This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
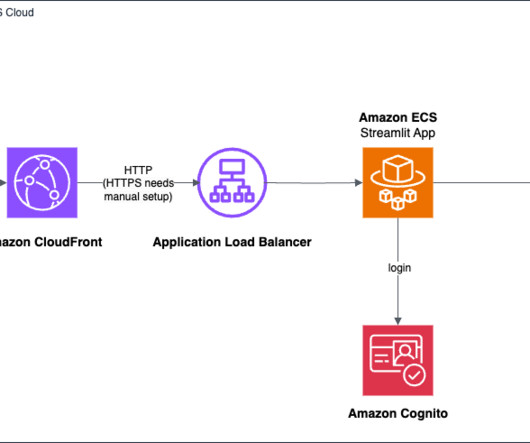
AWS provides a powerful set of tools and services that simplify the process of building and deploying generative AI applications, even for those with limited experience in frontend and backend development. The AWS deployment architecture makes sure the Python application is hosted and accessible from the internet to authenticated users.
To simplify infrastructure setup and accelerate distributed training, AWS introduced Amazon SageMaker HyperPod in late 2023. In this blog post, we showcase how you can perform efficient supervised fine tuning for a Meta Llama 3 model using PEFT on AWS Trainium with SageMaker HyperPod. architectures/5.sagemaker-hyperpod/LifecycleScripts/base-config/
It simplifies the often complex and time-consuming tasks involved in setting up and managing an MLflow environment, allowing ML administrators to quickly establish secure and scalable MLflow environments on AWS. For example, you can give users access permission to download popular packages and customize the development environment.
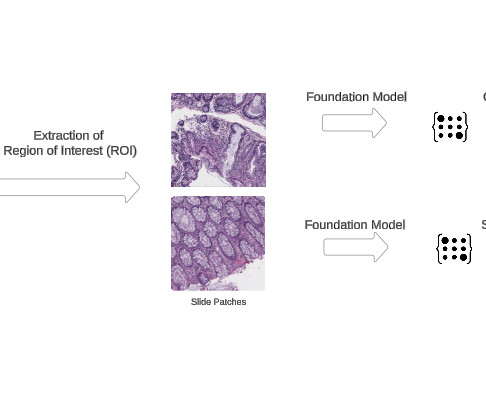
Solution overview Our solution uses the AWS integrated ecosystem to create an efficient scalable pipeline for digital pathology AI workflows. Prerequisites We assume you have access to and are authenticated in an AWS account. The AWS CloudFormation template for this solution uses t3.medium
Earlier this year, we published the first in a series of posts about how AWS is transforming our seller and customer journeys using generative AI. Field Advisor serves four primary use cases: AWS-specific knowledge search With Amazon Q Business, weve made internal data sources as well as public AWS content available in Field Advisors index.
Using vLLM on AWS Trainium and Inferentia makes it possible to host LLMs for high performance inference and scalability. Deploy vLLM on AWS Trainium and Inferentia EC2 instances In these sections, you will be guided through using vLLM on an AWS Inferentia EC2 instance to deploy Meta’s newest Llama 3.2 You will use inf2.xlarge
Prerequisites To perform this solution, complete the following: Create and activate an AWS account. Make sure your AWS credentials are configured correctly. This tutorial assumes you have the necessary AWS Identity and Access Management (IAM) permissions. For this walkthrough, we will use the AWS CLI to trigger the processing.
Hybrid architecture with AWS Local Zones To minimize the impact of network latency on TTFT for users regardless of their locations, a hybrid architecture can be implemented by extending AWS services from commercial Regions to edge locations closer to end users. Next, create a subnet inside each Local Zone. Amazon Linux 2).
In the rapidly evolving landscape of artificialintelligence, open-source large language models (LLMs) are emerging as pivotal tools for democratizing AI technology and fostering innovation. ’s latest and most advanced open-source artificialintelligence model, featuring a staggering 405 billion parameters.
In this post, we explore how to deploy distilled versions of DeepSeek-R1 with Amazon Bedrock Custom Model Import, making them accessible to organizations looking to use state-of-the-art AI capabilities within the secure and scalable AWS infrastructure at an effective cost. You can monitor costs with AWS Cost Explorer.
Amazon Q Business is a fully managed, permission aware generative artificialintelligence (AI)-powered assistant built with enterprise grade security and privacy features. Amazon Q Business uses AWS IAM Identity Center to record the workforce users you assign access to and their attributes, such as group associations.
Prerequisites Make sure you meet the following prerequisites: Make sure your SageMaker AWS Identity and Access Management (IAM) role has the AmazonSageMakerFullAccess permission policy attached. You may be prompted to subscribe to this model through AWS Marketplace. On the AWS Marketplace listing , choose Continue to subscribe.
