This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
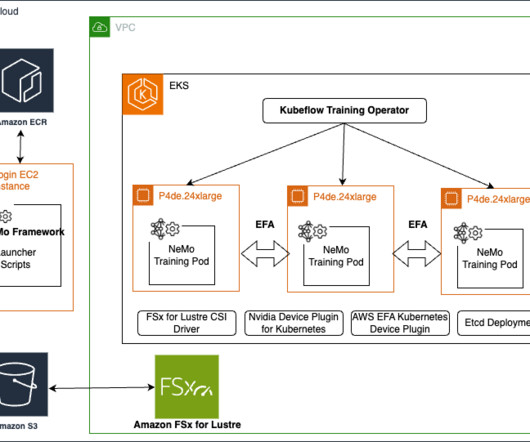
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
Summary: This guide explores ArtificialIntelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deep learning. It equips you to build and deploy intelligent systems confidently and efficiently.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? By leveraging anomaly detection, we can uncover hidden irregularities in transaction data that may indicate fraudulent behavior.
Harnessing the power of big data has become increasingly critical for businesses looking to gain a competitive edge. From deriving insights to powering generative artificialintelligence (AI) -driven applications, the ability to efficiently process and analyze large datasets is a vital capability.
These methods can help businesses to make sense of their data and to identify trends and patterns that would otherwise be invisible. In recent years, there has been a growing interest in the use of artificialintelligence (AI) for data analysis.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machine learning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction. compute.internal.
Use case and model lifecycle governance overview In the context of regulations such as the European Union’s ArtificialIntelligence Act (EU AI Act), a use case refers to a specific application or scenario where AI is used to achieve a particular goal or solve a problem. In both cases, you can track your experiments using MLflow.
The process begins with datapreparation, followed by model training and tuning, and then model deployment and management. Datapreparation is essential for model training and is also the first phase in the MLOps lifecycle. Unlike persistent endpoints, clusters are decommissioned when a batch transform job is complete.
In the rapidly expanding field of artificialintelligence (AI), machine learning tools play an instrumental role. Scikit Learn Scikit Learn is a comprehensive machine learning tool designed for data mining and large-scale unstructured data analysis.
This helps with datapreparation and feature engineering tasks and model training and deployment automation. Moreover, they require a pre-determined number of topics, which was hard to determine in our data set. The approach uses three sequential BERTopic models to generate the final clustering in a hierarchical method.
This session covers the technical process, from datapreparation to model customization techniques, training strategies, deployment considerations, and post-customization evaluation. Explore how this powerful tool streamlines the entire ML lifecycle, from datapreparation to model deployment.
Competition at the leading edge of LLMs is certainly heating up, and it is only getting easier to train LLMs now that large H100 clusters are available at many companies, open datasets are released, and many techniques, best practices, and frameworks have been discovered and released.
Introduction Data Science and ArtificialIntelligence (AI) are at the forefront of technological innovation, fundamentally transforming industries and everyday life. Enhanced data visualisation aids in better communication of insights. Domain knowledge is crucial for effective data application in industries.
Fine tuning embedding models using SageMaker SageMaker is a fully managed machine learning service that simplifies the entire machine learning workflow, from datapreparation and model training to deployment and monitoring. For more information about fine tuning Sentence Transformer, see Sentence Transformer training overview.
This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process. One aspect of this datapreparation is feature engineering. This can cause limitations if you need to consider more metrics than this.
In the first part of our Anomaly Detection 101 series, we learned the fundamentals of Anomaly Detection and saw how spectral clustering can be used for credit card fraud detection. This method helps in identifying fraudulent transactions by grouping similar data points and detecting outliers. detection of potential failures or issues).
Here, we use the term foundation model to describe an artificialintelligence (AI) capability that has been pre-trained on a large and diverse body of data. 0, 1, 2 Reference architecture In this post, we use Amazon SageMaker Data Wrangler to ask a uniform set of visual questions for thousands of photos in the dataset.
One of the key drivers of Philips’ innovation strategy is artificialintelligence (AI), which enables the creation of smart and personalized products and services that can improve health outcomes, enhance customer experience, and optimize operational efficiency.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). And finally, some activities, such as those involved with the latest advances in artificialintelligence (AI), are simply not practically possible, without hardware acceleration.
Here are the steps involved in predictive analytics: Collect Data : Gather information from various sources like customer behavior, sales, or market trends. Clean and Organise Data : Prepare the data by removing errors and making it ready for analysis. Test the Model : Ensure that the model is accurate and works well.
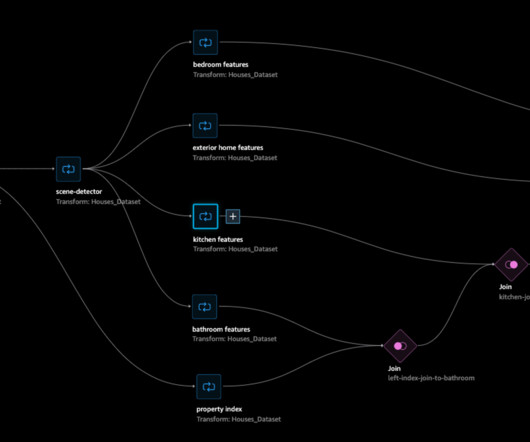
Feature engineering We perform two sets of feature engineering processes to extract valuable information from the raw data and feed it into the corresponding towers in the model: standard feature engineering and fine-tuned SBERT embeddings. Standard feature engineering Our datapreparation process begins with standard feature engineering.
