This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
ArtificialIntelligence (AI) is all the rage, and rightly so. Data marts involved the creation of built-for-purpose analytic repositories meant to directly support more specific business users and reporting needs (e.g., Its time to maximize the potential of your artificialintelligence (AI) initiatives.
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Understanding DataLakes A datalake is a centralized repository that stores structured, semi-structured, and unstructured data in its raw format.
Data Swamp vs DataLake. When you imagine a lake, it’s likely an idyllic image of a tree-ringed body of reflective water amid singing birds and dabbling ducks. I’ll take the lake, thank you very much. But when it’s dirty, stagnant, or hard to unleash, your business will suffer. Benefits of a DataLake.
In today’s digital world, data is king. Organizations that can capture, store, format, and analyze data and apply the businessintelligence gained through that analysis to their products or services can enjoy significant competitive advantages. But, the amount of data companies must manage is growing at a staggering rate.
Real-Time ML with Spark and SBERT, AI Coding Assistants, DataLake Vendors, and ODSC East Highlights Getting Up to Speed on Real-Time Machine Learning with Spark and SBERT Learn more about real-time machine learning by using this approach that uses Apache Spark and SBERT. Well, these libraries will give you a solid start.
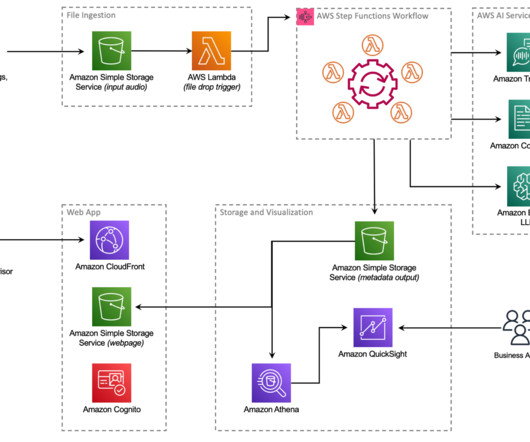
As one of the largest AWS customers, Twilio engages with data, artificialintelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
Datenqualität hingegen, wurde zum wichtigen Faktor jeder Unternehmensbewertung, was Themen wie Reporting, Data Governance und schließlich dann das Data Engineering mehr noch anschob als die Data Science. Google Trends – Big Data (blue), Data Science (red), BusinessIntelligence (yellow) und Process Mining (green).
Übrigens nicht mehr so stark bei den Data Scientists, auch wenn richtig gute Mitarbeiter ebenfalls rar gesät sind, den größten Bedarf haben Unternehmen eher bei den Data Engineers. Das sind die Kollegen, die die Data Warehouses oder DataLakes aufbauen und pflegen. appeared first on Data Science Blog.
Metabase GitHub | Website Metabase is an easy-to-use data exploration tool that allows even non-technical users to ask questions and gain insights. This businessintelligence and user experience tool allows you to build interactive dashboards, models for cleaning tables, and set up alerts to notify users when your data changes.
Data platform architecture has an interesting history. Towards the turn of millennium, enterprises started to realize that the reporting and businessintelligence workload required a new solution rather than the transactional applications. A read-optimized platform that can integrate data from multiple applications emerged.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machine learning models and develop artificialintelligence (AI) applications.
Artificialintelligence (AI) adoption is still in its early stages. As more businesses use AI systems and the technology continues to mature and change, improper use could expose a company to significant financial, operational, regulatory and reputational risks. Trustworthiness is critical.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
Online analytical processing (OLAP) database systems and artificialintelligence (AI) complement each other and can help enhance data analysis and decision-making when used in tandem. IBM watsonx.data is the next generation OLAP system that can help you make the most of your data.
To optimize data analytics and AI workloads, organizations need a data store built on an open data lakehouse architecture. This type of architecture combines the performance and usability of a data warehouse with the flexibility and scalability of a datalake.
This includes integration with your data warehouse engines, which now must balance real-time data processing and decision-making with cost-effective object storage, open source technologies and a shared metadata layer to share data seamlessly with your data lakehouse.
In a prior blog , we pointed out that warehouses, known for high-performance data processing for businessintelligence, can quickly become expensive for new data and evolving workloads. Chat with a data management expert The post Why optimize your warehouse with a data lakehouse strategy appeared first on IBM Blog.
