This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Introduction Data science has taken over all economic sectors in recent times. To achieve maximum efficiency, every company strives to use various data at every stage of its operations.
With over 50 connectors, an intuitive Chat for data prep interface, and petabyte support, SageMaker Canvas provides a scalable, low-code/no-code (LCNC) ML solution for handling real-world, enterprise use cases. Organizations often struggle to extract meaningful insights and value from their ever-growing volume of data.
Generative artificialintelligence (gen AI) is transforming the business world by creating new opportunities for innovation, productivity and efficiency. Data Scientists will typically help with training, validating, and maintaining foundation models that are optimized for data tasks.
First, there’s a need for preparing the data, aka dataengineering basics. Machine learning practitioners are often working with data at the beginning and during the full stack of things, so they see a lot of workflow/pipeline development, data wrangling, and datapreparation.
Michael Dziedzic on Unsplash I am often asked by prospective clients to explain the artificialintelligence (AI) software process, and I have recently been asked by managers with extensive software development and data science experience who wanted to implement MLOps. Norvig, ArtificialIntelligence: A Modern Approach, 4th ed.
More than 170 tech teams used the latest cloud, machine learning and artificialintelligence technologies to build 33 solutions. This happens only when a new data format is detected to avoid overburdening scarce Afri-SET resources. Having a human-in-the-loop to validate each data transformation step is optional.
We will demonstrate an example feature engineering process on an e-commerce schema and how GraphReduce deals with the complexity of feature engineering on the relational schema. Datapreparation happens at the entity-level first so errors and anomalies don’t make their way into the aggregated dataset.
Instead, businesses tend to rely on advanced tools and strategies—namely artificialintelligence for IT operations (AIOps) and machine learning operations (MLOps)—to turn vast quantities of data into actionable insights that can improve IT decision-making and ultimately, the bottom line.
Created by the author with DALL E-3 Google Earth Engine for machine learning has just gotten a new face lift, with all the advancement that has been going on in the world of Artificialintelligence, Google Earth Engine was not going to be left behind as it is an important tool for spatial analysis.
Online analytical processing (OLAP) database systems and artificialintelligence (AI) complement each other and can help enhance data analysis and decision-making when used in tandem. IBM watsonx.data is the next generation OLAP system that can help you make the most of your data.
A recent PwC CEO survey unveiled that 84% of Canadian CEOs agree that artificialintelligence (AI) will significantly change their business within the next 5 years, making this technology more critical than ever. As such, an ML model is the product of an MLOps pipeline, and a pipeline is a workflow for creating one or more ML models.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificialintelligence (AI) to personalize experiences at scale. Additionally, Feast promotes feature reuse, so the time spent on datapreparation is reduced greatly.
Thus, MLOps is the intersection of Machine Learning, DevOps, and DataEngineering (Figure 1). Figure 4: The ModelOps process [Wikipedia] The Machine Learning Workflow Machine learning requires experimenting with a wide range of datasets, datapreparation, and algorithms to build a model that maximizes some target metric(s).
Being one of the largest AWS customers, Twilio engages with data and artificialintelligence and machine learning (AI/ML) services to run their daily workloads. Explore SageMaker Pipelines and open source data querying engines like PrestoDB, and build a solution using the sample implementation provided.
The vendors evaluated for this MarketScape offer various software tools needed to support end-to-end machine learning (ML) model development, including datapreparation, model building and training, model operation, evaluation, deployment, and monitoring.
The Evolving AI Development Lifecycle Despite the revolutionary capabilities of LLMs, the core development lifecycle established by traditional natural language processing remains essential: Plan, PrepareData, Engineer Model, Evaluate, Deploy, Operate, and Monitor. For instance: DataPreparation: GoogleSheets.
From datapreparation and model training to deployment and management, Vertex AI provides the tools and infrastructure needed to build intelligent applications. Unified ML Workflow: Vertex AI provides a simplified ML workflow, encompassing data ingestion, analysis, transformation, model training, evaluation, and deployment.
Building data literacy across your organization empowers teams to make better use of AI tools. It doesn’t seem like long ago that we thought of artificialintelligence (AI) as a futuristic concept—but today, it’s here in full swing, and organizations across sectors are working to integrate it into their core processes.
It supports all stages of ML development—from datapreparation to deployment, and allows you to launch a preconfigured JupyterLab IDE for efficient coding within seconds. Amazon ECR is a managed container registry that facilitates the storage, management, and deployment of container images.
Today’s data management and analytics products have infused artificialintelligence (AI) and machine learning (ML) algorithms into their core capabilities. These modern tools will auto-profile the data, detect joins and overlaps, and offer recommendations. DataRobot Data Prep. Sallam | Shubhangi Vashisth. .
Purina used artificialintelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The solution focuses on the fundamental principles of developing an AI/ML application workflow of datapreparation, model training, model evaluation, and model monitoring.
Harnessing the power of big data has become increasingly critical for businesses looking to gain a competitive edge. From deriving insights to powering generative artificialintelligence (AI) -driven applications, the ability to efficiently process and analyze large datasets is a vital capability.
Businesses face significant hurdles when preparingdata for artificialintelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage.
Data-centric AI, in his opinion, is based on the following principles: It’s time to focus on the data — after all the progress achieved in algorithms means it’s now time to spend more time on the data Inconsistent data labels are common since reasonable, well-trained people can see things differently.
