenkins for orchestration and GitHub for source control, and several utilize AWS native CI/CD tools such as AWS CodeCommit , AWS CodePipeline , and AWS CodeBuild. all implemented via CloudFormation.
For more information on Mixtral-8x7B Instruct on AWS, refer to Mixtral-8x7B is now available in Amazon SageMaker JumpStart. Before you get started with the solution, create an AWS account. This identity is called the AWS account root user. For more detailed steps to prepare the data, refer to the GitHub repo.
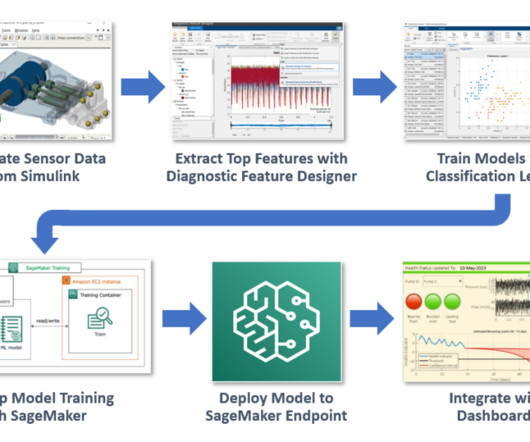
MATLAB is a popular programming tool for a wide range of applications, such as data processing, parallel computing, automation, simulation, machine learning, and artificialintelligence. In recent years, MathWorks has brought many product offerings into the cloud, especially on Amazon Web Services (AWS).
It supports all stages of ML development—from datapreparation to deployment, and allows you to launch a preconfigured JupyterLab IDE for efficient coding within seconds. CodeBuild supports a broad selection of git version control sources like AWS CodeCommit , GitHub, and GitLab.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content