Today, we’re excited to announce the availability of Meta Llama 3 inference on AWS Trainium and AWS Inferentia based instances in Amazon SageMaker JumpStart. In this post, we demonstrate how easy it is to deploy Llama 3 on AWS Trainium and AWS Inferentia based instances in SageMaker JumpStart.
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificialintelligence (ML/AI) system and reliably improve it over time. First, the AWS Trainium accelerator provides a high-performance, cost-effective, and readily available solution for training and fine-tuning large models.
Solution overview The NER & LLM Gen AI Application is a document processing solution built on AWS that combines NER and LLMs to automate document analysis at scale. Click here to open the AWS console and follow along. The endpoint lifecycle is orchestrated through dedicated AWS Lambda functions that handle creation and deletion.
Amazon Lex is a fully managed artificialintelligence (AI) service with advanced natural language models to design, build, test, and deploy conversational interfaces in applications. Managing your Amazon Lex bots using AWS CloudFormation allows you to create templates defining the bot and all the AWS resources it depends on.
In this post, we walk through how to fine-tune Llama 2 on AWS Trainium , a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.
In this post, we look at how we can use AWS Glue and the AWS Lake Formation ML transform FindMatches to harmonize (deduplicate) customer data coming from different sources to get a complete customer profile to be able to provide better customer experience. Run the AWS Glue ML transform job.
Virginia) AWS Region. Prerequisites To try the Llama 4 models in SageMaker JumpStart, you need the following prerequisites: An AWS account that will contain all your AWS resources. An AWS Identity and Access Management (IAM) role to access SageMaker AI. b64encode(img).decode('utf-8') b64encode(response.content).decode('utf-8')
Large language models (LLMs) are making a significant impact in the realm of artificialintelligence (AI). Llama2 by Meta is an example of an LLM offered by AWS. To learn more about Llama 2 on AWS, refer to Llama 2 foundation models from Meta are now available in Amazon SageMaker JumpStart.
This feature eliminates one of the major bottlenecks in deployment scaling by pre-caching container images, removing the need for time-consuming downloads when adding new instances. Prior to joining AWS, Dr. Li held data science roles in the financial and retail industries. Adriana Simmons is a Senior Product Marketing Manager at AWS.
In this post, we’ll summarize training procedure of GPT NeoX on AWS Trainium , a purpose-built machine learning (ML) accelerator optimized for deep learning training. M tokens/$) trained such models with AWS Trainium without losing any model quality. We’ll outline how we cost-effectively (3.2 billion in Pythia.
Close collaboration with AWS Trainium has also played a major role in making the Arcee platform extremely performant, not only accelerating model training but also reducing overall costs and enforcing compliance and data integrity in the secure AWS environment. Our cluster consisted of 16 nodes, each equipped with a trn1n.32xlarge
Today at AWS re:Invent 2024, we are excited to announce a new feature for Amazon SageMaker inference endpoints: the ability to scale SageMaker inference endpoints to zero instances. This long-awaited capability is a game changer for our customers using the power of AI and machine learning (ML) inference in the cloud.
The world of artificialintelligence (AI) and machine learning (ML) has been witnessing a paradigm shift with the rise of generative AI models that can create human-like text, images, code, and audio. ml.Inf2 instances are powered by the AWS Inferentia2 accelerator , a purpose built accelerator for inference.
To follow along, you can download our test dataset, which includes both publicly available and synthetically generated data, from the following link. The initial step involves creating an AWS Lambda function that will integrate with the Amazon Bedrock agents CreatePortfolio action group. Srinivasan is a Cloud Support Engineer at AWS.
For example, marketing and software as a service (SaaS) companies can personalize artificialintelligence and machine learning (AI/ML) applications using each of their customer’s images, art style, communication style, and documents to create campaigns and artifacts that represent them. For details, refer to Create an AWS account.
Today, we’re excited to announce the availability of Llama 2 inference and fine-tuning support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. In this post, we demonstrate how to deploy and fine-tune Llama 2 on Trainium and AWS Inferentia instances in SageMaker JumpStart.
Each of these products are infused with artificialintelligence (AI) capabilities to deliver exceptional customer experience. During this journey, we collaborated with our AWS technical account manager and the Graviton software engineering teams.
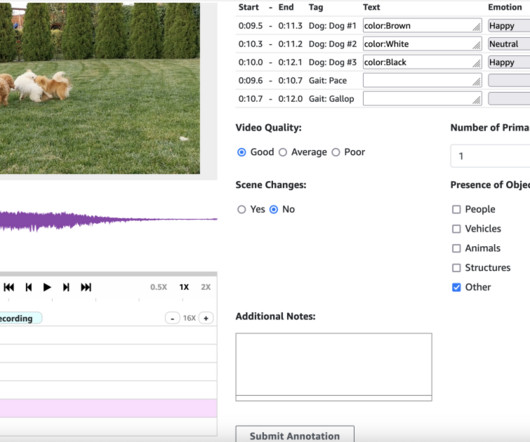
We guide you through deploying the necessary infrastructure using AWS CloudFormation , creating an internal labeling workforce, and setting up your first labeling job. This precision helps models learn the fine details that separate natural from artificial-sounding speech. We demonstrate how to use Wavesurfer.js
Additionally, you can use AWS Lambda directly to expose your models and deploy your ML applications using your preferred open-source framework, which can prove to be more flexible and cost-effective. We also show you how to automate the deployment using the AWS Cloud Development Kit (AWS CDK). Now, let’s set up the environment.