Using the BMW data portal, users can request access to on-premises databases or data stored in BMW’s Cloud Data Hub, making it available in their workspace for development and experimentation, from datapreparation and analysis to model training and validation.
We use a test datapreparation notebook as part of this step, which is a dependency for the fine-tuning and batch inference step. When fine-tuning is complete, this notebook is run using run magic and prepares a test dataset for sample inference with the fine-tuned model.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities.
Youll gain immediate, practical skills in Python, datapreparation, machine learning modeling, and retrieval-augmented generation (RAG), all leading up to AI Agents. Each course features focused, interactive sessions with hands-on notebooks and exercises, along with dedicated office hours. Learn more about the AI Mini Bootcamphere.
Machine learning (ML), a subset of artificialintelligence (AI), is an important piece of data-driven innovation. Machine learning engineers take massive datasets and use statistical methods to create algorithms that are trained to find patterns and uncover key insights in data mining projects.
Artificialintelligence platforms enable individuals to create, evaluate, implement and update machine learning (ML) and deep learning models in a more scalable way. AI platform tools enable knowledge workers to analyze data, formulate predictions and execute tasks with greater speed and precision than they can manually.
Tools like Apache NiFi, Talend, and Informatica provide user-friendly interfaces for designing workflows, integrating diverse data sources, and executing ETL processes efficiently. Choosing the right tool based on the organisation’s specific needs, such as data volume and complexity, is vital for optimising ETL efficiency.
Introduction to Containers for Data Science / DataEngineering with Michael A. Fudge’s AI slides introduced participants to using containers in data science and engineering workflows. Steven Pousty showcased how to transform unstructured data into a vector-based query system. Fudge Slides Michael A.
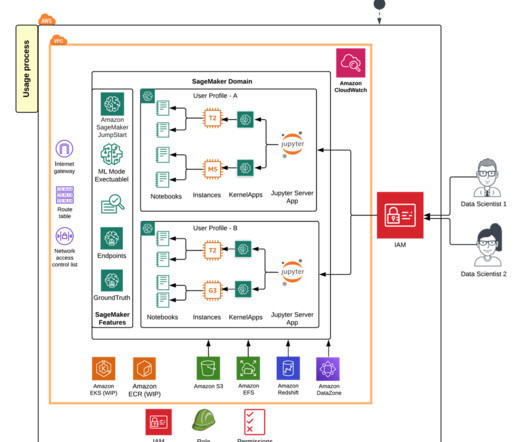
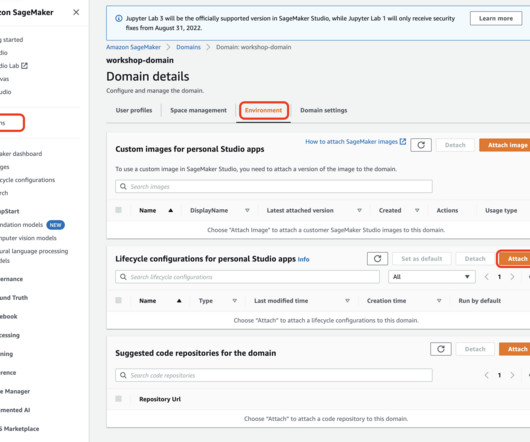
SageMaker Studio allows data scientists, ML engineers, and dataengineers to preparedata, build, train, and deploy ML models on one web interface. Key concepts Amazon SageMaker Studio is a web-based, integrated development environment (IDE) for machine learning.
This includes gathering, exploring, and understanding the business and technical aspects of the data, along with evaluation of any manipulations that may be needed for the model building process. One aspect of this datapreparation is feature engineering.
Studio provides all the tools you need to take your models from datapreparation to experimentation to production while boosting your productivity. He develops and codes cloud native solutions with a focus on big data, analytics, and dataengineering.
[link] Ahmad Khan, head of artificialintelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022.
[link] Ahmad Khan, head of artificialintelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022.
For a comprehensive understanding of the practical applications, including a detailed code walkthrough from datapreparation to model deployment, please join us at the ODSC APAC conference 2023. Now, let’s give you a taste of what’s in store (the GitHub code repository can be found here ). if the recipe is a dessert, 0.0
We also examined the results to gain a deeper understanding of why these prompt engineering skills and platforms are in demand for the role of Prompt Engineer, not to mention machine learning and data science roles. For prompt engineers, it can be used for the deployment and orchestration of LLM applications.
DataPreparation: Cleaning, transforming, and preparingdata for analysis and modelling. Collaborating with Teams: Working with dataengineers, analysts, and stakeholders to ensure data solutions meet business needs.
Below, we explore five popular data transformation tools, providing an overview of their features, use cases, strengths, and limitations. Apache Nifi Apache Nifi is an open-source data integration tool that automates system data flow.
Generative artificialintelligence (AI) applications built around large language models (LLMs) have demonstrated the potential to create and accelerate economic value for businesses. She holds an engineering degree from Thapar University, as well as a master’s degree in statistics from Texas A&M University.
With the integration of SageMaker and Amazon DataZone, it enables collaboration between ML builders and dataengineers for building ML use cases. ML builders can request access to data published by dataengineers. Additionally, this solution uses Amazon DataZone.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content