This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
As one of the largest AWS customers, Twilio engages with data, artificialintelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications.
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As datalakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.
Our goal was to improve the user experience of an existing application used to explore the counters and insights data. The data is stored in a datalake and retrieved by SQL using Amazon Athena. The following figure shows a search query that was translated to SQL and run. The challenge is to assure quality.
DataLakes have been around for well over a decade now, supporting the analytic operations of some of the largest world corporations. Such data volumes are not easy to move, migrate or modernize. The challenges of a monolithic datalake architecture Datalakes are, at a high level, single repositories of data at scale.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Today, generative AI can enable people without SQL knowledge. This generative AI task is called text-to-SQL, which generates SQL queries from natural language processing (NLP) and converts text into semantically correct SQL.
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP. Additionally, Amazon Simple Storage Service (Amazon S3) served as the central datalake, providing a scalable and cost-effective storage solution for the diverse data types collected from different systems.
Azure Synapse Analytics This is the future of data warehousing. It combines data warehousing and datalakes into a simple query interface for a simple and fast analytics service. SQL Server 2019 SQL Server 2019 went Generally Available. Amazon Web Services.
He highlights innovations in data, infrastructure, and artificialintelligence and machine learning that are helping AWS customers achieve their goals faster, mine untapped potential, and create a better future. Learn more about the AWS zero-ETL future with newly launched AWS databases integrations with Amazon Redshift.
Data management problems can also lead to data silos; disparate collections of databases that don’t communicate with each other, leading to flawed analysis based on incomplete or incorrect datasets. One way to address this is to implement a datalake: a large and complex database of diverse datasets all stored in their original format.
In this post, we discuss a Q&A bot use case that Q4 has implemented, the challenges that numerical and structured datasets presented, and how Q4 concluded that using SQL may be a viable solution. RAG with semantic search – Conventional RAG with semantic search was the last step before moving to SQL generation.
Be sure to check out her talk, “ Don’t Go Over the Deep End: Building an Effective OSS Management Layer for Your DataLake ,” there! Managing a datalake can often feel like being lost at sea — especially when dealing with both structured and unstructured data.
By running reports on historical data, a data warehouse can clarify what systems and processes are working and what methods need improvement. Data warehouse is the base architecture for artificialintelligence and machine learning (AI/ML) solutions as well.
Specifically, we cover the computer vision and artificialintelligence (AI) techniques used to combine datasets into a list of prioritized tasks for field teams to investigate and mitigate. The resulting dashboard highlighted that 141 power pole assets required action, out of a network of 57,230 poles.
With an Amazon Q custom plugin that uses an internal library used for natural language to SQL (NL2SQL), the same that powers generative SQL capabilities across some AWS database services like Amazon Redshift, we will provide the ability to aggregate and slice-and-dice the opportunity pipeline and trends in product consumption conversationally.
Although setting up a database to run your analyses may seem like an arduous task, modern open-source time series databases can provide significant benefits to any scientist running time series analysis on a large data set — and with much less effort than you might imagine.
Every day, millions of riders use the Uber app, unwittingly contributing to a complex web of data-driven decisions. This blog takes you on a journey into the world of Uber’s analytics and the critical role that Presto, the open source SQL query engine, plays in driving their success. What is Presto?
The natural language capabilities allow non-technical users to query data through conversational English rather than complex SQL. The AI and language models must identify the appropriate data sources, generate effective SQL queries, and produce coherent responses with embedded results at scale.
Choosing a DataLake Format: What to Actually Look For The differences between many datalake products today might not matter as much as you think. When choosing a datalake, here’s something else to consider. When choosing a datalake, here’s something else to consider.
[link] Ahmad Khan, head of artificialintelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
[link] Ahmad Khan, head of artificialintelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks. Apache Hive was used to provide a tabular interface to data stored in HDFS, and to integrate with Apache Spark SQL. This also led to a backlog of data that needed to be ingested.
Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their datalake to derive valuable insights from the data.
Computer Science and Computer Engineering Similar to knowing statistics and math, a data scientist should know the fundamentals of computer science as well. While knowing Python, R, and SQL are expected, you’ll need to go beyond that. Big Data As datasets become larger and more complex, knowing how to work with them will be key.
With Great Expectations , data teams can express what they “expect” from their data using simple assertions. Great Expectations provides support for different data backends such as flat file formats, SQL databases, Pandas dataframes and Sparks, and comes with built-in notification and data documentation functionality.
It’s distributed both in the cloud and on-premises, allowing extensive use and movement across clouds, apps and networks, as well as stores of data at rest. An architecture designed for data democratization aims to be flexible, integrated, agile and secure to enable the use of data and artificialintelligence (AI) at scale.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machine learning models and develop artificialintelligence (AI) applications.
