This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
The acronym ETL—Extract, Transform, Load—has long been the linchpin of modern data management, orchestrating the movement and manipulation of data across systems and databases. This methodology has been pivotal in data warehousing, setting the stage for analysis and informed decision-making.
Learn the basics of dataengineering to improve your ML modelsPhoto by Mike Benna on Unsplash It is not news that developing Machine Learning algorithms requires data, often a lot of data. Collecting this data is not trivial, in fact, it is one of the most relevant and difficult parts of the entire workflow.
Two of the more popular methods, extract, transform, load (ETL ) and extract, load, transform (ELT) , are both highly performant and scalable. Dataengineers build data pipelines, which are called data integration tasks or jobs, as incremental steps to perform data operations and orchestrate these data pipelines in an overall workflow.
He highlights innovations in data, infrastructure, and artificialintelligence and machine learning that are helping AWS customers achieve their goals faster, mine untapped potential, and create a better future. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
Summary: This article explores the significance of ETLData in Data Management. It highlights key components of the ETL process, best practices for efficiency, and future trends like AI integration and real-time processing, ensuring organisations can leverage their data effectively for strategic decision-making.
In the world of AI-driven data workflows, Brij Kishore Pandey, a Principal Engineer at ADP and a respected LinkedIn influencer, is at the forefront of integrating multi-agent systems with Generative AI for ETL pipeline orchestration. ETL ProcessBasics So what exactly is ETL? What is an Agent?
It is used by businesses across industries for a wide range of applications, including fraud prevention, marketing automation, customer service, artificialintelligence (AI), chatbots, virtual assistants, and recommendations. we have Databricks which is an open-source, next-generation data management platform.
Dataengineering is a rapidly growing field, and there is a high demand for skilled dataengineers. If you are a data scientist, you may be wondering if you can transition into dataengineering. In this blog post, we will discuss how you can become a dataengineer if you are a data scientist.
Unfolding the difference between dataengineer, data scientist, and data analyst. Dataengineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Read more to know.
Getting Started with AI in High-Risk Industries, How to Become a DataEngineer, and Query-Driven Data Modeling How To Get Started With Building AI in High-Risk Industries This guide will get you started building AI in your organization with ease, axing unnecessary jargon and fluff, so you can start today.
DataEngineering : Building and maintaining data pipelines, ETL (Extract, Transform, Load) processes, and data warehousing. ArtificialIntelligence : Concepts of AI include neural networks, natural language processing (NLP), and reinforcement learning.
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines. He specializes in designing, building, and optimizing large-scale data solutions.
Team Building the right data science team is complex. With a range of role types available, how do you find the perfect balance of Data Scientists , DataEngineers and Data Analysts to include in your team? The DataEngineer Not everyone working on a data science project is a data scientist.
Data is the differentiator as business leaders look to utilize their competitive edge as they implement generative AI (gen AI). Leaders feel the pressure to infuse their processes with artificialintelligence (AI) and are looking for ways to harness the insights in their data platforms to fuel this movement.
More than 170 tech teams used the latest cloud, machine learning and artificialintelligence technologies to build 33 solutions. LLMs excel at writing code and reasoning over text, but tend to not perform as well when interacting directly with time-series data.
The solution consists of the following components: Data ingestion: Data is ingested into the data account from on-premises and external sources. Data access: Refined data is registered in the data accounts AWS Glue Data Catalog and exposed to other accounts via Lake Formation.
After understanding data science let’s discuss the second concern “ Data Science vs AI ”. So, we know that data science is a process of getting insights from data and helps the business but where this ArtificialIntelligence (AI) lies?
Businesses face significant hurdles when preparing data for artificialintelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage.
IBM’s data lineage solution for banking regulatory compliance For helping clients take advantage of data lineage, we recommend IBM Cloud Pak for Data for several reasons.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificialintelligence (AI) to personalize experiences at scale. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
From speech recognition breakthroughs to large-scale language models, the story of AI is fundamentally a story of data. The Scaling Hypothesis: Bigger Data, Better AI? Ill say it again the story of artificialintelligence over the past decade is fundamentally a story about data.
It is known to have benefits in handling data due to its robustness, speed, and scalability. A typical modern data stack consists of the following: A data warehouse. Data ingestion/integration services. Reverse ETL tools. Data orchestration tools. Business intelligence (BI) platforms. Data scientists.
Set specific, measurable targets Data science goals to “increase sales” lack the clarity needed to evaluate success and secure ongoing funding. Audit existing data assets Inventory internal datasets, ETL capabilities, past analytical initiatives, and available skill sets.
