This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machine learning and artificialintelligence, which are at the top of the list of data science capabilities, aren’t just buzzwords; many companies are keen to implement them. Prior to developing intelligentdata products, however, the frequently overlooked core work required to make it happen, […].
Amazon Redshift powers data-driven decisions for tens of thousands of customers every day with a fully managed, AI-powered cloud datawarehouse, delivering the best price-performance for your analytics workloads. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
OMRONs data strategyrepresented on ODAPalso allowed the organization to unlock generative AI use cases focused on tangible business outcomes and enhanced productivity. When needed, the system can access an ODAP datawarehouse to retrieve additional information.
ELT advocates for loading raw data directly into storage systems, often cloud-based, before transforming it as necessary. This shift leverages the capabilities of modern datawarehouses, enabling faster data ingestion and reducing the complexities associated with traditional transformation-heavy ETL processes.
Dataengineering is a hot topic in the AI industry right now. And as data’s complexity and volume grow, its importance across industries will only become more noticeable. But what exactly do dataengineers do? So let’s do a quick overview of the job of dataengineer, and maybe you might find a new interest.
Dataengineering in healthcare is taking a giant leap forward with rapid industrial development. ArtificialIntelligence (AI) and Machine Learning (ML) are buzzwords these days with developments of Chat-GPT, Bard, and Bing AI, among others. Thus, using dataengineering is a must in 2023 for hospitals.
We also made the case that query and reporting, provided by big dataengines such as Presto, need to work with the Spark infrastructure framework to support advanced analytics and complex enterprise data decision-making. To do so, Presto and Spark need to readily work with existing and modern datawarehouse infrastructures.
der Aufbau einer Datenplattform, vielleicht ein DataWarehouse zur Datenkonsolidierung, Process Mining zur Prozessanalyse oder Predictive Analytics für den Aufbau eines bestimmten Vorhersagesystems, KI zur Anomalieerkennung oder je nach Ziel etwas ganz anderes. Es gibt aber viele junge Leute, die da gerne einsteigen wollen.
Dataengineering has become an integral part of the modern tech landscape, driving advancements and efficiencies across industries. So let’s explore the world of open-source tools for dataengineers, shedding light on how these resources are shaping the future of data handling, processing, and visualization.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
We couldn’t be more excited to announce the first sessions for our second annual DataEngineering Summit , co-located with ODSC East this April. Join us for 2 days of talks and panels from leading experts and dataengineering pioneers. Is Gen AI A DataEngineering or Software Engineering Problem?
By automating the integration of all Fabric workloads into OneLake, Microsoft eliminates the need for developers, analysts, and business users to create their own data silos. This approach not only improves performance by eliminating the need for separate datawarehouses but also results in substantial cost savings for customers.
Data is the differentiator as business leaders look to utilize their competitive edge as they implement generative AI (gen AI). Leaders feel the pressure to infuse their processes with artificialintelligence (AI) and are looking for ways to harness the insights in their data platforms to fuel this movement.
Artificialintelligence (AI) adoption is still in its early stages. The Stanford Institute for Human-Centered ArtificialIntelligence’s Center for Research on Foundation Models (CRFM) recently outlined the many risks of foundation models, as well as opportunities. Trustworthiness is critical.
In this episode, James Serra, author of “Deciphering Data Architectures: Choosing Between a Modern DataWarehouse, Data Fabric, Data Lakehouse, and Data Mesh” joins us to discuss his book and dive into the current state and possible future of data architectures.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificialintelligence (AI) to personalize experiences at scale. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
Introduction ETL plays a crucial role in Data Management. This process enables organisations to gather data from various sources, transform it into a usable format, and load it into datawarehouses or databases for analysis. Loading The transformed data is loaded into the target destination, such as a datawarehouse.
The modern data stack is a combination of various software tools used to collect, process, and store data on a well-integrated cloud-based data platform. It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A datawarehouse.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machine learning models and develop artificialintelligence (AI) applications.
Online analytical processing (OLAP) database systems and artificialintelligence (AI) complement each other and can help enhance data analysis and decision-making when used in tandem. Today, OLAP database systems have become comprehensive and integrated data analytics platforms, addressing the diverse needs of modern businesses.
Jeff Newburn is a Senior Software Engineering Manager leading the DataEngineering team at Logikcull – A Reveal Technology. He oversees the company’s data initiatives, including datawarehouses, visualizations, analytics, and machine learning. Outside of work, he enjoys playing lawn tennis and reading books.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities.
Artificialintelligence is disrupting many different areas of business. Powering a knowledge management system with a data lakehouse Organizations need a data lakehouse to target data challenges that come with deploying an AI-powered knowledge management system. A data lakehouse is a fit-for-purpose data store.