In this blog post and open source project , we show you how you can pre-train a genomics language model, HyenaDNA , using your genomic data in the AWS Cloud. Amazon SageMaker Amazon SageMaker is a fully managed ML service offered by AWS, designed to reduce the time and cost associated with training and tuning ML models at scale.
The number of companies launching generative AI applications on AWS is substantial and building quickly, including adidas, Booking.com, Bridgewater Associates, Clariant, Cox Automotive, GoDaddy, and LexisNexis Legal & Professional, to name just a few. Innovative startups like Perplexity AI are going all in on AWS for generative AI.
While Amazon’s AWS offers cutting-edge infrastructure and services for AI applications, Jassy emphasized the crucial role AI plays across the entire organization. What do they all mean? Oh, are you new to AI, and everything seems too complicated ? Keep reading… AI 101 You can still get on the AI train! Feel free the use them.
PyTorch is a machine learning (ML) framework that is widely used by AWS customers for a variety of applications, such as computer vision, natural language processing, content creation, and more. release, AWS customers can now do same things as they could with PyTorch 1.x 24xlarge with AWS PyTorch 2.0 on AWS PyTorch2.0
Amazon Bedrock is a fully managed service that makes foundation models (FMs) from leading artificialintelligence (AI) startups and Amazon available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. AWS Management Console access to create an AWS Cloud9 instance.
This post shows a way to do this using Snowflake as the data source and by downloading the data directly from Snowflake into a SageMaker Training job instance. We create a custom training container that downloads data directly from the Snowflake table into the training instance rather than first downloading the data into an S3 bucket.
To reduce the barrier to entry of ML at the edge, we wanted to demonstrate an example of deploying a pre-trained model from Amazon SageMaker to AWS Wavelength , all in less than 100 lines of code. In this post, we demonstrate how to deploy a SageMaker model to AWS Wavelength to reduce model inference latency for 5G network-based applications.
With the rise of generative artificialintelligence (AI), an increasing number of organizations use digital assistants to have their end-users ask domain-specific questions, using Retrieval Augmented Generation (RAG) over their enterprise data sources. AWS Amplify to create and deploy the web application. installed Node.js
Following the Cost Optimization pillar of the AWS Well-Architected Framework further led to implementing an AWS Graviton architecture using AWS Lambda and an infrequently accessed Amazon DynamoDB table class. Users can upload documents and download translations for sharing without slow manual intervention.
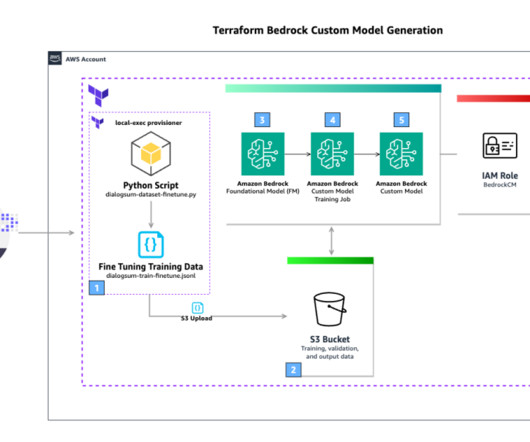
As customers seek to incorporate their corpus of knowledge into their generative artificialintelligence (AI) applications, or to build domain-specific models, their data science teams often want to conduct A/B testing and have repeatable experiments. Download the DialogSum public dataset and convert it to JSONL.
In this post, we show you how Amazon Web Services (AWS) helps in solving forecasting challenges by customizing machine learning (ML) models for forecasting. To download a copy of this dataset, visit. In this post, we access Amazon SageMaker Canvas through the AWS console. This will open the prediction results in a preview page.
Generative artificialintelligence (AI) applications are commonly built using a technique called Retrieval Augmented Generation (RAG) that provides foundation models (FMs) access to additional data they didn’t have during training. Install the AWS Command Line Interface (AWS CLI). Install Docker. Install Terraform.
GenASL is a generative artificialintelligence (AI) -powered solution that translates speech or text into expressive ASL avatar animations, bridging the gap between spoken and written language and sign language. AWS Amplify distributes the GenASL web app consisting of HTML, JavaScript, and CSS to users’ mobile devices.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content