This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The process of setting up and configuring a distributed training environment can be complex, requiring expertise in server management, cluster configuration, networking and distributed computing. Scheduler : SLURM is used as the job scheduler for the cluster. You can also customize your distributed training.
The compute clusters used in these scenarios are composed of more than thousands of AI accelerators such as GPUs or AWS Trainium and AWS Inferentia , custom machine learning (ML) chips designed by Amazon Web Services (AWS) to accelerate deep learning workloads in the cloud.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? Spectral clustering, a technique rooted in graph theory, offers a unique way to detect anomalies by transforming data into a graph and analyzing its spectral properties.
Building foundation models (FMs) requires building, maintaining, and optimizing large clusters to train models with tens to hundreds of billions of parameters on vast amounts of data. SageMaker HyperPod integrates the Slurm Workload Manager for cluster and training job orchestration.
Modern model pre-training often calls for larger cluster deployment to reduce time and cost. As part of a single cluster run, you can spin up a cluster of Trn1 instances with Trainium accelerators. Trn1 UltraClusters can host up to 30,000 Trainium devices and deliver up to 6 exaflops of compute in a single cluster.
Large language models (LLMs) are making a significant impact in the realm of artificialintelligence (AI). In high performance computing (HPC) clusters, such as those used for deep learning model training, hardware resiliency issues can be a potential obstacle. Llama2 by Meta is an example of an LLM offered by AWS.
By distributing experts across workers, expert parallelism addresses the high memory requirements of loading all experts on a single device and enables MoE training on a larger cluster. The following figure offers a simplified look at how expert parallelism works on a multi-GPU cluster.
Asian technology stocks fell sharply Monday as Chinese AI startup DeepSeek sparked sector-wide concerns about artificialintelligence investment sustainability and pricing pressures, triggering selloffs in chip-related shares while boosting some Chinese tech giants. and Advantest plunging 8.8%. ” The comments follow U.S.
Each of these products are infused with artificialintelligence (AI) capabilities to deliver exceptional customer experience. So far, we have migrated PyTorch and TensorFlow based Distil RoBerta-base, spaCy clustering, prophet, and xlmr models to Graviton3-based c7g instances.
Download the free, unabridged version here. They bring deep expertise in machine learning , clustering , natural language processing , time series modelling , optimisation , hypothesis testing and deep learning to the team. Download the free, unabridged version here. Team How to determine the optimal team structure ?
Our high-level training procedure is as follows: for our training environment, we use a multi-instance cluster managed by the SLURM system for distributed training and scheduling under the NeMo framework. First, download the Llama 2 model and training datasets and preprocess them using the Llama 2 tokenizer. Youngsuk Park is a Sr.
Continual pre-training techniques like the ones described in this post require access to high-performance compute instances, which has become more difficult to get as more developers are using generative artificialintelligence (AI) and LLMs for their applications. Our cluster consisted of 16 nodes, each equipped with a trn1n.32xlarge
For AWS and Outerbounds customers, the goal is to build a differentiated machine learning and artificialintelligence (ML/AI) system and reliably improve it over time. You can use artifacts to manage configuration, so everything from hyperparameters to cluster sizing can be managed in a single file, tracked alongside the results.
Those researches are often conducted on easily available benchmark datasets which you can easily download, often with corresponding ground truth data (label data) necessary for training. In this case, original data distribution have two clusters of circles and triangles and a clear border can be drawn between them.
Solution overview BGE stands for Beijing Academy of ArtificialIntelligence (BAAI) General Embeddings. The process involves the following steps: Download the training and validation data, which consists of PDFs from Uber and Lyft 10K documents. The BGE models come in three sizes: bge-large-en-v1.5:
Afterward, you need to manage complex clusters to process and train your ML models over these large-scale datasets. Download the dataset from Kaggle and upload it to an Amazon Simple Storage Service (Amazon S3) bucket. Then you must experiment with numerous models and hyperparameters requiring domain expertise.
Walkthrough Download the pre-tokenized Wikipedia dataset as shown: export DATA_DIR=~/examples_datasets/gpt2 mkdir -p ${DATA_DIR} && cd ${DATA_DIR} wget [link] wget [link] aws s3 cp s3://neuron-s3/training_datasets/gpt/wikipedia/my-gpt2_text_document.bin. Each trn1.32xl has 16 accelerators with two workers per accelerator.