With the birth of cloud datawarehouses, data applications, and generative AI , processing large volumes of data faster and cheaper is more approachable and desired than ever. First up, let’s dive into the foundation of every Modern Data Stack, a cloud-based datawarehouse.
Data has to be stored somewhere. Datawarehouses are repositories for your cleaned, processed data, but what about all that unstructured data your organization is starting to notice? What is a data lake? Snowflake Snowflake is a cross-cloud platform that looks to break down data silos.
Well according to Brij Kishore Pandey, it stands for Extract, Transform, Load and is a fundamental process in dataengineering, ensuring data moves efficiently from raw sources to structured storage for analysis. The stepsinclude: Extraction : Data is collected from multiple sources (databases, APIs, flatfiles).
This makes it easier to compare and contrast information and provides organizations with a unified view of their data. Machine Learning Data pipelines feed all the necessary data into machine learning algorithms, thereby making this branch of ArtificialIntelligence (AI) possible.
There you’ll hear from Ivan Nardini, Developer Relations Engineer at Google Cloud and discover the latest advancements in AI and learn how to leverage Google Cloud’s powerful tools and infrastructure to drive innovation in your organization.
Using Amazon Redshift ML for anomaly detection Amazon Redshift ML makes it easy to create, train, and apply machine learning models using familiar SQL commands in Amazon Redshift datawarehouses. To learn more, see the documentation.
Data science solves a business problem by understanding the problem, knowing the data that’s required, and analyzing the data to help solve the real-world problem. Machine learning (ML) is a subset of artificialintelligence (AI) that focuses on learning from what the data science comes up with.
Businesses face significant hurdles when preparing data for artificialintelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage.
Inconsistent data quality: The uncertainty surrounding the accuracy, consistency and reliability of data pulled from various sources can lead to risks in analysis and reporting. These products are curated with key attributes such as business domain, access level, delivery methods, recommended usage and data contracts.
ODSC Highlights Announcing the Keynote and Featured Speakers for ODSC East 2024 The keynotes and featured speakers for ODSC East 2024 have won numerous awards, authored books and widely cited papers, and shaped the future of data science and AI with their research. Learn more about them here!
This makes it easier to compare and contrast information and provides organizations with a unified view of their data. Machine Learning Data pipelines feed all the necessary data into machine learning algorithms, thereby making this branch of ArtificialIntelligence (AI) possible.
[link] Ahmad Khan, head of artificialintelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022.
[link] Ahmad Khan, head of artificialintelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022.
Data Preparation: Cleaning, transforming, and preparing data for analysis and modelling. Collaborating with Teams: Working with dataengineers, analysts, and stakeholders to ensure data solutions meet business needs.
It enables efficient active learning by iteratively selecting the most valuable data points for labeling, reducing manual effort while improving model performance. This LabelBox LabelBox is an AI-powered dataengine platform that supports text annotation along with other data types.
It enables efficient active learning by iteratively selecting the most valuable data points for labeling, reducing manual effort while improving model performance. This LabelBox LabelBox is an AI-powered dataengine platform that supports text annotation along with other data types.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































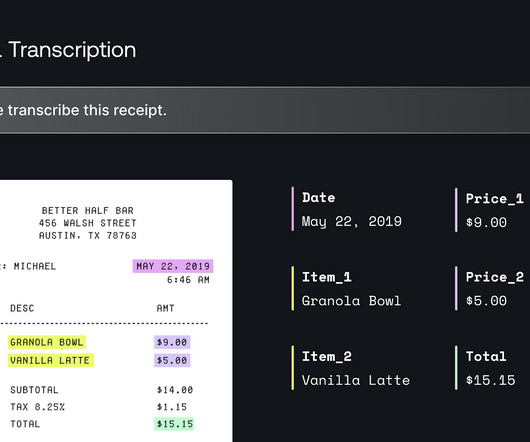
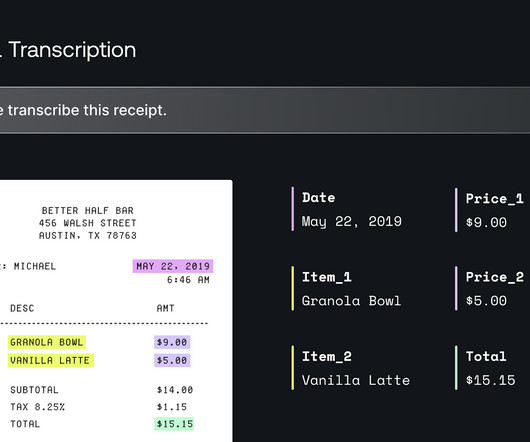






Let's personalize your content