This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Python is a versatile and powerful programming language that plays a central role in the toolkit of data scientists and analysts. Its simplicity and readability make it a preferred choice for working with data, from the most fundamental tasks to cutting-edge artificialintelligence and machine learning.
LangChain agents are a type of artificialintelligence that can be used to build AI applications. They are based on large language models (LLMs), which are a type of artificialintelligence that can generate and understand human language. Key learning outcomes: What are embeddings and how do they work?
Introduction Natural Language Processing (NLP) is a field of ArtificialIntelligence that deals with the interaction between computers and human language. NLP aims to enable computers to understand, interpret and generate human language naturally and helpfully.
Introduction Are you struggling to decide between data-driven practices and AI-driven strategies for your business? Besides, there is a balance between the precision of traditional data analysis and the innovative potential of explainable artificialintelligence. These changes assure faster deliveries and lower costs.
Savvy data scientists are already applying artificialintelligence and machine learning to accelerate the scope and scale of data-driven decisions in strategic organizations. Data Scientists of Varying Skillsets Learn AI – ML Through Technical Blogs. See DataRobot in Action. Watch a demo.
Its cloud-native architecture, combined with robust data-sharing capabilities, allows businesses to easily leverage cutting-edge tools from partners like Dataiku, fostering innovation and driving more insightful, data-driven outcomes.
ArtificialIntelligence (AI) is revolutionizing various industries, and IT support is no exception. The Role of Data Scientists in AI-Supported IT Data scientists play a crucial role in the successful integration of AI in IT support: 1.
Janitor AI API stands as a beacon in the dynamic world of artificialintelligence, effectively revolutionizing communication across myriad sectors. Janitor AI exemplifies the strides made in the field of artificialintelligence. These functionalities significantly improve the management and analysis of data.
Every data professional learning Python would come across Pandas during their work. PandasAI would use the LLM power to help us explore and cleandata. It would be conversational tools that we can use to ask Pandas to manipulate data in a way we want.
Artificialintelligence (AI) adoption is here. In fact, the use of artificialintelligence in business is developing beyond small, use-case specific applications into a paradigm that places AI at the strategic core of business operations.
The rapid pace of technological change has made data-driven initiatives more crucial than ever within modern business strategies. But as we move into 2025, organizations are facing new challenges that are testing their data strategies, artificialintelligence (AI) readiness, and overall trust in data.
The job opportunities for data scientists will grow by 36% between 2021 and 2031, as suggested by BLS. It has become one of the most demanding job profiles of the current era.
Introduction Data annotation plays a crucial role in the field of machine learning, enabling the development of accurate and reliable models. In this article, we will explore the various aspects of data annotation, including its importance, types, tools, and techniques.
The rise of machine learning and the use of ArtificialIntelligence gradually increases the requirement of data processing. That’s because the machine learning projects go through and process a lot of data, and that data should come in the specified format to make it easier for the AI to catch and process.
Introduction Effective data management is crucial for organizations of all sizes and in all industries because it helps ensure the accuracy, security, and accessibility of data, which is essential for making good decisions and operating efficiently.
Generative AI for databases will transform how you deal with databases, whether or not you’re a data scientist, […] The post 10 Ways to Use Generative AI for Database appeared first on Analytics Vidhya. Though it appears to dazzle, its true value lies in refreshing the fundamental roots of applications.
The rapid pace of technological change has made data-driven initiatives more crucial than ever within modern business strategies. But as we move into 2025, organizations are facing new challenges that are testing their data strategies, artificialintelligence (AI) readiness, and overall trust in data.
A data fabric is an emerging data management design that allows companies to seamlessly access, integrate, model, analyze, and provision data. Instead of centralizing data stores, data fabrics establish a federated environment and use artificialintelligence and metadata automation to intelligently secure data management. .
A data fabric is an emerging data management design that allows companies to seamlessly access, integrate, model, analyze, and provision data. Instead of centralizing data stores, data fabrics establish a federated environment and use artificialintelligence and metadata automation to intelligently secure data management. .
This process is entirely automated, and when the same XGBoost model was re-trained on the cleaneddata, it achieved 83% accuracy (with zero change to the modeling code).
This method requires the enterprise to have cleandata flows from central sources of truth to accurately track and reflect usage. Watsonx.data allows enterprises to centrally gather, categorize and filter data from multiple sources. With usage-based pricing of products, SMBs pay for only what they use.
At the heart of the matter lies the query, “What does a data scientist do?” ” The answer: they craft predictive models that illuminate the future ( Image credit ) Data collection and cleaning : Data scientists kick off their journey by embarking on a digital excavation, unearthing raw data from the digital landscape.
Let’s see how good and bad it can be (image created by the author with Midjourney) A big part of most data-related jobs is cleaning the data. There is usually no standard way of cleaningdata, as it can come in numerous different ways.
Overall business benefits of powering your AI/ML initiatives with data enrichment include reduced costs, increased trust, and faster, more confident decision-making. Businesses across industries are increasingly relying on artificialintelligence (AI) and machine learning (ML) to gain insights, optimize operations, and drive growth.
Introduction ArtificialIntelligence (AI) is revolutionising various sectors , and Acquisition is no exception. Key Applications of AI in Procurement ArtificialIntelligence (AI) is transforming procurement processes by automating tasks, enhancing decision-making, and providing valuable insights.
High-integrity data avoids the introduction of noise, resulting in more robust models. By building models around data with integrity, less rework is required because of unexpected issues. Cleandata reduces the need for data prep. Easier model maintenance. Reduce preprocessing overhead. Reliable model deployment.