Datapreparation and loading into sequence store The initial step in our machine learning workflow focuses on preparing the data. e-]*)"} ] Finally, define a Pytorch estimator and submit a training job that refers to the data location obtained from the HealthOmics sequence store.
It is a central hub for researchers, data scientists, and Machine Learning practitioners to access real-world data crucial for building, testing, and refining Machine Learning models. The publicly available repository offers datasets for various tasks, including classification, regression, clustering, and more.
Table of Contents Introduction to PyCaret Benefits of PyCaret Installation and Setup DataPreparation Model Training and Selection Hyperparameter Tuning Model Evaluation and Analysis Model Deployment and MLOps Working with Time Series Data Conclusion 1. or higher and a stable internet connection for the installation process.
SageMaker pipeline steps The pipeline is divided into the following steps: Train and test datapreparation – Terabytes of raw data are copied to an S3 bucket, processed using AWS Glue jobs for Spark processing, resulting in data structured and formatted for compatibility.
5 Industries Using Synthetic Data in Practice Here’s an overview of what synthetic data is and a few examples of how various industries have benefited from it. Hands-on Data-Centric AI: DataPreparation Tuning — Why and How? Here’s how.
With the help of web scraping, you can make your own data set to work on. Machine Learning Machine learning is a type of artificialintelligence that allows software applications to learn from the data and become more accurate over time.
Key steps involve problem definition, datapreparation, and algorithm selection. Data quality significantly impacts model performance. UnSupervised Learning Unlike Supervised Learning, unSupervised Learning works with unlabeled data. The algorithm tries to find hidden patterns or groupings in the data.
The primary components of Deep Learning Algorithms are artificial neural networks (ANNs), which are inspired by the structure and function of the human brain. Let’s dive into the working of deep learning algorithms: DataPreparation: Deep Learning algorithms require a large amount of labeled data for training.
For Secret type , choose Credentials for Amazon Redshift cluster. Enter the credentials used to log in to access Amazon Redshift as a data source. Choose the Redshift cluster associated with the secrets. He is focused on building interactive ML solutions which simplify data processing and datapreparation journeys.
We also examined the results to gain a deeper understanding of why these prompt engineering skills and platforms are in demand for the role of Prompt Engineer, not to mention machine learning and data science roles. Kubernetes: A long-established tool for containerized apps.
[link] Ahmad Khan, head of artificialintelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. PA : Got it.
[link] Ahmad Khan, head of artificialintelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. PA : Got it.
In today’s rapidly evolving landscape of artificialintelligence (AI), training large language models (LLMs) poses significant challenges. These models often require enormous computational resources and sophisticated infrastructure to handle the vast amounts of data and complex algorithms involved.
You need data engineering expertise and time to develop the proper scripts and pipelines to wrangle, clean, and transform data. Afterward, you need to manage complex clusters to process and train your ML models over these large-scale datasets. These features can find temporal patterns in the data that can influence the baseFare.
In the modern digital era, this particular area has evolved to give rise to a discipline known as Data Science. Data Science offers a comprehensive and systematic approach to extracting actionable insights from complex and unstructured data.
Nobody else offers this same combination of choice of the best ML chips, super-fast networking, virtualization, and hyper-scale clusters. This typically involves a lot of manual work cleaning data, removing duplicates, enriching and transforming it.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificialintelligence (AI) to personalize experiences at scale. Additionally, Feast promotes feature reuse, so the time spent on datapreparation is reduced greatly.
Introduction Large Language Models (LLMs) represent the cutting-edge of artificialintelligence, driving advancements in everything from natural language processing to autonomous agentic systems. While the use of pre-trained models is free, fine-tuning them for specific tasks can lead to costs related to computing and data handling.
Their application spans a wide array of tasks, from categorizing information to predicting future trends, making them an essential component of modern artificialintelligence. Machine learning algorithms are specialized computational models designed to analyze data, recognize patterns, and make informed predictions or decisions.
Over sampling and under sampling are pivotal strategies in the realm of data analysis, particularly when tackling the challenge of imbalanced data classes. It can help streamline analysis by focusing on the most relevant data.
This strategic decision was driven by several factors: Efficient datapreparation Building a high-quality pre-training dataset is a complex task, involving assembling and preprocessing text data from various sources, including web sources and partner companies. The team opted for fine-tuning on AWS.
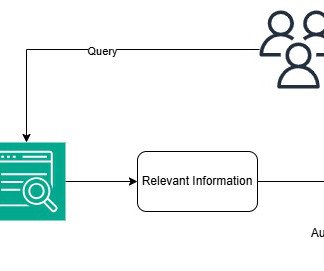
RAG retrieves data from a preexisting knowledge base (your data), combines it with the LLMs knowledge, and generates responses with more human-like language. However, in order for generative AI to understand your data, some amount of datapreparation is required, which involves a big learning curve.
It groups similar data points or identifies outliers without prior guidance. Type of Data Used in Each Approach Supervised learning depends on data that has been organized and labeled. This datapreparation process ensures that every example in the dataset has an input and a known output.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content