In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different data platform solution. Hence, DataLake emerged, which handles unstructured and structured data with huge volume. All phases of the data-information lifecycle.
Start Learning AI With the ODSC West Data Primer Series In this six-part series as part of the ODSC West mini-bootcamp, you’ll learn everything you need to know to get started with AI, including SQL, machine learning, and even LLMs. In addition, we’ll discuss a variety of tools that form the modern LLM application development stack.
5 Reasons Why SQL is Still the Most Accessible Language for New Data Scientists Between its ability to perform data analysis and ease-of-use, here are 5 reasons why SQL is still ideal for new data scientists to get into the field. Check a few of them out here.
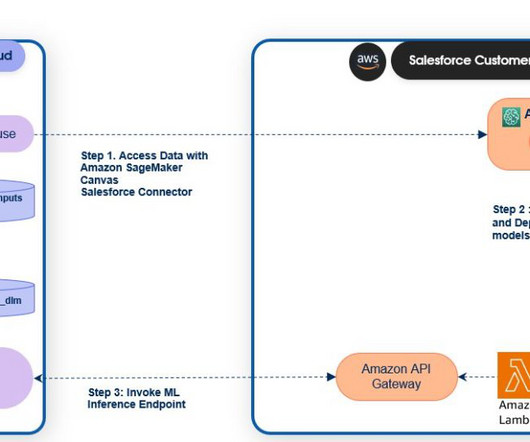
Configure the following scopes on your connected app: Manage user data via APIs ( api ). Perform ANSI SQL queries on Salesforce Data Cloud data (Data Cloud_query_api ). Manage Data Cloud profile data ( Data Cloud_profile_api ). Drag and drop the file, then choose Edit in SQL.
This means that individuals can ask companies to erase their personal data from their systems and from the systems of any third parties with whom the data was shared. Select the uploaded file and from Actions dropdown and choose the Query with S3 Select option to query the.csv data using SQL if the data was loaded correctly.
A simple model to control access to data via a UI or SQL. Automatically tracking data lineage across queries executed in any language. To ensure you can deliver on this world-changing vision of data, Alation helps you maximize the value of your datalake with integrations to the Unity catalog. and much more!
With the recently launched Amazon Monitron Kinesis data export v2 feature , your OT team can stream incoming measurement data and inference results from Amazon Monitron via Amazon Kinesis to AWS Simple Storage Service (Amazon S3) to build an Internet of Things (IoT) datalake. The latest version of Firefox or Chrome.
Data analysts often must go out and find their data, process it, clean it, and get it ready for analysis. This pushes into Big Data as well, as many companies now have significant amounts of data and large datalakes that need analyzing. Cloud Services: Google Cloud Platform, AWS, Azure.
Amazon Bedrock , a fully managed service designed to facilitate the integration of LLMs into enterprise applications, offers a choice of high-performing LLMs from leading artificialintelligence (AI) companies like Anthropic, Mistral AI, Meta, and Amazon through a single API. The Step Functions workflow starts.
Watsonx.data is built on 3 core integrated components: multiple query engines, a catalog that keeps track of metadata, and storage and relational data sources which the query engines directly access.
IBM watsonx.data is a hybrid, governed datalake house optimized for data, analytics and AI workloads. Additionally, watsonx.data provides a flexible approach and a unified view of your data across hybrid cloud environments. Key highlights include driving business analytics with engines like Presto and Spark.
and IBM AIOps (artificialintelligence for IT operations) solutions to plan, design and execute end-to-end migration and modernization journey. Generative AI-powered discovery as a service : Helps extracting key data elements from client data repositories and fast-track the application discovery process.
To cluster the data we have to calculate distances between IPs — The number of all possible IP pairs is very large, and we had to solve the scale problem. Data Processing and Clustering Our data is stored in a DataLake and we used PrestoDB as a query engine. AS ip_1, r.ip AND l.ip < r.ip
Businesses face significant hurdles when preparing data for artificialintelligence (AI) applications. The existence of data silos and duplication, alongside apprehensions regarding data quality, presents a multifaceted environment for organizations to manage.
We had bigger sessions on getting started with machine learning or SQL, up to advanced topics in NLP, and how to make deepfakes. Here are some highlights from ODSC Europe 2023, including some pictures of speakers and attendees, popular talks, and a summary of what kept people busy.
Power BI Datamarts provide no-code/low-code datamart capabilities using Azure SQL Database technology in the background. The Power BI Datamarts support sensitivity labels, endorsement, discovery, and Row-Level Security ( RLS ), which help protect and manage the data according to the business requirements and compliance needs.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content