This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Be sure to check out his talk, “ Apache Kafka for Real-Time Machine Learning Without a DataLake ,” there! The combination of data streaming and machine learning (ML) enables you to build one scalable, reliable, but also simple infrastructure for all machine learning tasks using the Apache Kafka ecosystem.
While databases were the traditional way to store large amounts of data, a new storage method has developed that can store even more significant and varied amounts of data. These are called datalakes. What Are DataLakes? However, even digital information has to be stored somewhere.
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As datalakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.
ArtificialIntelligence (AI) is all the rage, and rightly so. This is of course an over-simplification of the data warehousing journey, but as data warehousing has moved to the cloud and business intelligence has evolved into powerful analytics and visualization platforms the foundational best practices shared here still apply today.
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
Businesses face significant hurdles when preparing data for artificialintelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage.
Generative AI models have the potential to revolutionize enterprise operations, but businesses must carefully consider how to harness their power while overcoming challenges such as safeguarding data and ensuring the quality of AI-generated content. Set up the database access and network access.
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. The datalake can then refine, enrich, index, and analyze that data. and various countries in Europe.
Be sure to check out her talk, “ Don’t Go Over the Deep End: Building an Effective OSS Management Layer for Your DataLake ,” there! Managing a datalake can often feel like being lost at sea — especially when dealing with both structured and unstructured data.
Data warehouse is the base architecture for artificialintelligence and machine learning (AI/ML) solutions as well. Benefits of new data warehousing technology Everything is data, regardless of whether it’s structured, semi-structured, or unstructured.
As one of the largest AWS customers, Twilio engages with data, artificialintelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications. The following diagram illustrates the solution architecture.
Be sure to check out his talk, “ What is a Time-series Database and Why do I Need One? Most data scientists are familiar with the concept of time series data and work with it often. The time series database (TSDB) , however, is still an underutilized tool in the data science community. at ODSC West 2023.
Data storage databases. Your SaaS company can store and protect any amount of data using Amazon Simple Storage Service (S3), which is ideal for datalakes, cloud-native applications, and mobile apps. Artificialintelligence (AI). Well, let’s find out. Cost-effective.
Their contributions to AI and data science communities make it easier to integrate cutting-edge analytics into business strategies. Google CloudOpen-Source Database Solutions Google Cloud offers an array of open-source database solutions, from MySQL and PostgreSQL to Spanner.
The Future of the Single Source of Truth is an Open DataLake Organizations that strive for high-performance data systems are increasingly turning towards the ELT (Extract, Load, Transform) model using an open datalake. To DIY you need to: host an API, build a UI, and run or rent a database.
Comprehensive data privacy laws in at least four states are going into effect this year, and more than a dozen states have similar legislation in the works. Database management may become increasingly complex as organizations must account for more of these laws.
By moving our core infrastructure to Amazon Q, we no longer needed to choose a large language model (LLM) and optimize our use of it, manage Amazon Bedrock agents, a vector database and semantic search implementation, or custom pipelines for data ingestion and management.
Data Collection and Integration Data engineers are responsible for designing robust data collection systems that gather information from various IoT devices and sensors. This data is then integrated into centralized databases for further processing and analysis.
There are several choices to consider, each with its own set of advantages and disadvantages: Data warehouses are used to store data that has been processed for a specific function from one or more sources. Datalakes hold raw data that has not yet been altered to meet a specific purpose.
Data fabrics are gaining momentum as the data management design for today’s challenging data ecosystems. At their most basic level, data fabrics leverage artificialintelligence and machine learning to unify and securely manage disparate data sources without migrating them to a centralized location.
Data fabrics are gaining momentum as the data management design for today’s challenging data ecosystems. At their most basic level, data fabrics leverage artificialintelligence and machine learning to unify and securely manage disparate data sources without migrating them to a centralized location.
Our goal was to improve the user experience of an existing application used to explore the counters and insights data. The data is stored in a datalake and retrieved by SQL using Amazon Athena. The problem Making data accessible to users through applications has always been a challenge.
During the embeddings experiment, the dataset was converted into embeddings, stored in a vector database, and then matched with the embeddings of the question to extract context. The generated query is then run against the database to fetch the relevant context. Based on the initial tests, this method showed great results.
Amazon DataZone is a data management service that makes it quick and convenient to catalog, discover, share, and govern data stored in AWS, on-premises, and third-party sources. The sample dataset Upload the dataset to Amazon S3 and crawl the data to create an AWS Glue database and tables.
Why it’s challenging to process and manage unstructured data Unstructured data makes up a large proportion of the data in the enterprise that can’t be stored in a traditional relational database management systems (RDBMS). These services write the output to a datalake.
More than 170 tech teams used the latest cloud, machine learning and artificialintelligence technologies to build 33 solutions. The fundamental objective is to build a manufacturer-agnostic database, leveraging generative AI’s ability to standardize sensor outputs, synchronize data, and facilitate precise corrections.
The combination of large language models (LLMs), including the ease of integration that Amazon Bedrock offers, and a scalable, domain-oriented data infrastructure positions this as an intelligent method of tapping into the abundant information held in various analytics databases and datalakes.