Think of it as building plumbing for data to flow smoothly throughout the organization. EVENT — ODSC East 2024 In-Person and Virtual Conference April 23rd to 25th, 2024 Join us for a deep dive into the latest data science and AI trends, tools, and techniques, from LLMs to data analytics and from machine learning to responsible AI.
Amazon Bedrock , a fully managed service designed to facilitate the integration of LLMs into enterprise applications, offers a choice of high-performing LLMs from leading artificialintelligence (AI) companies like Anthropic, Mistral AI, Meta, and Amazon through a single API. The Step Functions workflow starts.
Businesses face significant hurdles when preparing data for artificialintelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage.
After a few minutes, a transcript is produced with Amazon Transcribe Call Analytics and saved to another S3 bucket for processing by other businessintelligence (BI) tools. PCA’s security features ensure that any PII data was redacted from the transcript, as well as from the audio file itself.
Inconsistent or unstructured data can lead to faulty insights, so transformation helps standardise data, ensuring it aligns with the requirements of Analytics, Machine Learning , or BusinessIntelligence tools. This makes drawing actionable insights, spotting patterns, and making data-driven decisions easier.
Watsonx.data is built on 3 core integrated components: multiple query engines, a catalog that keeps track of metadata, and storage and relational data sources which the query engines directly access. AMC Networks is excited by the opportunity to capitalize on the value of all of their data to improve viewer experiences.
Then we have some other ETL processes to constantly land the past 5 years of data into the Datamarts. As we learned in the previous section, a Dataflow is a self-service ETL and data preparation layer connecting to various data sources, transforming the data and storing the results in CSV format in Azure DataLake Gen 2 ( ADLS Gen2 ).
Dimensional Data Modeling in the Modern Era by Dustin Dorsey Slides Dustin Dorsey’s AI slides explored the evolution of dimensional data modeling, a staple in data warehousing and businessintelligence.
Social media conversations, comments, customer reviews, and image data are unstructured in nature and hold valuable insights, many of which are still being uncovered through advanced techniques like Natural Language Processing (NLP) and machine learning. Many find themselves swamped by the volume and complexity of unstructured data.
Having been in business for over 50 years, ARC had accumulated a massive amount of data that was stored in siloed, on-premises servers across its 7 business domains. Using Alation, ARC automated the data curation and cataloging process. “So
ETL (Extract, Transform, Load) This is a core data engineering process for moving data from one or more sources to a destination, typically a data warehouse or datalake. The reason this is an important skill is that ETL is a critical process for data warehousing and businessintelligence.
Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP. Additionally, Amazon Simple Storage Service (Amazon S3) served as the central datalake, providing a scalable and cost-effective storage solution for the diverse data types collected from different systems.
Summary: Power BI is a businessintelligence tool that transforms raw data into actionable insights. Introduction Managing business and its key verticals can be challenging. However, with the surge of data tools like Power BI, you can not only manage the data, but at the same time draw actionable insights from it.
Other users Some other users you may encounter include: Data engineers , if the data platform is not particularly separate from the ML platform. Analytics engineers and data analysts , if you need to integrate third-party businessintelligence tools and the data platform, is not separate.
It’s distributed both in the cloud and on-premises, allowing extensive use and movement across clouds, apps and networks, as well as stores of data at rest. An architecture designed for data democratization aims to be flexible, integrated, agile and secure to enable the use of data and artificialintelligence (AI) at scale.
Many companies are making a business out of helping enterprises get data out of old systems, and tools like Apache Airflow are helping streamline these processes. But even if data is no longer stuck in mainframes, it’s still fragmented across systems like cloud SaaS services or datalakes.
Create businessintelligence (BI) dashboards for visual representation and analysis of event data. Figure: AI chatbot workflow Archiving and reporting layer The archiving and reporting layer handles streaming, storing, and extracting, transforming, and loading (ETL) operational event data.
Tags can be added at an Amazon DataZone domain and used for organizing data assets, users, and projects. Usage of data is tracked through the data consumers, such as Amazon Athena , Amazon Redshift , or Amazon SageMaker. You can define metadata tags and assign them to resources like databases and tables.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content