The MLOps process can be broken down into four main stages: Data Preparation: This involves collecting and cleaningdata to ensure it is ready for analysis. The data must be checked for errors and inconsistencies and transformed into a format suitable for use in machine learning algorithms.
Marc van Oudheusden is a Senior Data Scientist with the Amazon ML Solutions Lab team at Amazon Web Services. He works with AWS customers to solve business problems with artificialintelligence and machine learning. Outside of work you may find him at the beach, playing with his children, surfing or kitesurfing.
This is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading artificialintelligence (AI) companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API. Since then, Amazon Web Services (AWS) has introduced new services such as Amazon Bedrock.
Data scrubbing is the knight in shining armour for BI. Ensuring cleandata empowers BI tools to generate accurate reports and insights that drive strategic decision-making. Imagine the difference between a blurry picture and a high-resolution image – that’s the power of cleandata in BI.
Generative artificialintelligence ( generative AI ) models have demonstrated impressive capabilities in generating high-quality text, images, and other content. However, these models require massive amounts of clean, structured training data to reach their full potential. read HTML).
From speech recognition breakthroughs to large-scale language models, the story of AI is fundamentally a story of data. The Scaling Hypothesis: Bigger Data, Better AI? Ill say it again the story of artificialintelligence over the past decade is fundamentally a story about data.
Conversational artificialintelligence (AI) leads the charge in breaking down barriers between businesses and their audiences. Cleandata is fundamental for training your AI. The quality of data fed into your AI system directly impacts its learning and accuracy.
With the explosion of big data and advancements in computing power, organizations can now collect, store, and analyze massive amounts of data to gain valuable insights. Machine learning, a subset of artificialintelligence , enables systems to learn and improve from data without being explicitly programmed.
About one-half of Ventana Research participants want to schedule data processes to run automatically & two-thirds seek to eliminate manual processes when working with data. Sheer volume of data makes automation with ArtificialIntelligence & Machine Learning (AI & ML) an imperative.
However, despite being a lucrative career option, Data Scientists face several challenges occasionally. The following blog will discuss the familiar Data Science challenges professionals face daily. Conclusion Thus, the above blog has provided you with the everyday challenges in Data Science.
During training, the input data is intentionally corrupted by adding noise, while the target remains the original, uncorrupted data. The autoencoder learns to reconstruct the cleandata from the noisy input, making it useful for image denoising and data preprocessing tasks. And that’s exactly what I do.
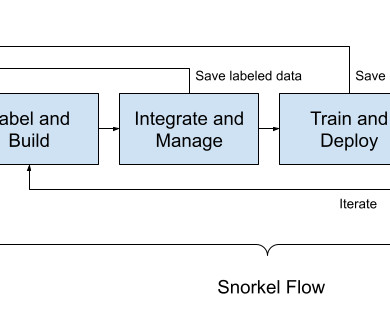
I’ll also introduce Snorkel Flow, a platform for data-centric AI, and show how to use it in conjunction with MinIO to create a training pipeline that is performant and can scale to any AI workload required. Before defining data-centric AI, let’s start off with a quick review of exactly how model-centric AI works.
I’ll also introduce Snorkel Flow, a platform for data-centric AI, and show how to use it in conjunction with MinIO to create a training pipeline that is performant and can scale to any AI workload required. Before defining data-centric AI, let’s start off with a quick review of exactly how model-centric AI works.
Natural Language Processing (NLP) is a branch of ArtificialIntelligence (AI) that helps computers understand, interpret and manipulate human language. In particular I know that how we collect, manage, and cleandata to be consumed by these systems can greatly impact the overall success of these systems.
Moreover, learning it at a young age can give kids a head start in acquiring the knowledge and skills needed for future career opportunities in Data Analysis, Machine Learning, and ArtificialIntelligence. These skills are essential for preparing data for modeling.
However, the mere accumulation of data is not enough; ensuring data quality is paramount. The Significance of Data Quality Before we dive into the realm of AI and ML, it’s crucial to understand why data quality holds such immense importance. As data evolves, these technologies adapt to maintain high standards.
Extensive libraries for data manipulation, visualization, and statistical analysis. Widely used in Machine Learning and ArtificialIntelligence, expanding its applications beyond Data Analysis. Additionally, having coding skills opens up avenues for career growth and the ability to tackle complex data challenges.
But to do that, you’ve got to leverage tools that actually have artificialintelligence baked in. Profiling data. In Excel, you’ll need to create nested formulas for even simple logic to clean your data. Paxata takes care of the heavy lifting involved in cleaningdata in two ways. The hard way.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





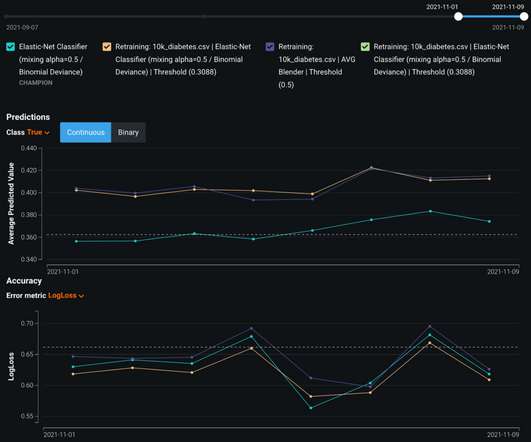











































Let's personalize your content