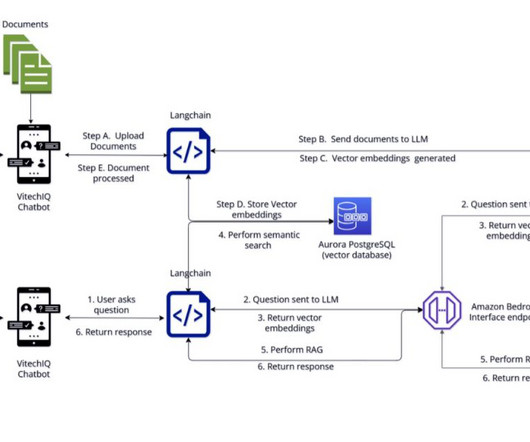
Additionally, VitechIQ includes metadata from the vector database (for example, document URLs) in the model’s output, providing users with source attribution and enhancing trust in the generated answers. These vector embeddings are stored in an Aurora PostgreSQL database. The following diagram shows the solution architecture.
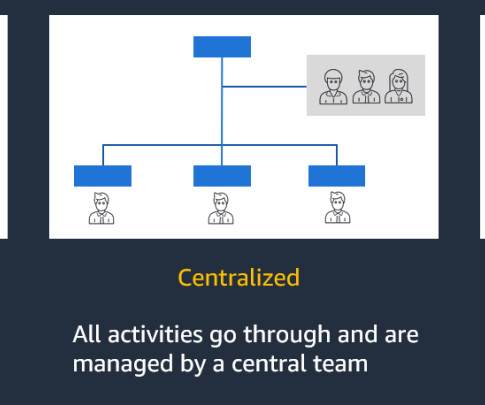
However, even in a decentralized model, often LOBs must align with central governance controls and obtain approvals from the CCoE team for production deployment, adhering to global enterprise standards for areas such as access policies, model risk management, data privacy, and compliance posture, which can introduce governance complexities.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
Online analytical processing (OLAP) database systems and artificialintelligence (AI) complement each other and can help enhance data analysis and decision-making when used in tandem. Defining OLAP today OLAP database systems have significantly evolved since their inception in the early 1990s.
There are many well-known libraries and platforms for data analysis such as Pandas and Tableau, in addition to analytical databases like ClickHouse, MariaDB, Apache Druid, Apache Pinot, Google BigQuery, Amazon RedShift, etc. With Great Expectations , data teams can express what they “expect” from their data using simple assertions.
In this post, we will explore the potential of using MongoDB’s time series data and SageMaker Canvas as a comprehensive solution. MongoDB Atlas MongoDB Atlas is a fully managed developer data platform that simplifies the deployment and scaling of MongoDB databases in the cloud. Setup the Database access and Network access.
In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different data platform solution. Hence, DataLake emerged, which handles unstructured and structured data with huge volume. A data fabric is comprised of a network of data nodes (e.g.,
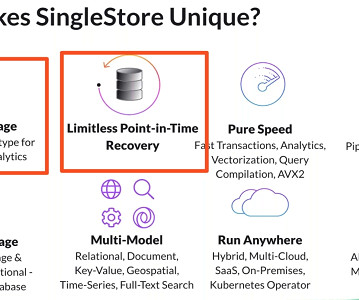
Real-time Analytics & Built-in Machine Learning Models with a Single Database Akmal Chaudhri, Senior Technical Evangelist at SingleStore, explores the importance of delivering real-time experiences in today’s big data industry and how data models and algorithms rely on powerful and versatile data infrastructure.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machine learning models and develop artificialintelligence (AI) applications.
To accomplish this, eSentire built AI Investigator, a natural language query tool for their customers to access security platform data by using AWS generative artificialintelligence (AI) capabilities. eSentire has over 2 TB of signal data stored in their Amazon Simple Storage Service (Amazon S3) datalake.
As organisations grapple with this vast amount of information, understanding the main components of Big Data becomes essential for leveraging its potential effectively. Key Takeaways Big Data originates from diverse sources, including IoT and social media. Datalakes and cloud storage provide scalable solutions for large datasets.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. The solution in this post aims to bring enterprise analytics operations to the next level by shortening the path to your data using natural language. This table is used for finding the correct table, database, and attributes.
This means that individuals can ask companies to erase their personal data from their systems and from the systems of any third parties with whom the data was shared. For Vector database , choose Quick create a new vector store – Recommended to set up an OpenSearch Serverless vector store on your behalf. Choose Next.
JuMa is tightly integrated with a range of BMW Central IT services, including identity and access management, roles and rights management, BMW Cloud Data Hub (BMW’s datalake on AWS) and on-premises databases.
It’s the critical process of capturing, transforming, and loading data into a centralised repository where it can be processed, analysed, and leveraged. Data Ingestion Meaning At its core, It refers to the act of absorbing data from multiple sources and transporting it to a destination, such as a database, data warehouse, or datalake.
With the recently launched Amazon Monitron Kinesis data export v2 feature , your OT team can stream incoming measurement data and inference results from Amazon Monitron via Amazon Kinesis to AWS Simple Storage Service (Amazon S3) to build an Internet of Things (IoT) datalake. Choose Next.
This allows the Masters to scale analytics and AI wherever their data resides, through open formats and integration with existing databases and tools. “Hole distances and pin positions vary from round to round and year to year; these factors are important as we stage the data.”
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















































Let's personalize your content