With ML-powered anomaly detection, customers can find outliers in their data without the need for manual analysis, custom development, or ML domain expertise. Using Amazon Glue Data Quality for anomaly detection Dataengineers and analysts can use AWS Glue Data Quality to measure and monitor their data.
For instance, a notebook that monitors for model data drift should have a pre-step that allows extract, transform, and load (ETL) and processing of new data and a post-step of model refresh and training in case a significant drift is noticed. About the authors Anchit Gupta is a Senior Product Manager for Amazon SageMaker Studio.
ODSC Highlights Announcing the Keynote and Featured Speakers for ODSC East 2024 The keynotes and featured speakers for ODSC East 2024 have won numerous awards, authored books and widely cited papers, and shaped the future of data science and AI with their research. Learn more about them here!
Artificialintelligence (AI) and machine learning (ML) offerings from Amazon Web Services (AWS) , along with integrated monitoring and notification services, help organizations achieve the required level of automation, scalability, and model quality at optimal cost.
Skills like effective verbal and written communication will help back up the numbers, while data visualization (specific frameworks in the next section) can help you tell a complete story. Data Wrangling: Data Quality, ETL, Databases, Big Data The modern data analyst is expected to be able to source and retrieve their own data for analysis.
This makes it easier to compare and contrast information and provides organizations with a unified view of their data. Machine Learning Data pipelines feed all the necessary data into machine learning algorithms, thereby making this branch of ArtificialIntelligence (AI) possible.
Within watsonx.ai, users can take advantage of open-source frameworks like PyTorch, TensorFlow and scikit-learn alongside IBM’s entire machine learning and data science toolkit and its ecosystem tools for code-based and visual data science capabilities.
With an estimated market share of 30.03% , Microsoft Fabric is a preferred choice for businesses seeking efficient and scalable data solutions. Definition and Core Components Microsoft Fabric is a unified solution integrating various data services into a single ecosystem. Power BI : Provides dynamic dashboards and reporting tools.
Below, we explore five popular data transformation tools, providing an overview of their features, use cases, strengths, and limitations. Apache Nifi Apache Nifi is an open-source data integration tool that automates system data flow. AWS Glue AWS Glue is a fully managed ETL service provided by Amazon Web Services.
The most critical and impactful step you can take towards enterprise AI today is ensuring you have a solid data foundation built on the modern data stack with mature operational pipelines, including all your most critical operational data. This often involves software engineering, dataengineering, and system design skills.
Efficient Incremental Processing with Apache Iceberg and Netflix Maestro Dimensional Data Modeling in the Modern Era Building Big Data Workflows: NiFi, Hive, Trino, & Zeppelin An Introduction to Data Contracts From Data Mess to Data Mesh — Data Management in the Age of Big Data and Gen AI Introduction to Containers for Data Science / DataEngineering (..)
This makes it easier to compare and contrast information and provides organizations with a unified view of their data. Machine Learning Data pipelines feed all the necessary data into machine learning algorithms, thereby making this branch of ArtificialIntelligence (AI) possible.
Slow Response to New Information: Legacy data systems often lack the computation power necessary to run efficiently and can be cost-inefficient to scale. This typically results in long-running ETL pipelines that cause decisions to be made on stale or old data.
These conveniently combine key capabilities into unified services that facilitate the end-to-end lifecycle: Anaconda provides a local development environment bundling 700+ Python data packages. It enables accessing, transforming, analyzing, and visualizing data on a single workstation.
30% Off ODSC East, Fan-Favorite Speakers, Foundation Models for Times Series, and ETL Pipeline Orchestration The ODSC East 2025 Schedule isLIVE! Explore the must-attend sessions and cutting-edge tracks designed to equip AI practitioners, data scientists, and engineers with the latest advancements in AI and machine learning.
The explosion of generative AI and LLMs has redefined how businesses and developers interact with artificialintelligence. DataEngineerings SteadyGrowth 20182021: Dataengineering was often mentioned but overshadowed by modeling advancements.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










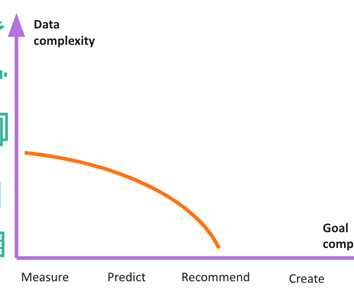



































Let's personalize your content