In the first part of our Anomaly Detection 101 series, we learned the fundamentals of Anomaly Detection and saw how spectral clustering can be used for credit card fraud detection. To download our dataset and set up our environment, we will install the following packages. And that’s exactly what I do.
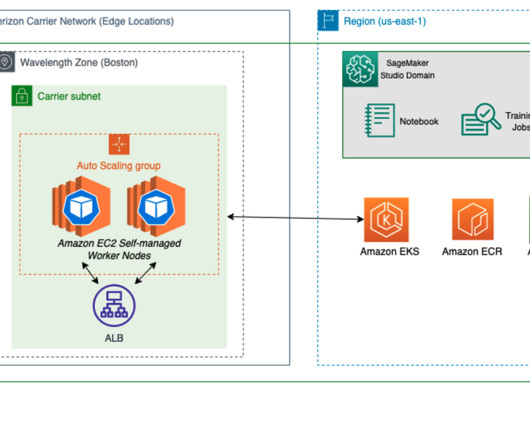
To learn more about deploying geo-distributed applications on AWS Wavelength, refer to Deploy geo-distributed Amazon EKS clusters on AWS Wavelength. Create AWS Wavelength infrastructure Before we convert the local SageMaker model inference endpoint to a Kubernetes deployment, you can create an EKS cluster in a Wavelength Zone.
The model weights are available to download, inspect and deploy anywhere. SageMaker Training provisions compute clusters with user-defined hardware configuration and code. TII used transient clusters provided by the SageMaker Training API to train the Falcon LLM, up to 48 ml.p4d.24xlarge
In the rapidly expanding field of artificialintelligence (AI), machine learning tools play an instrumental role. With an impressive collection of efficient tools and a user-friendly interface, it is ideal for tackling complex classification, regression, and cluster-based problems.
The Hugging Face transformers , tokenizers , and datasets libraries provide APIs and tools to download and predict using pre-trained models in multiple languages. When scaling up your training job to a large GPU cluster, you can reduce the per-GPU memory footprint of the model by sharding the training state over multiple GPUs.
Download the template or quick launch the CloudFormation stack by choosing Launch Stack : Deploy a CloudFormation template into an existing VPC – This option creates the required VPC endpoints, IAM execution roles, and SageMaker domain in an existing VPC with private subnets. It then deploys Amazon DocumentDB into this new VPC.
For Secret type , choose Credentials for Amazon Redshift cluster. Choose the Redshift cluster associated with the secrets. Today, generative artificialintelligence (AI) can enable you to write complex SQL queries without requiring in-depth SQL experience. Enter a name for the secret, such as sm-sql-redshift-secret.
They have been trained using two newly unveiled custom-built 24K GPU clusters on more than 15 trillion tokens of data. Additionally, Ollama incorporates a type of package manager, which simplifies the process of downloading and utilizing LLMs through a single command, enhancing both speed and ease of use.
A basic, production-ready cluster priced out to the low-six-figures. A company then needed to train up their ops team to manage the cluster, and their analysts to express their ideas in MapReduce. Plus there was all of the infrastructure to push data into the cluster in the first place. Goodbye, Hadoop. And it was good.
A cluster consists of multiple nodes. Cluster : A collection of nodes working together. Each cluster has a unique name and can scale by adding more nodes. Scalability Built on a distributed architecture, Search engine allows you to scale horizontally by adding more nodes to your cluster.
Inside the managed training job in the SageMaker environment, the training job first downloads the mouse genome using the S3 URI supplied by HealthOmics. In the sample Jupyter notebook we show how to download FASTA files from GenBank, convert them into FASTQ files, and then load them into a HealthOmics sequence store.
Orchestration Tools: Kubernetes, Docker Swarm Purpose: Manages the deployment, scaling, and operation of application containers across clusters of hosts. My mission is to change education and how complex ArtificialIntelligence topics are taught. Download the code! And that’s exactly what I do. Sharma, eds.,
McLarney, Digital Transformation Lead for ArtificialIntelligence and Machine Learning, NASA Background ¶ Information overload is real. or GPT-4 arXiv, OpenAlex, CrossRef, NTRS lgarma Topic clustering and visualization, paper recommendation, saved research collections, keyword extraction GPT-3.5 bge-small-en-v1.5
Customers will be responsible for deleting the input data sources created by them, such as Amazon Simple Storage Service (Amazon S3) buckets, Amazon Redshift clusters, and so on. Anomalies data for each measure can be downloaded for a detector by using the Amazon Lookout for Metrics APIs for a particular detector. Choose Delete.
Users can download datasets in formats like CSV and ARFF. The publicly available repository offers datasets for various tasks, including classification, regression, clustering, and more. Clustering : Datasets that involve grouping data into clusters without predefined labels. What is the UCI Machine Learning Repository?
Artificialintelligence (AI) adoption is accelerating across industries and use cases. Instead of downloading all the models to the endpoint instance, SageMaker dynamically loads and caches the models as they are invoked. Next, we download the Inception v3 model, extract it, and copy to the inception_graphdef model directory.
Jump Right To The Downloads Section Face Recognition with Siamese Networks, Keras, and TensorFlow Deep learning models tend to develop a bias toward the data distribution on which they have been trained. My mission is to change education and how complex ArtificialIntelligence topics are taught. Download the code!
For CSV, we still recommend splitting up large files into smaller ones to reduce data download time and enable quicker reads. The single-GPU training path still has some advantage in downloading and reading only part of the data in each instance, and therefore low data download time. However, it’s not a requirement. Tony Cruz
ClusteringClustering is a class of algorithms that segregates the data into a set of definite clusters such that similar points lie in the same cluster and dissimilar points lie in different clusters. Several clustering algorithms (e.g., means and spectral clustering) can be used in recommendation engines.
Download and install the Chrome browser extension For the best meeting streaming experience, install the LMA browser plugin (currently available for Chrome): Choose Download Chrome Extension to download the browser extension.zip file ( lma-chrome-extension.zip ). Enable Developer mode. This loads your extension.
Download the Amazon SageMaker FAQs When performing the search, look for Answers only, so you can drop the Question column. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering.
Feature Learning Autoencoders can learn meaningful features from input data, which can be used for downstream machine learning tasks like classification, clustering, or regression. My mission is to change education and how complex ArtificialIntelligence topics are taught. And that’s exactly what I do. Join the Newsletter!
This solution includes the following components: Amazon Titan Text Embeddings is a text embeddings model that converts natural language text, including single words, phrases, or even large documents, into numerical representations that can be used to power use cases such as search, personalization, and clustering based on semantic similarity.
Jump Right To The Downloads Section A Deep Dive into Variational Autoencoder with PyTorch Introduction Deep learning has achieved remarkable success in supervised tasks, especially in image recognition. Start by accessing this tutorial’s “Downloads” section to retrieve the source code and example images. And that’s exactly what I do.
Alternatively, you can directly download the Dockerfile.gpu from GitHub developed by ahmetoner , which includes a pre-configured RESTful API. His research interests are in the area of natural language processing, explainable deep learning on tabular data, and robust analysis of non-parametric space-time clustering.
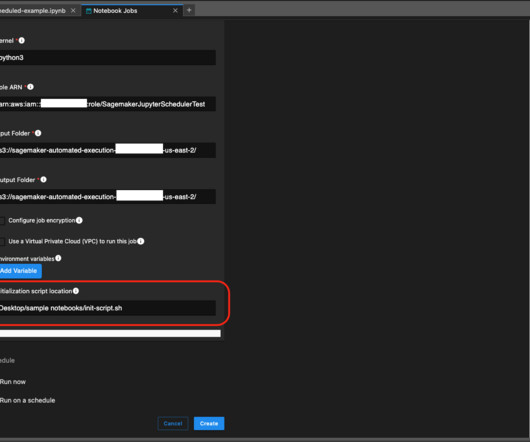
In addition to the IAM user and assumed role session scheduling the job, you also need to provide a role for the notebook job instance to assume for access to your data in Amazon Simple Storage Service (Amazon S3) or to connect to Amazon EMR clusters as needed. On the File menu, choose New and Notebook. pip install pandas !pip
In this post, we discuss how CCC Intelligent Solutions (CCC) combined Amazon SageMaker with other AWS services to create a custom solution capable of hosting the types of complex artificialintelligence (AI) models envisioned. The Lambda will download these previous predictions from Amazon S3.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content